-[Training for Mandarin Language](#training-for-mandarin-language)
-[Training for Mandarin Language](#training-for-mandarin-language)
-[Trying Live Demo with Your Own Voice](#trying-live-demo-with-your-own-voice)
-[Trying Live Demo with Your Own Voice](#trying-live-demo-with-your-own-voice)
-[Experiments and Benchmarks](#experiments-and-benchmarks)
-[Released Models](#released-models)
-[Released Models](#released-models)
-[Experiments and Benchmarks](#experiments-and-benchmarks)
-[Questions and Help](#questions-and-help)
-[Questions and Help](#questions-and-help)
## Prerequisites
## Prerequisites
...
@@ -466,9 +466,21 @@ Test Set | Aishell Model | Internal Mandarin Model
...
@@ -466,9 +466,21 @@ Test Set | Aishell Model | Internal Mandarin Model
Aishell-Test | X.X | X.X
Aishell-Test | X.X | X.X
Baidu-Mandarin-Test | X.X | X.X
Baidu-Mandarin-Test | X.X | X.X
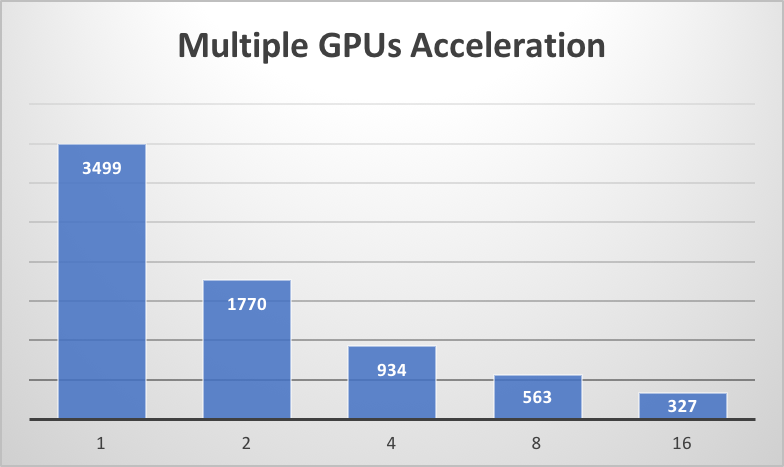
#### Multiple GPU Efficiency
#### Acceleration with Multi-GPUs
We compare the training time with 1, 2, 4, 8, 16 Tesla K40m GPUs (with a subset of LibriSpeech samples whose audio durations are between 6.0 and 7.0 seconds). And it shows that a **near-linear** acceleration with multiple GPUs has been achieved. In the following figure, the time (in seconds) used for training is plotted on the blue bars.
{kind=link}