AGE baseline (#3031)
* AGE challenge baseline
Showing
此差异已折叠。
此差异已折叠。
{kind=link}
82.1 KB
{kind=link}
62.0 KB
{kind=link}
5.2 KB
{kind=link}
160.2 KB
此差异已折叠。
此差异已折叠。
{kind=link}

222.7 KB
{kind=link}
117.2 KB
{kind=link}
458.4 KB
{kind=link}
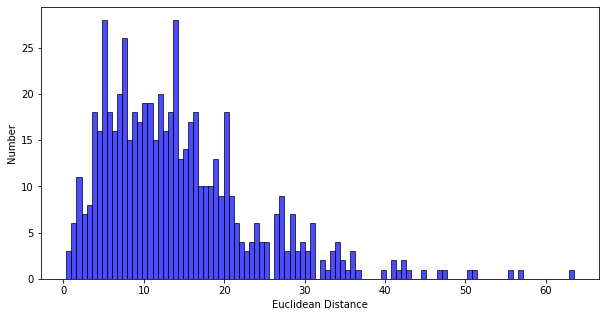
6.4 KB
* AGE challenge baseline
82.1 KB
62.0 KB
5.2 KB
160.2 KB
222.7 KB
117.2 KB
458.4 KB
6.4 KB