Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
529ad161
M
models
项目概览
PaddlePaddle
/
models
接近 3 年 前同步成功
通知
234
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
529ad161
编写于
9月 25, 2019
作者:
B
Bai Yifan
提交者:
whs
9月 25, 2019
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add distillation demo and doc (#3411)
* add distillation demo and doc
上级
3536bab5
变更
10
隐藏空白更改
内联
并排
Showing
10 changed file
with
561 addition
and
13 deletion
+561
-13
PaddleSlim/classification/distillation/README.md
PaddleSlim/classification/distillation/README.md
+160
-0
PaddleSlim/classification/distillation/__init__.py
PaddleSlim/classification/distillation/__init__.py
+0
-0
PaddleSlim/classification/distillation/compress.py
PaddleSlim/classification/distillation/compress.py
+182
-0
PaddleSlim/classification/distillation/configs/mobilenetv1_resnet50_distillation.yaml
...stillation/configs/mobilenetv1_resnet50_distillation.yaml
+23
-0
PaddleSlim/classification/distillation/configs/mobilenetv2_resnet50_distillation.yaml
...stillation/configs/mobilenetv2_resnet50_distillation.yaml
+18
-0
PaddleSlim/classification/distillation/configs/resnet34_resnet50_distillation.yaml
.../distillation/configs/resnet34_resnet50_distillation.yaml
+23
-0
PaddleSlim/classification/distillation/images/mobilenetv2.jpg
...leSlim/classification/distillation/images/mobilenetv2.jpg
+0
-0
PaddleSlim/classification/distillation/run.sh
PaddleSlim/classification/distillation/run.sh
+127
-0
PaddleSlim/classification/models/__init__.py
PaddleSlim/classification/models/__init__.py
+2
-2
PaddleSlim/classification/models/resnet.py
PaddleSlim/classification/models/resnet.py
+26
-11
未找到文件。
PaddleSlim/classification/distillation/README.md
0 → 100755
浏览文件 @
529ad161
>运行该示例前请安装Paddle1.6或更高版本
# 分类模型知识蒸馏示例
## 概述
该示例使用PaddleSlim提供的
[
蒸馏策略
](
[https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/tutorial.md#3-%E8%92%B8%E9%A6%8F](https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/tutorial.md#3-蒸馏
)
)对分类模型进行知识蒸馏。
在阅读该示例前,建议您先了解以下内容:
-
[
分类模型的常规训练方法
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification
)
-
[
PaddleSlim使用文档
](
https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md
)
## 配置文件说明
关于配置文件如何编写您可以参考:
-
[
PaddleSlim配置文件编写说明
](
https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md#122-%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6%E7%9A%84%E4%BD%BF%E7%94%A8
)
-
[
蒸馏策略配置文件编写说明
](
https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md#23-%E8%92%B8%E9%A6%8F
)
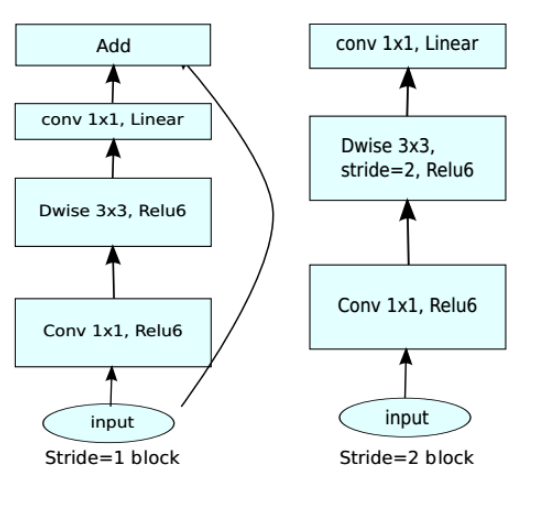
这里以MobileNetV2模型为例,MobileNetV2的主要结构为Inverted residuals, 如图1所示:
<p
align=
"center"
>
<img
src=
"images/mobilenetv2.jpg"
height=
300
width=
600
hspace=
'10'
/>
<br
/>
<strong>
图1
</strong>
</p>
首先,为了对
`student model`
和
`teacher model`
有个总体的认识,从而进一步确认蒸馏的对象,我们通过以下命令分别观察两个网络变量(Variable)的名称和形状:
```
python
# 观察student model的Variable
for
v
in
fluid
.
default_main_program
().
list_vars
():
print
v
.
name
,
v
.
shape
```
```
python
# 观察teacher model的Variable
for
v
in
teacher_program
.
list_vars
():
print
v
.
name
,
v
.
shape
```
经过对比可以发现,
`student model`
和
`teacher model`
预测的输出分别为:
```
bash
# student model
fc_0.tmp_0
(
-1
, 1000
)
# teacher model
res50_fc_0.tmp_0
(
-1
, 1000
)
```
所以,我们用
`l2_distiller`
对这两个特征图做蒸馏。在配置文件中进行如下配置:
```
yaml
distillers
:
l2_distiller
:
class
:
'
L2Distiller'
teacher_feature_map
:
'
res50_fc_0.tmp_1'
student_feature_map
:
'
fc_0.tmp_1'
distillation_loss_weight
:
1
strategies
:
distillation_strategy
:
class
:
'
DistillationStrategy'
distillers
:
[
'
l2_distiller'
]
start_epoch
:
0
end_epoch
:
130
```
我们也可以根据上述操作为蒸馏策略选择其他loss,PaddleSlim支持的有
`FSP_loss`
,
`L2_loss`
和
`softmax_with_cross_entropy_loss`
。
## 训练
根据
[
PaddleCV/image_classification/train.py
](
https://github.com/PaddlePaddle/models/blob/develop/PaddleCV/image_classification/train.py
)
编写压缩脚本compress.py。
在该脚本中定义了Compressor对象,用于执行压缩任务。
可以通过命令
`python compress.py`
用默认参数执行压缩任务,通过
`python compress.py --help`
查看可配置参数,简述如下:
-
use_gpu: 是否使用gpu。如果选择使用GPU,请确保当前环境和Paddle版本支持GPU。默认为True。
-
batch_size: 蒸馏训练用的batch size。
-
total_images:使用数据集的训练集总图片数
-
class_dim:使用数据集的类别数。
-
image_shape:使用数据集的图片尺寸。
-
model: 要压缩的目标模型,该示例支持'MobileNetV1', 'MobileNetV2'和'ResNet34'。
-
pretrained_model: student预训练模型的路径,可以从
[
这里
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification#%E5%B7%B2%E5%8F%91%E5%B8%83%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E6%80%A7%E8%83%BD
)
下载。
-
teacher_model: teacher模型,该示例支持'ResNet50'。
-
teacher_pretrained_model: teacher预训练模型的路径,可以从
[
这里
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification#%E5%B7%B2%E5%8F%91%E5%B8%83%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E6%80%A7%E8%83%BD
)
下载。
-
config_file: 压缩策略的配置文件。
您可以通过运行脚本
`run.sh`
运行改示例,请确保已正确下载
[
pretrained model
](
https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification#%E5%B7%B2%E5%8F%91%E5%B8%83%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E6%80%A7%E8%83%BD
)
。
### 保存断点(checkpoint)
如果在配置文件中设置了
`checkpoint_path`
, 则在压缩任务执行过程中会自动保存断点,当任务异常中断时,
重启任务会自动从
`checkpoint_path`
路径下按数字顺序加载最新的checkpoint文件。如果不想让重启的任务从断点恢复,
需要修改配置文件中的
`checkpoint_path`
,或者将
`checkpoint_path`
路径下文件清空。
>注意:配置文件中的信息不会保存在断点中,重启前对配置文件的修改将会生效。
## 评估
如果在配置文件中设置了
`checkpoint_path`
,则每个epoch会保存一个压缩后的用于评估的模型,
该模型会保存在
`${checkpoint_path}/${epoch_id}/eval_model/`
路径下,包含
`__model__`
和
`__params__`
两个文件。
其中,
`__model__`
用于保存模型结构信息,
`__params__`
用于保存参数(parameters)信息。
如果不需要保存评估模型,可以在定义Compressor对象时,将
`save_eval_model`
选项设置为False(默认为True)。
脚本
<a
href=
"../eval.py"
>
PaddleSlim/classification/eval.py
</a>
中为使用该模型在评估数据集上做评估的示例。
## 预测
如果在配置文件中设置了
`checkpoint_path`
,并且在定义Compressor对象时指定了
`prune_infer_model`
选项,则每个epoch都会
保存一个
`inference model`
。该模型是通过删除eval_program中多余的operators而得到的。
该模型会保存在
`${checkpoint_path}/${epoch_id}/eval_model/`
路径下,包含
`__model__.infer`
和
`__params__`
两个文件。
其中,
`__model__.infer`
用于保存模型结构信息,
`__params__`
用于保存参数(parameters)信息。
更多关于
`prune_infer_model`
选项的介绍,请参考:
[
Compressor介绍
](
https://github.com/PaddlePaddle/models/blob/develop/PaddleSlim/docs/usage.md#121-%E5%A6%82%E4%BD%95%E6%94%B9%E5%86%99%E6%99%AE%E9%80%9A%E8%AE%AD%E7%BB%83%E8%84%9A%E6%9C%AC
)
### python预测
在脚本
<a
href=
"../infer.py"
>
PaddleSlim/classification/infer.py
</a>
中展示了如何使用fluid python API加载使用预测模型进行预测。
### PaddleLite
该示例中产出的预测(inference)模型可以直接用PaddleLite进行加载使用。
关于PaddleLite如何使用,请参考:
[
PaddleLite使用文档
](
https://github.com/PaddlePaddle/Paddle-Lite/wiki#%E4%BD%BF%E7%94%A8
)
## 示例结果
### MobileNetV1
| FLOPS | top1_acc/top5_acc |
| -------- | ----------------- |
| baseline | 70.99%/89.68% |
| 蒸馏后 | - |
>训练超参:
### MobileNetV2
| FLOPS | top1_acc/top5_acc |
| -------- | ----------------- |
| baseline | 72.15%/90.65% |
| 蒸馏后 | - |
>训练超参:
### ResNet34
| FLOPS | top1_acc/top5_acc |
| -------- | ----------------- |
| baseline | 74.57%/92.14% |
| 蒸馏后 | - |
>训练超参:
## FAQ
PaddleSlim/classification/distillation/__init__.py
0 → 100644
浏览文件 @
529ad161
PaddleSlim/classification/distillation/compress.py
0 → 100644
浏览文件 @
529ad161
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
os
import
time
import
sys
import
logging
import
paddle
import
argparse
import
functools
import
paddle.fluid
as
fluid
sys
.
path
.
append
(
".."
)
import
imagenet_reader
as
reader
import
models
sys
.
path
.
append
(
"../../"
)
from
utility
import
add_arguments
,
print_arguments
from
paddle.fluid.contrib.slim
import
Compressor
logging
.
basicConfig
(
format
=
'%(asctime)s-%(levelname)s: %(message)s'
)
_logger
=
logging
.
getLogger
(
__name__
)
_logger
.
setLevel
(
logging
.
INFO
)
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
add_arg
=
functools
.
partial
(
add_arguments
,
argparser
=
parser
)
# yapf: disable
add_arg
(
'batch_size'
,
int
,
64
*
4
,
"Minibatch size."
)
add_arg
(
'use_gpu'
,
bool
,
True
,
"Whether to use GPU or not."
)
add_arg
(
'total_images'
,
int
,
1281167
,
"Training image number."
)
add_arg
(
'class_dim'
,
int
,
1000
,
"Class number."
)
add_arg
(
'image_shape'
,
str
,
"3,224,224"
,
"Input image size"
)
add_arg
(
'model'
,
str
,
"MobileNet"
,
"Set the network to use."
)
add_arg
(
'pretrained_model'
,
str
,
None
,
"Whether to use pretrained model."
)
add_arg
(
'teacher_model'
,
str
,
None
,
"Set the teacher network to use."
)
add_arg
(
'teacher_pretrained_model'
,
str
,
None
,
"Whether to use pretrained model."
)
add_arg
(
'compress_config'
,
str
,
None
,
"The config file for compression with yaml format."
)
add_arg
(
'quant_only'
,
bool
,
False
,
"Only do quantization-aware training."
)
# yapf: enable
model_list
=
[
m
for
m
in
dir
(
models
)
if
"__"
not
in
m
]
def
compress
(
args
):
image_shape
=
[
int
(
m
)
for
m
in
args
.
image_shape
.
split
(
","
)]
assert
args
.
model
in
model_list
,
"{} is not in lists: {}"
.
format
(
args
.
model
,
model_list
)
image
=
fluid
.
layers
.
data
(
name
=
'image'
,
shape
=
image_shape
,
dtype
=
'float32'
)
label
=
fluid
.
layers
.
data
(
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int64'
)
# model definition
model
=
models
.
__dict__
[
args
.
model
]()
if
args
.
model
is
"GoogleNet"
:
out0
,
out1
,
out2
=
model
.
net
(
input
=
image
,
class_dim
=
args
.
class_dim
)
cost0
=
fluid
.
layers
.
cross_entropy
(
input
=
out0
,
label
=
label
)
cost1
=
fluid
.
layers
.
cross_entropy
(
input
=
out1
,
label
=
label
)
cost2
=
fluid
.
layers
.
cross_entropy
(
input
=
out2
,
label
=
label
)
avg_cost0
=
fluid
.
layers
.
mean
(
x
=
cost0
)
avg_cost1
=
fluid
.
layers
.
mean
(
x
=
cost1
)
avg_cost2
=
fluid
.
layers
.
mean
(
x
=
cost2
)
avg_cost
=
avg_cost0
+
0.3
*
avg_cost1
+
0.3
*
avg_cost2
acc_top1
=
fluid
.
layers
.
accuracy
(
input
=
out0
,
label
=
label
,
k
=
1
)
acc_top5
=
fluid
.
layers
.
accuracy
(
input
=
out0
,
label
=
label
,
k
=
5
)
else
:
if
args
.
model
==
'ResNet34'
:
model
.
prefix_name
=
'res34'
out
=
model
.
net
(
input
=
image
,
class_dim
=
args
.
class_dim
,
fc_name
=
'fc_0'
)
else
:
out
=
model
.
net
(
input
=
image
,
class_dim
=
args
.
class_dim
)
cost
=
fluid
.
layers
.
cross_entropy
(
input
=
out
,
label
=
label
)
avg_cost
=
fluid
.
layers
.
mean
(
x
=
cost
)
acc_top1
=
fluid
.
layers
.
accuracy
(
input
=
out
,
label
=
label
,
k
=
1
)
acc_top5
=
fluid
.
layers
.
accuracy
(
input
=
out
,
label
=
label
,
k
=
5
)
#print("="*50+"student_model_params"+"="*50)
#for v in fluid.default_main_program().list_vars():
# print(v.name, v.shape)
val_program
=
fluid
.
default_main_program
().
clone
()
if
args
.
quant_only
:
boundaries
=
[
args
.
total_images
/
args
.
batch_size
*
10
,
args
.
total_images
/
args
.
batch_size
*
16
]
values
=
[
1e-4
,
1e-5
,
1e-6
]
else
:
boundaries
=
[
args
.
total_images
/
args
.
batch_size
*
30
,
args
.
total_images
/
args
.
batch_size
*
60
,
args
.
total_images
/
args
.
batch_size
*
90
]
values
=
[
0.1
,
0.01
,
0.001
,
0.0001
]
opt
=
fluid
.
optimizer
.
Momentum
(
momentum
=
0.9
,
learning_rate
=
fluid
.
layers
.
piecewise_decay
(
boundaries
=
boundaries
,
values
=
values
),
regularization
=
fluid
.
regularizer
.
L2Decay
(
4e-5
))
place
=
fluid
.
CUDAPlace
(
0
)
if
args
.
use_gpu
else
fluid
.
CPUPlace
()
exe
=
fluid
.
Executor
(
place
)
exe
.
run
(
fluid
.
default_startup_program
())
if
args
.
pretrained_model
:
def
if_exist
(
var
):
return
os
.
path
.
exists
(
os
.
path
.
join
(
args
.
pretrained_model
,
var
.
name
))
fluid
.
io
.
load_vars
(
exe
,
args
.
pretrained_model
,
predicate
=
if_exist
)
val_reader
=
paddle
.
batch
(
reader
.
val
(
data_dir
=
'../data/ILSVRC2012'
),
batch_size
=
args
.
batch_size
)
val_feed_list
=
[(
'image'
,
image
.
name
),
(
'label'
,
label
.
name
)]
val_fetch_list
=
[(
'acc_top1'
,
acc_top1
.
name
),
(
'acc_top5'
,
acc_top5
.
name
)]
train_reader
=
paddle
.
batch
(
reader
.
train
(
data_dir
=
'../data/ILSVRC2012'
),
batch_size
=
args
.
batch_size
,
drop_last
=
True
)
train_feed_list
=
[(
'image'
,
image
.
name
),
(
'label'
,
label
.
name
)]
train_fetch_list
=
[(
'loss'
,
avg_cost
.
name
)]
teacher_programs
=
[]
distiller_optimizer
=
None
if
args
.
teacher_model
:
teacher_model
=
models
.
__dict__
[
args
.
teacher_model
](
prefix_name
=
'res50'
)
# define teacher program
teacher_program
=
fluid
.
Program
()
startup_program
=
fluid
.
Program
()
with
fluid
.
program_guard
(
teacher_program
,
startup_program
):
img
=
teacher_program
.
global_block
().
_clone_variable
(
image
,
force_persistable
=
False
)
predict
=
teacher_model
.
net
(
img
,
class_dim
=
args
.
class_dim
,
fc_name
=
'fc_0'
)
#print("="*50+"teacher_model_params"+"="*50)
#for v in teacher_program.list_vars():
# print(v.name, v.shape)
exe
.
run
(
startup_program
)
assert
args
.
teacher_pretrained_model
and
os
.
path
.
exists
(
args
.
teacher_pretrained_model
),
"teacher_pretrained_model should be set when teacher_model is not None."
def
if_exist
(
var
):
return
os
.
path
.
exists
(
os
.
path
.
join
(
args
.
teacher_pretrained_model
,
var
.
name
))
fluid
.
io
.
load_vars
(
exe
,
args
.
teacher_pretrained_model
,
main_program
=
teacher_program
,
predicate
=
if_exist
)
distiller_optimizer
=
opt
teacher_programs
.
append
(
teacher_program
.
clone
(
for_test
=
True
))
com_pass
=
Compressor
(
place
,
fluid
.
global_scope
(),
fluid
.
default_main_program
(),
train_reader
=
train_reader
,
train_feed_list
=
train_feed_list
,
train_fetch_list
=
train_fetch_list
,
eval_program
=
val_program
,
eval_reader
=
val_reader
,
eval_feed_list
=
val_feed_list
,
eval_fetch_list
=
val_fetch_list
,
teacher_programs
=
teacher_programs
,
save_eval_model
=
True
,
prune_infer_model
=
[[
image
.
name
],
[
out
.
name
]],
train_optimizer
=
opt
,
distiller_optimizer
=
distiller_optimizer
)
com_pass
.
config
(
args
.
compress_config
)
com_pass
.
run
()
def
main
():
args
=
parser
.
parse_args
()
print_arguments
(
args
)
compress
(
args
)
if
__name__
==
'__main__'
:
main
()
PaddleSlim/classification/distillation/configs/mobilenetv1_resnet50_distillation.yaml
0 → 100644
浏览文件 @
529ad161
version
:
1.0
distillers
:
fsp_distiller
:
class
:
'
FSPDistiller'
teacher_pairs
:
[[
'
res50_res2a_branch2a.conv2d.output.1.tmp_0'
,
'
res50_res3a_branch2a.conv2d.output.1.tmp_0'
]]
student_pairs
:
[[
'
depthwise_conv2d_1.tmp_0'
,
'
conv2d_3.tmp_0'
]]
distillation_loss_weight
:
1
l2_distiller
:
class
:
'
L2Distiller'
teacher_feature_map
:
'
res50_fc_0.tmp_0'
student_feature_map
:
'
fc_0.tmp_0'
distillation_loss_weight
:
1
strategies
:
distillation_strategy
:
class
:
'
DistillationStrategy'
distillers
:
[
'
fsp_distiller'
,
'
l2_distiller'
]
start_epoch
:
0
end_epoch
:
130
compressor
:
epoch
:
130
checkpoint_path
:
'
./checkpoints/'
strategies
:
-
distillation_strategy
PaddleSlim/classification/distillation/configs/mobilenetv2_resnet50_distillation.yaml
0 → 100644
浏览文件 @
529ad161
version
:
1.0
distillers
:
l2_distiller
:
class
:
'
L2Distiller'
teacher_feature_map
:
'
res50_fc_0.tmp_1'
student_feature_map
:
'
fc_0.tmp_1'
distillation_loss_weight
:
1
strategies
:
distillation_strategy
:
class
:
'
DistillationStrategy'
distillers
:
[
'
l2_distiller'
]
start_epoch
:
0
end_epoch
:
130
compressor
:
epoch
:
130
checkpoint_path
:
'
./checkpoints/'
strategies
:
-
distillation_strategy
PaddleSlim/classification/distillation/configs/resnet34_resnet50_distillation.yaml
0 → 100644
浏览文件 @
529ad161
version
:
1.0
distillers
:
fsp_distiller
:
class
:
'
FSPDistiller'
teacher_pairs
:
[[
'
res50_res2a_branch2a.conv2d.output.1.tmp_0'
,
'
res50_res2a_branch2c.conv2d.output.1.tmp_0'
],
[
'
res50_res3b_branch2a.conv2d.output.1.tmp_0'
,
'
res50_res3b_branch2c.conv2d.output.1.tmp_0'
]]
student_pairs
:
[[
'
res34_res2a_branch2a.conv2d.output.1.tmp_0'
,
'
res34_res2a_branch2c.conv2d.output.1.tmp_0'
],
[
'
res34_res3b_branch2a.conv2d.output.1.tmp_0'
,
'
res34_res3b_branch2c.conv2d.output.1.tmp_0'
]]
distillation_loss_weight
:
1
l2_distiller
:
class
:
'
L2Distiller'
teacher_feature_map
:
'
res50_fc_0.tmp_0'
student_feature_map
:
'
res34_fc_0.tmp_0'
distillation_loss_weight
:
1
strategies
:
distillation_strategy
:
class
:
'
DistillationStrategy'
distillers
:
[
'
fsp_distiller'
,
'
l2_distiller'
]
start_epoch
:
0
end_epoch
:
130
compressor
:
epoch
:
130
checkpoint_path
:
'
./checkpoints/'
strategies
:
-
distillation_strategy
PaddleSlim/classification/distillation/images/mobilenetv2.jpg
0 → 100644
浏览文件 @
529ad161
65.1 KB
PaddleSlim/classification/distillation/run.sh
0 → 100644
浏览文件 @
529ad161
#!/usr/bin/env bash
# download pretrain model
root_url
=
"http://paddle-imagenet-models-name.bj.bcebos.com"
MobileNetV1
=
"MobileNetV1_pretrained.tar"
MobileNetV2
=
"MobileNetV2_pretrained.tar"
ResNet34
=
"ResNet34_pretrained.tar"
ResNet50
=
"ResNet50_pretrained.tar"
pretrain_dir
=
'../pretrain'
if
[
!
-d
${
pretrain_dir
}
]
;
then
mkdir
${
pretrain_dir
}
fi
cd
${
pretrain_dir
}
if
[
!
-f
${
MobileNetV2
}
]
;
then
wget
${
root_url
}
/
${
MobileNetV2
}
tar
xf
${
MobileNetV2
}
fi
if
[
!
-f
${
ResNet34
}
]
;
then
wget
${
root_url
}
/
${
ResNet34
}
tar
xf
${
ResNet34
}
fi
if
[
!
-f
${
ResNet50
}
]
;
then
wget
${
root_url
}
/
${
ResNet50
}
tar
xf
${
ResNet50
}
fi
cd
-
# enable GC strategy
export
FLAGS_fast_eager_deletion_mode
=
1
export
FLAGS_eager_delete_tensor_gb
=
0.0
# for distillation
#-----------------
export
CUDA_VISIBLE_DEVICES
=
0,1,2,3
# for mobilenet_v1 distillation
cd
${
pretrain_dir
}
/ResNet50_pretrained
for
files
in
$(
ls
res50_
*
)
do
mv
$files
${
files
#*_
}
done
for
files
in
$(
ls
*
)
do
mv
$files
"res50_"
$files
done
cd
-
python
-u
compress.py
\
--model
"MobileNet"
\
--teacher_model
"ResNet50"
\
--teacher_pretrained_model
../pretrain/ResNet50_pretrained
\
--compress_config
./configs/mobilenetv1_resnet50_distillation.yaml
\
>
mobilenet_v1.log 2>&1 &
tailf mobilenet_v1.log
cd
${
pretrain_dir
}
/ResNet50_pretrained
for
files
in
$(
ls
res50_
*
)
do
mv
$files
${
files
#*_
}
done
cd
-
# for mobilenet_v2 distillation
#cd ${pretrain_dir}/ResNet50_pretrained
#for files in $(ls res50_*)
# do mv $files ${files#*_}
#done
#for files in $(ls *)
# do mv $files "res50_"$files
#done
#cd -
#
#python -u compress.py \
#--model "MobileNetV2" \
#--teacher_model "ResNet50" \
#--teacher_pretrained_model ../pretrain/ResNet50_pretrained \
#--compress_config ./configs/mobilenetv2_resnet50_distillation.yaml\
#> mobilenet_v2.log 2>&1 &
#tailf mobilenet_v2.log
#
#cd ${pretrain_dir}/ResNet50_pretrained
#for files in $(ls res50_*)
# do mv $files ${files#*_}
#done
#cd -
# for resnet34 distillation
#cd ${pretrain_dir}/ResNet50_pretrained
#for files in $(ls res50_*)
# do mv $files ${files#*_}
#done
#for files in $(ls *)
# do mv $files "res50_"$files
#done
#cd -
#
#cd ${pretrain_dir}/ResNet34_pretrained
#for files in $(ls res34_*)
# do mv $files ${files#*_}
#done
#for files in $(ls *)
# do mv $files "res34_"$files
#done
#cd -
#
#python compress.py \
#--model "ResNet34" \
#--teacher_model "ResNet50" \
#--teacher_pretrained_model ../pretrain/ResNet50_pretrained \
#--compress_config ./configs/resnet34_resnet50_distillation.yaml \
#> resnet34.log 2>&1 &
#tailf resnet34.log
#
#cd ${pretrain_dir}/ResNet50_pretrained
#for files in $(ls res50_*)
# do mv $files ${files#*_}
#done
#cd -
#
#cd ${pretrain_dir}/ResNet34_pretrained
#for files in $(ls res34_*)
# do mv $files ${files#*_}
#done
#cd -
PaddleSlim/classification/models/__init__.py
浏览文件 @
529ad161
from
.mobilenet
import
MobileNet
from
.resnet
import
ResNet50
from
.resnet
import
ResNet
34
,
ResNet
50
from
.mobilenet_v2
import
MobileNetV2
__all__
=
[
'MobileNet
'
,
'ResNet50'
,
'MobileNetV2'
]
__all__
=
[
'MobileNet'
,
'ResNet34
'
,
'ResNet50'
,
'MobileNetV2'
]
PaddleSlim/classification/models/resnet.py
浏览文件 @
529ad161
...
...
@@ -6,7 +6,7 @@ import paddle.fluid as fluid
import
math
from
paddle.fluid.param_attr
import
ParamAttr
__all__
=
[
"ResNet"
,
"ResNet50"
,
"ResNet101"
,
"ResNet152"
]
__all__
=
[
"ResNet"
,
"ResNet
34"
,
"ResNet
50"
,
"ResNet101"
,
"ResNet152"
]
train_parameters
=
{
"input_size"
:
[
3
,
224
,
224
],
...
...
@@ -22,17 +22,19 @@ train_parameters = {
class
ResNet
():
def
__init__
(
self
,
layers
=
50
):
def
__init__
(
self
,
layers
=
50
,
prefix_name
=
''
):
self
.
params
=
train_parameters
self
.
layers
=
layers
self
.
prefix_name
=
prefix_name
def
net
(
self
,
input
,
class_dim
=
1000
,
conv1_name
=
'conv1'
,
fc_name
=
None
):
layers
=
self
.
layers
supported_layers
=
[
50
,
101
,
152
]
prefix_name
=
self
.
prefix_name
+
'_'
supported_layers
=
[
34
,
50
,
101
,
152
]
assert
layers
in
supported_layers
,
\
"supported layers are {} but input layer is {}"
.
format
(
supported_layers
,
layers
)
if
layers
==
50
:
if
layers
==
34
or
layers
==
50
:
depth
=
[
3
,
4
,
6
,
3
]
elif
layers
==
101
:
depth
=
[
3
,
4
,
23
,
3
]
...
...
@@ -48,7 +50,7 @@ class ResNet():
filter_size
=
7
,
stride
=
2
,
act
=
'relu'
,
name
=
conv1_name
)
name
=
prefix_name
+
conv1_name
)
conv
=
fluid
.
layers
.
pool2d
(
input
=
conv
,
pool_size
=
3
,
...
...
@@ -65,6 +67,7 @@ class ResNet():
conv_name
=
"res"
+
str
(
block
+
2
)
+
"b"
+
str
(
i
)
else
:
conv_name
=
"res"
+
str
(
block
+
2
)
+
chr
(
97
+
i
)
conv_name
=
prefix_name
+
conv_name
conv
=
self
.
bottleneck_block
(
input
=
conv
,
num_filters
=
num_filters
[
block
],
...
...
@@ -77,7 +80,7 @@ class ResNet():
out
=
fluid
.
layers
.
fc
(
input
=
pool
,
size
=
class_dim
,
act
=
'softmax'
,
name
=
fc_name
,
name
=
prefix_name
+
fc_name
,
param_attr
=
fluid
.
param_attr
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Uniform
(
-
stdv
,
stdv
)))
...
...
@@ -102,10 +105,17 @@ class ResNet():
param_attr
=
ParamAttr
(
name
=
name
+
"_weights"
),
bias_attr
=
False
,
name
=
name
+
'.conv2d.output.1'
)
if
name
==
"conv1"
:
bn_name
=
"bn_"
+
name
if
self
.
prefix_name
==
''
:
if
name
==
"conv1"
:
bn_name
=
"bn_"
+
name
else
:
bn_name
=
"bn"
+
name
[
3
:]
else
:
bn_name
=
"bn"
+
name
[
3
:]
if
name
.
split
(
"_"
)[
1
]
==
"conv1"
:
bn_name
=
name
.
split
(
"_"
,
1
)[
0
]
+
"_bn_"
+
name
.
split
(
"_"
,
1
)[
1
]
else
:
bn_name
=
name
.
split
(
"_"
,
1
)[
0
]
+
"_bn"
+
name
.
split
(
"_"
,
1
)[
1
][
3
:]
return
fluid
.
layers
.
batch_norm
(
input
=
conv
,
act
=
act
,
...
...
@@ -150,8 +160,13 @@ class ResNet():
x
=
short
,
y
=
conv2
,
act
=
'relu'
,
name
=
name
+
".add.output.5"
)
def
ResNet50
():
model
=
ResNet
(
layers
=
50
)
def
ResNet34
(
prefix_name
=
''
):
model
=
ResNet
(
layers
=
34
,
prefix_name
=
prefix_name
)
return
model
def
ResNet50
(
prefix_name
=
''
):
model
=
ResNet
(
layers
=
50
,
prefix_name
=
prefix_name
)
return
model
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}