Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
4b8c141d
M
models
项目概览
PaddlePaddle
/
models
大约 1 年 前同步成功
通知
222
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
4b8c141d
编写于
11月 20, 2021
作者:
littletomatodonkey
提交者:
GitHub
11月 20, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
fix template (#5381)
* fix template * add basic link * fix doc * fix doc
上级
e3d13b89
变更
9
隐藏空白更改
内联
并排
Showing
9 changed file
with
352 addition
and
53 deletion
+352
-53
community/REPO_TEMPLATE_DESC.md
community/REPO_TEMPLATE_DESC.md
+7
-13
community/repo_template/README.md
community/repo_template/README.md
+43
-40
community/repo_template/config/config.yaml
community/repo_template/config/config.yaml
+0
-0
community/repo_template/dataset/preprocess.py
community/repo_template/dataset/preprocess.py
+0
-0
community/repo_template/model/resnet.py
community/repo_template/model/resnet.py
+0
-0
community/repo_template/test_tipc/README.md
community/repo_template/test_tipc/README.md
+83
-0
community/repo_template/test_tipc/docs/guide.png
community/repo_template/test_tipc/docs/guide.png
+0
-0
community/repo_template/test_tipc/docs/install.md
community/repo_template/test_tipc/docs/install.md
+124
-0
community/repo_template/test_tipc/docs/test_train_inference_python.md
...po_template/test_tipc/docs/test_train_inference_python.md
+95
-0
未找到文件。
community/REPO_TEMPLATE_DESC.md
浏览文件 @
4b8c141d
...
...
@@ -4,17 +4,15 @@
本文示例项目在文件夹
[
repo_template
](
./repo_template
)
下,您可以将这个文件夹中的内容拷贝出去,放在自己的项目文件夹下,并编写对应的代码与文档。
**注意:**
:该模板中仅给出了必要的代码结构,剩余部分,如模型组网、损失函数、数据处理等,与参考repo中的结构尽量保持一致,便于复现即可。
## 1. 目录结构
建议的目录结构如下:
```
./repo_template # 项目文件夹名称,可以修改为自己的文件夹名称
|-- config # 参数配置文件夹
|-- dataset # 数据处理代码文件夹
|-- images # 测试图片文件夹
|-- model # 模型实现文件夹
|-- utils # 功能类API文件夹
|-- deploy # 预测部署相关
| ├── pdinference # 基于PaddleInference的python推理代码文件夹
| ├── pdserving # 基于PaddleServing的推理代码文件夹
...
...
@@ -22,7 +20,7 @@
| ├── train.py # 训练代码文件
| ├── eval.py # 评估代码文件
| ├── infer.py # 预测代码文件
| ├── export.py
# 模型导出代码文件
| ├── export.py # 模型导出代码文件
|-- scripts # 脚本类文件夹
| ├── train.sh # 训练脚本,需要包含单机单卡和单机多卡训练的方式,单机多卡的训练方式可以以注释的形式给出
| ├── eval.sh # 评估脚本,提供单机单卡的评估方式即可
...
...
@@ -34,17 +32,13 @@
|-- LICENSE # LICENSE文件
```
-
**config:**
存储模型配置相关文件的文件夹,保存模型的配置信息,如
`configs.py、configs.yml`
等
-
**dataset:**
存储数据相关文件的文件夹,包含数据下载、数据处理等,如
`dataset_download.py、dataset_process.py`
等
-
**images:**
存储项目相关的图片,首页以及TIPC文档中需要的图像都可以放在这里,如果需要进一步区分功能,可以在里面建立不同的子文件夹。
-
**model:**
存储模型相关代码文件的文件夹,保存模型的实现,如
`resnet.py、cyclegan.py`
等
-
**utils:**
存储功能类相关文件的文件夹,如可视化,文件夹操作,模型保存与加载等
-
**deploy:**
部署相关文件夹,目前包含PaddleInference推理文件夹以及PaddleServing服务部署文件夹
-
**tools:**
工具类文件夹,包含训练、评估、预测、模型导出等代码文件
-
**scripts:**
工具类文件夹,包含训练、评估、预测、模型导出等脚本文件
-
**deploy:**
推理部署相关的文件夹,Paddle Inference推理、Paddle Serving服务部署、PaddleLite端侧部署的代码都可以放在这里。
-
**scripts:**
脚本类文件夹,包含训练、评估、预测、模型导出等脚本文件。
-
**test_tipc:**
训推一体 (TIPC) 测试文件夹,更多关于TIPC的介绍可以参考:
[
飞桨训推一体认证(TIPC)开发文档
](
https://github.com/PaddlePaddle/models/blob/tipc/docs/tipc_test/README.md
)
-
**README_en.md:**
中
文版当前模型的使用说明,规范参考 README 内容要求
-
**README.md:**
英
文版当前模型的使用说明,规范参考 README 内容要求
-
**README_en.md:**
英
文版当前模型的使用说明,规范参考 README 内容要求
-
**README.md:**
中
文版当前模型的使用说明,规范参考 README 内容要求
-
**LICENSE:**
LICENSE文件
## 2. 功能实现
...
...
community/repo_template/README.md
浏览文件 @
4b8c141d
#
模型
名称
#
论文
名称
模型的具体名称,如:# ResNet50
目录
## 目录
```
1. 简介
2. 复现精度
3. 数据集
4. 环境依赖
5. 快速开始
6. 代码结构与详细说明
7. 模型信息
2. 数据集和复现精度
3. 开始使用
4. 代码结构与详细说明
```
**注意:**
目录可以使用
[
gh-md-toc
](
https://github.com/ekalinin/github-markdown-toc
)
生成
## 1. 简介
简单的介绍模型,以及模型的主要架构或主要功能,如果能给出效果图,可以在简介的下方直接贴上图片,展示模型效果。然后另起一行,按如下格式给出论文
、参考代码及对应的
链接。
简单的介绍模型,以及模型的主要架构或主要功能,如果能给出效果图,可以在简介的下方直接贴上图片,展示模型效果。然后另起一行,按如下格式给出论文
名称及链接、参考代码链接、aistudio体验教程
链接。
注意:在给出参考repo的链接之后,建议添加对参考repo的开发者的致谢。
...
...
@@ -29,61 +23,70 @@
在此非常感谢
`$参考repo的 github id$`
等人贡献的
[
repo name
](
url
)
,提高了本repo复现论文的效率。
## 2. 复现精度
**aistudio体验教程:**
[
地址
](
url
)
给出论文中精度、参考代码的精度、本repo复现的精度、模型下载链接、模型大小,以表格的形式给出。如果超参数有差别,可以在表格中新增一列备注一下。
如果涉及到
`轻量化骨干网络`
,需要新增一列骨干网络的信息。
## 2. 数据集和复现精度
## 3. 数据集
给出数据集的链接,然后按格式描述数据集大小与数据集格式即可。
给出本repo中用到的数据集的链接,然后按格式描述数据集大小与数据集格式。
格式如下:
-
数据集大小:关于数据集大小的描述,如类别,数量,图像大小等等
;
-
数据集大小:关于数据集大小的描述,如类别,数量,图像大小等等
-
数据集下载链接:链接地址
-
数据格式:关于数据集格式的说明
## 4. 环境依赖
基于上述数据集,给出论文中精度、参考代码的精度、本repo复现的精度、数据集名称、模型下载链接(模型权重和对应的日志文件推荐放在
**百度云网盘**
中,方便下载)、模型大小,以表格的形式给出。如果超参数有差别,可以在表格中新增一列备注一下。
如果涉及到
`轻量化骨干网络验证`
,需要新增一列骨干网络的信息。
## 3. 开始使用
主要分为两部分介绍,一部分是支持的硬件,另一部分是框架等环境的要求,格式如下:
### 3.1 准备环境
-
硬件
:
首先介绍下支持的硬件和框架版本等环境的要求,格式如下
:
-
硬件:xxx
-
框架:
-
PaddlePaddle >= 2.1.0
## 5. 快速开始
然后介绍下怎样安装PaddlePaddle以及对应的requirements。
建议将代码中用到的非python原生的库,都写在requirements.txt中,在安装完PaddlePaddle之后,直接使用
`pip install -r requirements.txt`
安装依赖即可。
### 3.2 快速开始
需要给出快速训练、预测、使用预训练模型预测、模型导出、模型基于inference模型推理的使用说明,同时基于demo图像,给出预测结果和推理结果,并将结果打印或者可视化出来。
##
6
. 代码结构与详细说明
##
4
. 代码结构与详细说明
###
6
.1 代码结构
###
4
.1 代码结构
需要用一小节描述整个项目的代码结构,用一小节描述项目的参数说明,之后各个小节详细的描述每个功能的使用说明。
### 6.2 参数说明
### 4.2 参数说明
以表格的形式,给出当前的参数列表、含义、类型、默认值等信息。
###
6
.3 基础使用
###
4
.3 基础使用
配合部分重要配置参数,介绍模型训练、评估、预测、导出等过程。
###
6
.4 模型部署
###
4
.4 模型部署
给出当前支持的推理部署方式以及相应的参考文档链接。
## 7. 模型信息
### 4.5 TIPC测试支持
这里需要给出TIPC的目录链接。
**注意:**
这里只需提供TIPC基础测试链条中模式
`lite_train_lite_infer`
的代码与文档即可。
*
更多关于TIPC的介绍可以参考:
[
飞桨训推一体认证(TIPC)文档
](
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/test_tipc/readme.md
)
*
关于Linux端基础链条测试接入的代码与文档说明可以参考:
[
基础链条测试接入规范
](
https://github.com/PaddlePaddle/models/blob/tipc/docs/tipc_test/development_specification_docs/train_infer_python.md
)
,
[
PaddleOCR Linux端基础训练预测功能测试文档
](
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/test_tipc/docs/test_train_inference_python.md
)
以表格的信息,给出模型和作者相关的信息。
| 信息 | 说明 |
| --- | --- |
| 发布者 | author |
| 时间 | 2021.11 |
| 框架版本 | Paddle 2.2 |
| 应用场景 | 图像分类 |
| 支持硬件 | GPU、CPU |
| 模型下载链接 |
[
trained model
](
url
)
、
[
inference model
](
url
)
|
| 在线运行 |
[
notebook
](
url
)
、
[
scripts
](
url
)
|
如果您有兴趣,也欢迎为项目集成更多的TIPC测试链条及相关的代码文档,非常感谢您的贡献。
community/repo_template/config/config.yaml
已删除
100644 → 0
浏览文件 @
e3d13b89
community/repo_template/dataset/preprocess.py
已删除
100644 → 0
浏览文件 @
e3d13b89
community/repo_template/model/resnet.py
已删除
100644 → 0
浏览文件 @
e3d13b89
community/repo_template/test_tipc/README.md
浏览文件 @
4b8c141d
# 飞桨训推一体认证(TIPC)
## 1. 简介
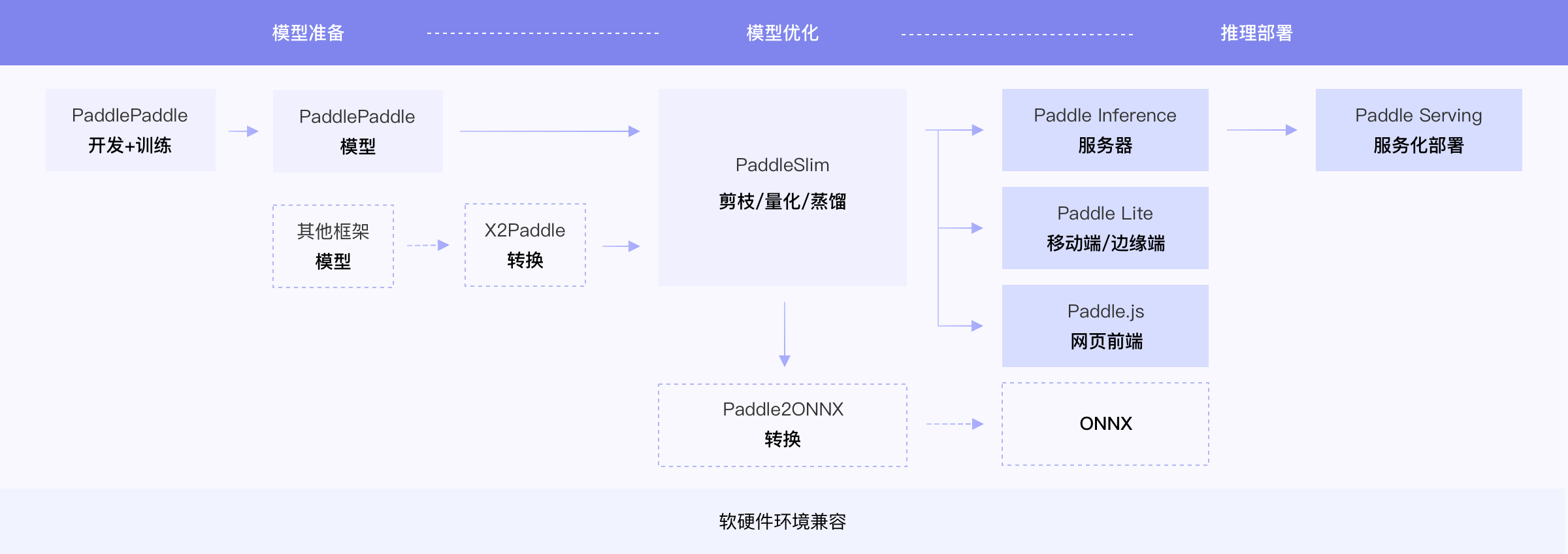
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。本文档提供了
`$repo名称$`
中所有模型的飞桨训推一体认证 (Training and Inference Pipeline Certification(TIPC)) 信息和测试工具,方便用户查阅每种模型的训练推理部署打通情况,并可以进行一键测试。
<div
align=
"center"
>
<img
src=
"docs/guide.png"
width=
"1000"
>
</div>
## 2. 汇总信息
打通情况汇总如下,已填写的部分表示可以使用本工具进行一键测试,未填写的表示正在支持中。
**字段说明:**
-
基础训练预测:包括模型训练、Paddle Inference Python预测。
-
更多训练方式:包括多机多卡、混合精度。
-
模型压缩:包括裁剪、离线/在线量化、蒸馏。
-
其他预测部署:包括Paddle Inference C++预测、Paddle Serving部署、Paddle-Lite部署等。
更详细的mkldnn、Tensorrt等预测加速相关功能的支持情况可以查看各测试工具的
[
更多教程
](
#more
)
。
| 算法论文 | 模型名称 | 模型类型 | 基础训练预测 | 更多训练方式 | 模型压缩 | 其他预测部署 |
| :--- | :--- | :----: | :--------: | :---- | :---- | :---- |
| - | - | - | - | - | - | - |
## 3. 测试工具简介
### 3.1 目录介绍
### 3.2 测试流程概述
1.
运行prepare.sh准备测试所需数据和模型;
2.
运行要测试的功能对应的测试脚本
`test_*.sh`
,产出log,由log可以看到不同配置是否运行成功;
3.
用
`compare_results.py`
对比log中的预测结果和预存在results目录下的结果,判断预测精度是否符合预期(在误差范围内)。
测试单项功能仅需两行命令,
**如需测试不同模型/功能,替换配置文件即可**
,命令格式如下:
```
shell
# 功能:准备数据
# 格式:bash + 运行脚本 + 参数1: 配置文件选择 + 参数2: 模式选择
bash test_tipc/prepare.sh configs/[model_name]/[params_file_name]
[
Mode]
# 功能:运行测试
# 格式:bash + 运行脚本 + 参数1: 配置文件选择 + 参数2: 模式选择
bash test_tipc/test_train_inference_python.sh configs/[model_name]/[params_file_name]
[
Mode]
```
例如,测试基本训练预测功能的
`lite_train_lite_infer`
模式,运行:
```
shell
# 准备数据
bash test_tipc/prepare.sh ./test_tipc/configs/
${
model_name
}
/train_infer_python.txt
'lite_train_lite_infer'
# 运行测试
bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/
${
model_name
}
/train_infer_python.txt
'lite_train_lite_infer'
```
关于本示例命令的更多信息可查看
[
基础训练预测使用文档
](
#more
)
。
### 3.3 配置文件命名规范
在
`configs`
目录下,
**按模型名称划分为子目录**
,子目录中存放所有该模型测试需要用到的配置文件,配置文件的命名遵循如下规范:
1.
基础训练预测配置简单命名为:
`train_infer_python.txt`
,表示
**Linux环境下单机、不使用混合精度训练+python预测**
,其完整命名对应
`train_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt`
,由于本配置文件使用频率较高,这里进行了名称简化。
2.
其他带训练配置命名格式为:
`train_训练硬件环境(linux_gpu/linux_dcu/…)_是否多机(fleet/normal)_是否混合精度(amp/normal)_预测模式(infer/lite/serving/js)_语言(cpp/python/java)_预测硬件环境(linux_gpu/mac/jetson/opencl_arm_gpu/...).txt`
。如,linux gpu下多机多卡+混合精度链条测试对应配置
`train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt`
,linux dcu下基础训练预测对应配置
`train_linux_dcu_normal_normal_infer_python_linux_dcu.txt`
。
3.
仅预测的配置(如serving、lite等)命名格式:
`model_训练硬件环境(linux_gpu/linux_dcu/…)_是否多机(fleet/normal)_是否混合精度(amp/normal)_(infer/lite/serving/js)_语言(cpp/python/java)_预测硬件环境(linux_gpu/mac/jetson/opencl_arm_gpu/...).txt`
,即,与2相比,仅第一个字段从train换为model,测试时模型直接下载获取,这里的“训练硬件环境”表示所测试的模型是在哪种环境下训练得到的。
**根据上述命名规范,可以直接从子目录名称和配置文件名找到需要测试的场景和功能对应的配置文件。**
<a
name=
"more"
></a>
## 4. 开始测试
各功能测试中涉及混合精度、裁剪、量化等训练相关,及mkldnn、Tensorrt等多种预测相关参数配置,请点击下方相应链接了解更多细节和使用教程:
-
[
test_train_inference_python 使用
](
docs/test_train_inference_python.md
)
:测试基于Python的模型训练、评估、推理等基本功能。
community/repo_template/test_tipc/docs/guide.png
0 → 100644
浏览文件 @
4b8c141d
138.3 KB
community/repo_template/test_tipc/docs/install.md
0 → 100644
浏览文件 @
4b8c141d
## 1. 环境准备
本教程适用于test_tipc目录下基础功能测试的运行环境搭建。
推荐环境:
-
CUDA 10.1/10.2
-
CUDNN 7.6/cudnn8.1
-
TensorRT 6.1.0.5 / 7.1 / 7.2
环境配置可以选择docker镜像安装,或者在本地环境Python搭建环境。推荐使用docker镜像安装,避免不必要的环境配置。
## 2. Docker 镜像安装
推荐docker镜像安装,按照如下命令创建镜像,当前目录映射到镜像中的
`/paddle`
目录下
```
nvidia-docker run --name paddle -it -v $PWD:/paddle paddlepaddle/paddle:latest-dev-cuda10.1-cudnn7-gcc82 /bin/bash
cd /paddle
# 安装带TRT的paddle
pip3.7 install https://paddle-wheel.bj.bcebos.com/with-trt/2.1.3/linux-gpu-cuda10.1-cudnn7-mkl-gcc8.2-trt6-avx/paddlepaddle_gpu-2.1.3.post101-cp37-cp37m-linux_x86_64.whl
```
## 3 Python 环境构建
非docker环境下,环境配置比较灵活,推荐环境组合配置:
-
CUDA10.1 + CUDNN7.6 + TensorRT 6
-
CUDA10.2 + CUDNN8.1 + TensorRT 7
-
CUDA11.1 + CUDNN8.1 + TensorRT 7
下面以 CUDA10.2 + CUDNN8.1 + TensorRT 7 配置为例,介绍环境配置的流程。
### 3.1 安装CUDNN
如果当前环境满足CUDNN版本的要求,可以跳过此步骤。
以CUDNN8.1 安装安装为例,安装步骤如下,首先下载CUDNN,从
[
Nvidia官网
](
https://developer.nvidia.com/rdp/cudnn-archive
)
下载CUDNN8.1版本,下载符合当前系统版本的三个deb文件,分别是:
-
cuDNN Runtime Library ,如:libcudnn8_8.1.0.77-1+cuda10.2_amd64.deb
-
cuDNN Developer Library ,如:libcudnn8-dev_8.1.0.77-1+cuda10.2_amd64.deb
-
cuDNN Code Samples,如:libcudnn8-samples_8.1.0.77-1+cuda10.2_amd64.deb
deb安装可以参考
[
官方文档
](
https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html#installlinux-deb
)
,安装方式如下
```
# x.x.x表示下载的版本号
# $HOME为工作目录
sudo dpkg -i libcudnn8_x.x.x-1+cudax.x_arm64.deb
sudo dpkg -i libcudnn8-dev_8.x.x.x-1+cudax.x_arm64.deb
sudo dpkg -i libcudnn8-samples_8.x.x.x-1+cudax.x_arm64.deb
# 验证是否正确安装
cp -r /usr/src/cudnn_samples_v8/ $HOME
cd $HOME/cudnn_samples_v8/mnistCUDNN
# 编译
make clean && make
./mnistCUDNN
```
如果运行mnistCUDNN完后提示运行成功,则表示安装成功。如果运行后出现freeimage相关的报错,需要按照提示安装freeimage库:
```
sudo apt-get install libfreeimage-dev
sudo apt-get install libfreeimage
```
### 3.2 安装TensorRT
首先,从
[
Nvidia官网TensorRT板块
](
https://developer.nvidia.com/tensorrt-getting-started
)
下载TensorRT,这里选择7.1.3.4版本的TensorRT,注意选择适合自己系统版本和CUDA版本的TensorRT,另外建议下载TAR package的安装包。
以Ubuntu16.04+CUDA10.2为例,下载并解压后可以参考
[
官方文档
](
https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-713/install-guide/index.html#installing-tar
)
的安装步骤,按照如下步骤安装:
```
# 以下安装命令中 '${version}' 为下载的TensorRT版本,如7.1.3.4
# 设置环境变量,<TensorRT-${version}/lib> 为解压后的TensorRT的lib目录
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<TensorRT-${version}/lib>
# 安装TensorRT
cd TensorRT-${version}/python
pip3.7 install tensorrt-*-cp3x-none-linux_x86_64.whl
# 安装graphsurgeon
cd TensorRT-${version}/graphsurgeon
```
### 3.3 安装PaddlePaddle
下载支持TensorRT版本的Paddle安装包,注意安装包的TensorRT版本需要与本地TensorRT一致,下载
[
链接
](
https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#python
)
选择下载 linux-cuda10.2-trt7-gcc8.2 Python3.7版本的Paddle:
```
# 从下载链接中可以看到是paddle2.1.1-cuda10.2-cudnn8.1版本
wget https://paddle-wheel.bj.bcebos.com/with-trt/2.1.1-gpu-cuda10.2-cudnn8.1-mkl-gcc8.2/paddlepaddle_gpu-2.1.1-cp37-cp37m-linux_x86_64.whl
pip3.7 install -U paddlepaddle_gpu-2.1.1-cp37-cp37m-linux_x86_64.whl
```
## 4. 安装依赖
```
shell
# 安装AutoLog
git clone https://github.com/LDOUBLEV/AutoLog
cd
AutoLog
pip3.7
install
-r
requirements.txt
python3.7 setup.py bdist_wheel
pip3.7
install
./dist/auto_log-1.0.0-py3-none-any.whl
```
安装本项目依赖:
```
# 下载本项目代码
git clone $repo_link
# 进入repo文件夹
cd $repo_name
# 安装依赖
pip3.7 install -r requirements.txt
```
## FAQ :
Q. You are using Paddle compiled with TensorRT, but TensorRT dynamic library is not found. Ignore this if TensorRT is not needed.
A. 问题一般是当前安装paddle版本带TRT,但是本地环境找不到TensorRT的预测库,需要下载TensorRT库,解压后设置环境变量LD_LIBRARY_PATH;
如:
```
export LD_LIBRARY_PATH=/usr/local/python3.7.0/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/paddle/package/TensorRT-6.0.1.5/lib
```
或者问题是下载的TensorRT版本和当前paddle中编译的TRT版本不匹配,需要下载版本相符的TensorRT重新安装。
community/repo_template/test_tipc/docs/test_train_inference_python.md
0 → 100644
浏览文件 @
4b8c141d
# Linux端基础训练预测功能测试
Linux端基础训练预测功能测试的主程序为
`test_train_inference_python.sh`
,可以测试基于Python的模型训练、评估、推理等基本功能,包括裁剪、量化、蒸馏。
其中裁剪、量化、蒸馏非必须。
## 1. 测试结论汇总
-
训练相关:
| 算法名称 | 模型名称 | 单机单卡 | 单机多卡 | 多机多卡 | 模型压缩(单机多卡) |
| :---- | :---- | :---- | :---- | :---- | :---- |
| - | - | - | - | - | - |
-
预测相关:基于训练是否使用量化,可以将训练产出的模型可以分为
`正常模型`
和
`量化模型`
,这两类模型对应的预测功能汇总如下,
| 模型类型 | device | batchsize | tensorrt | mkldnn | cpu多线程 |
| ---- | ---- | ---- | :----: | :----: | :----: |
| - | | -/- | - | - | - |
| - | - | -/- | - | - | - |
## 2. 测试流程
运行环境配置请参考
[
文档
](
./install.md
)
的内容配置TIPC的运行环境。
### 2.1 安装依赖
-
安装PaddlePaddle >= 2.1
-
安装本项目依赖
```
pip3 install -r ../requirements.txt
```
-
安装autolog(规范化日志输出工具)
```
git clone https://github.com/LDOUBLEV/AutoLog
cd AutoLog
pip3 install -r requirements.txt
python3 setup.py bdist_wheel
pip3 install ./dist/auto_log-1.0.0-py3-none-any.whl
cd ../
```
-
安装PaddleSlim (可选)
```
# 如果要测试量化、裁剪等功能,需要安装PaddleSlim
pip3 install paddleslim
```
### 2.2 功能测试
先运行
`prepare.sh`
准备数据和模型,然后运行
`test_train_inference_python.sh`
进行测试,最终在
`test_tipc/output`
目录下生成
`python_infer_*.log`
格式的日志文件。
`test_train_inference_python.sh`
包含5种运行模式,每种模式的运行数据不同,分别用于测试速度和精度,这里只需要实现模式:
`lite_train_lite_infer`
,具体说明如下。
-
模式:lite_train_lite_infer,使用少量数据训练,用于快速验证训练到预测的走通流程,不验证精度和速度;
```
shell
# 准备环境
bash test_tipc/prepare.sh ./test_tipc/configs/
$model_name
/train_infer_python.txt
'lite_train_lite_infer'
# 基于准备好的配置文件进行验证
bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/config.txt
'lite_train_lite_infer'
```
运行相应指令后,在
`test_tipc/output`
文件夹下自动会保存运行日志。如
`lite_train_lite_infer`
模式下,会运行
`训练+inference`
的链条,因此,在
`test_tipc/output`
文件夹有以下文件:
```
test_tipc/output/
|- results_python.log # 运行指令状态的日志
|- norm_train_gpus_0_autocast_null/ # GPU 0号卡上正常训练的训练日志和模型保存文件夹
......
```
其他模式中其中
`results_python.log`
中包含了每条指令的运行状态,如果运行成功会输出:
```
Run successfully with xxxxx
......
```
如果运行失败,会输出:
```
Run failed with xxxxx
......
```
可以很方便的根据
`results_python.log`
中的内容判定哪一个指令运行错误。
## 3. 更多教程
本文档为功能测试用,更丰富的训练预测使用教程请参考:
-
[
模型训练
](
../../README.md
)
-
[
基于Python预测引擎推理
](
../../deploy/pdinference/README.md
)
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}