You need to sign in or sign up before continuing.
Merge pull request #3 from PaddlePaddle/develop
merge from master
Showing
{kind=link}
{kind=link}
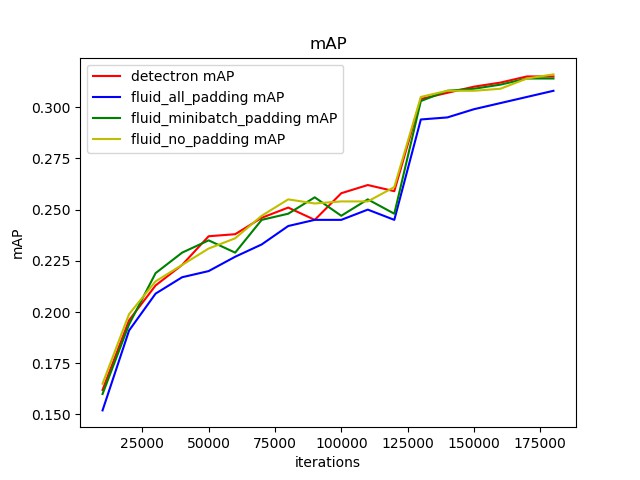
| W: | H:
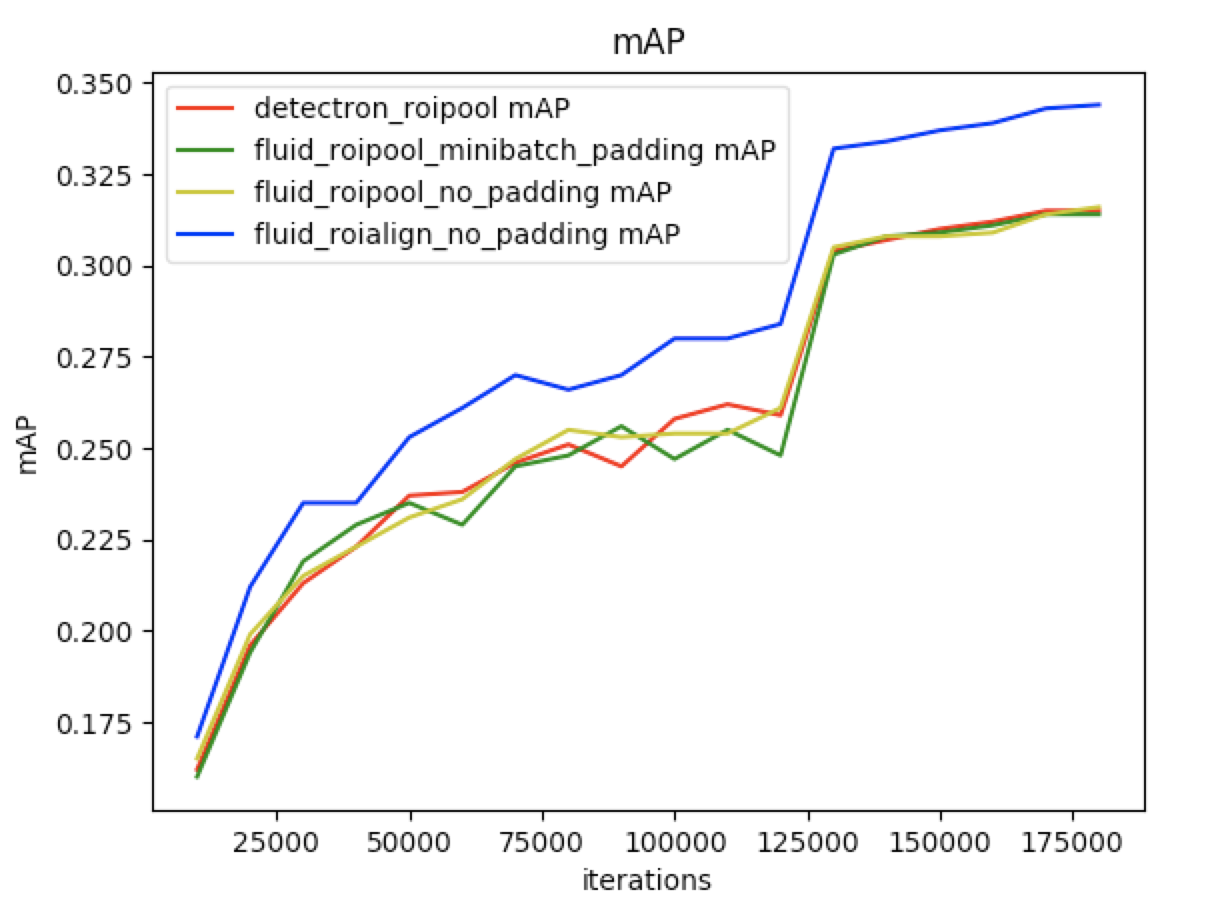
| W: | H:
{kind=link}
{kind=link}
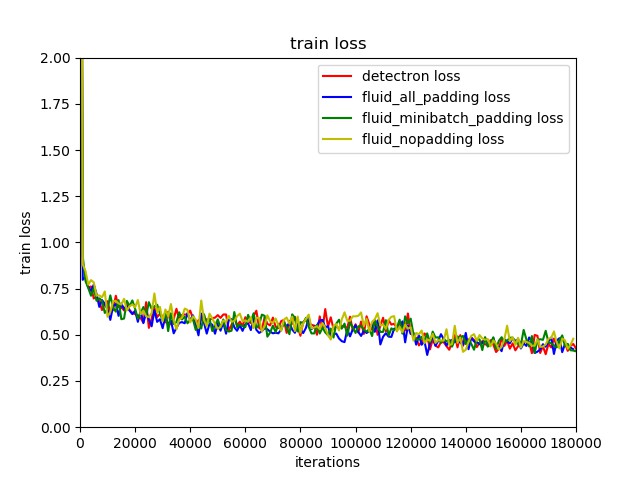
| W: | H:
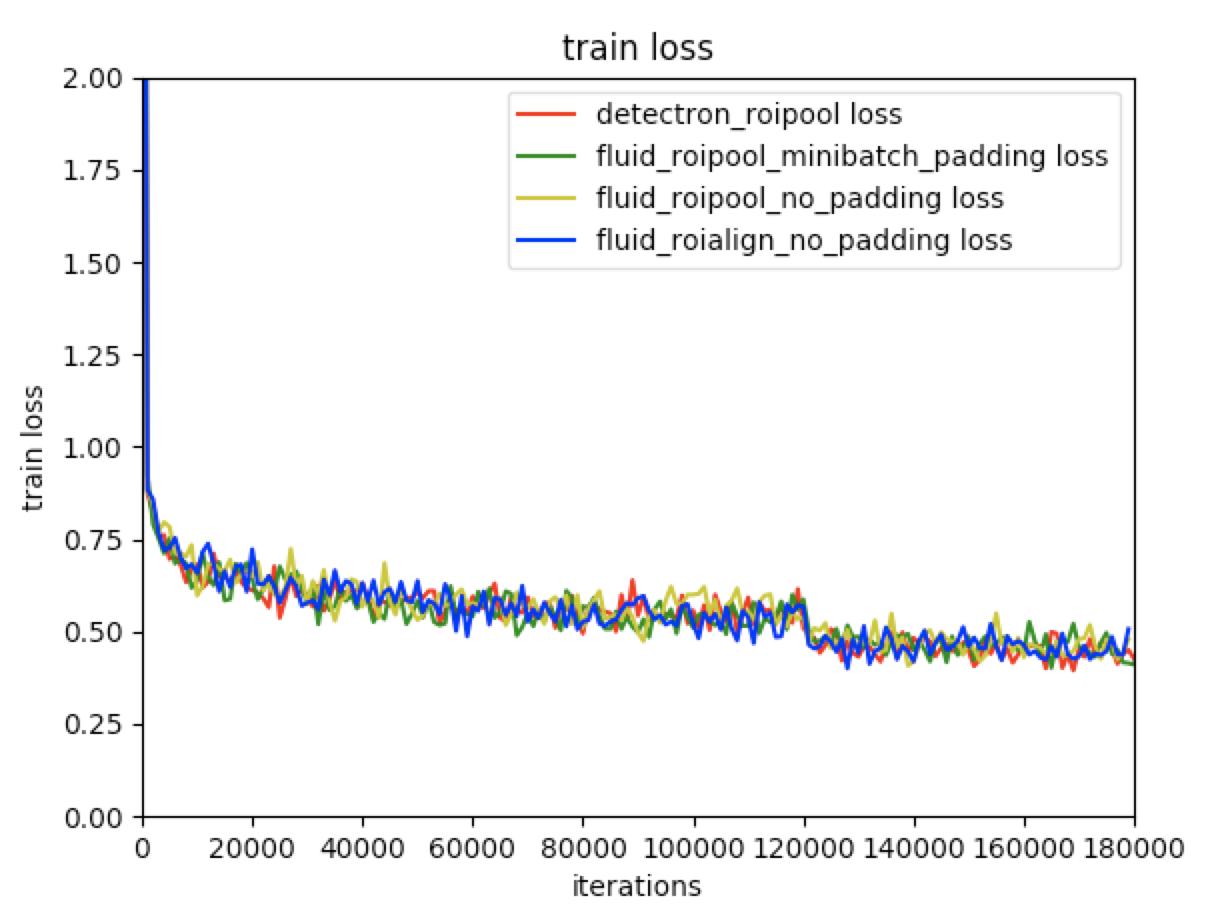
| W: | H:
fluid/recommendation/ctr/infer.py
0 → 100644
fluid/recommendation/ctr/train.py
0 → 100644