Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
377c6d32
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
377c6d32
编写于
4月 12, 2019
作者:
Z
Zhen Wang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add GoogleNet support add quant low level api usage doc.
上级
3da08c99
变更
10
隐藏空白更改
内联
并排
Showing
10 changed file
with
413 addition
and
3 deletion
+413
-3
PaddleSlim/docs/images/usage/ConvertToInt8Pass.png
PaddleSlim/docs/images/usage/ConvertToInt8Pass.png
+0
-0
PaddleSlim/docs/images/usage/FreezePass.png
PaddleSlim/docs/images/usage/FreezePass.png
+0
-0
PaddleSlim/docs/images/usage/TransformForMobilePass.png
PaddleSlim/docs/images/usage/TransformForMobilePass.png
+0
-0
PaddleSlim/docs/images/usage/TransformPass.png
PaddleSlim/docs/images/usage/TransformPass.png
+0
-0
PaddleSlim/docs/usage.md
PaddleSlim/docs/usage.md
+9
-0
PaddleSlim/models/__init__.py
PaddleSlim/models/__init__.py
+1
-0
PaddleSlim/models/googlenet.py
PaddleSlim/models/googlenet.py
+233
-0
PaddleSlim/quant_low_level_api/README.md
PaddleSlim/quant_low_level_api/README.md
+160
-0
PaddleSlim/quant_low_level_api/quant.py
PaddleSlim/quant_low_level_api/quant.py
+1
-1
PaddleSlim/quant_low_level_api/run_quant.sh
PaddleSlim/quant_low_level_api/run_quant.sh
+9
-2
未找到文件。
PaddleSlim/docs/images/usage/ConvertToInt8Pass.png
0 → 100644
浏览文件 @
377c6d32
85.6 KB
PaddleSlim/docs/images/usage/FreezePass.png
0 → 100644
浏览文件 @
377c6d32
110.9 KB
PaddleSlim/docs/images/usage/TransformForMobilePass.png
0 → 100644
浏览文件 @
377c6d32
91.4 KB
PaddleSlim/docs/images/usage/TransformPass.png
0 → 100644
浏览文件 @
377c6d32
132.4 KB
PaddleSlim/docs/usage.md
浏览文件 @
377c6d32
...
@@ -215,6 +215,10 @@ compress_pass:
...
@@ -215,6 +215,10 @@ compress_pass:
### 2.1 量化训练
### 2.1 量化训练
**用户须知:**
现阶段的量化训练主要针对卷积层(包括二维卷积和Depthwise卷积)以及全连接层进行量化。卷积层和全连接层在PaddlePaddle框架中对应算子包括
`conv2d`
、
`depthwise_conv2d`
和
`mul`
等。量化训练会对所有的
`conv2d`
、
`depthwise_conv2d`
和
`mul`
进行量化操作,且要求它们的输入中必须包括激活和参数两部分。
#### 2.1.1 基于High-Level API的量化训练
>注意:多个压缩策略组合使用时,量化训练策略必须放在最后。
>注意:多个压缩策略组合使用时,量化训练策略必须放在最后。
```
```
...
@@ -279,6 +283,11 @@ strategies:
...
@@ -279,6 +283,11 @@ strategies:
-
**save_in_nodes:**
variable名称列表。在保存量化后模型的时候,需要根据save_in_nodes对eval programg 网络进行前向遍历剪枝。默认为eval_feed_list内指定的variable的名称列表。
-
**save_in_nodes:**
variable名称列表。在保存量化后模型的时候,需要根据save_in_nodes对eval programg 网络进行前向遍历剪枝。默认为eval_feed_list内指定的variable的名称列表。
-
**save_out_nodes:**
varibale名称列表。在保存量化后模型的时候,需要根据save_out_nodes对eval programg 网络进行回溯剪枝。默认为eval_fetch_list内指定的variable的名称列表。
-
**save_out_nodes:**
varibale名称列表。在保存量化后模型的时候,需要根据save_out_nodes对eval programg 网络进行回溯剪枝。默认为eval_fetch_list内指定的variable的名称列表。
#### 2.1.2 基于Low-Level API的量化训练
量化训练High-Level API是对Low-Level API的高层次封装,这使得用户仅需编写少量的代码和配置文件即可进行量化训练。然而,封装必然会带来使用灵活性的降低。因此,若用户在进行量化训练时需要更多的灵活性,可参考
[
量化训练Low-Level API使用示例
](
../quant_low_level_api/README.md
)
。
### 2.2 卷积核剪切
### 2.2 卷积核剪切
该策略通过减少指定卷积层中卷积核的数量,达到缩减模型大小和计算复杂度的目的。根据选取剪切比例的策略的不同,又细分为以下两个方式:
该策略通过减少指定卷积层中卷积核的数量,达到缩减模型大小和计算复杂度的目的。根据选取剪切比例的策略的不同,又细分为以下两个方式:
...
...
PaddleSlim/models/__init__.py
浏览文件 @
377c6d32
from
.mobilenet
import
MobileNet
from
.mobilenet
import
MobileNet
from
.resnet
import
ResNet50
,
ResNet101
,
ResNet152
from
.resnet
import
ResNet50
,
ResNet101
,
ResNet152
from
.googlenet
import
GoogleNet
PaddleSlim/models/googlenet.py
0 → 100644
浏览文件 @
377c6d32
from
__future__
import
absolute_import
from
__future__
import
division
from
__future__
import
print_function
import
paddle
import
paddle.fluid
as
fluid
from
paddle.fluid.param_attr
import
ParamAttr
__all__
=
[
'GoogleNet'
]
train_parameters
=
{
"input_size"
:
[
3
,
224
,
224
],
"input_mean"
:
[
0.485
,
0.456
,
0.406
],
"input_std"
:
[
0.229
,
0.224
,
0.225
],
"learning_strategy"
:
{
"name"
:
"piecewise_decay"
,
"batch_size"
:
256
,
"epochs"
:
[
30
,
70
,
100
],
"steps"
:
[
0.1
,
0.01
,
0.001
,
0.0001
]
}
}
class
GoogleNet
():
def
__init__
(
self
):
self
.
params
=
train_parameters
def
conv_layer
(
self
,
input
,
num_filters
,
filter_size
,
stride
=
1
,
groups
=
1
,
act
=
None
,
name
=
None
):
channels
=
input
.
shape
[
1
]
stdv
=
(
3.0
/
(
filter_size
**
2
*
channels
))
**
0.5
param_attr
=
ParamAttr
(
initializer
=
fluid
.
initializer
.
Uniform
(
-
stdv
,
stdv
),
name
=
name
+
"_weights"
)
conv
=
fluid
.
layers
.
conv2d
(
input
=
input
,
num_filters
=
num_filters
,
filter_size
=
filter_size
,
stride
=
stride
,
padding
=
(
filter_size
-
1
)
//
2
,
groups
=
groups
,
act
=
act
,
param_attr
=
param_attr
,
bias_attr
=
False
,
name
=
name
)
return
conv
def
xavier
(
self
,
channels
,
filter_size
,
name
):
stdv
=
(
3.0
/
(
filter_size
**
2
*
channels
))
**
0.5
param_attr
=
ParamAttr
(
initializer
=
fluid
.
initializer
.
Uniform
(
-
stdv
,
stdv
),
name
=
name
+
"_weights"
)
return
param_attr
def
inception
(
self
,
input
,
channels
,
filter1
,
filter3R
,
filter3
,
filter5R
,
filter5
,
proj
,
name
=
None
):
conv1
=
self
.
conv_layer
(
input
=
input
,
num_filters
=
filter1
,
filter_size
=
1
,
stride
=
1
,
act
=
None
,
name
=
"inception_"
+
name
+
"_1x1"
)
conv3r
=
self
.
conv_layer
(
input
=
input
,
num_filters
=
filter3R
,
filter_size
=
1
,
stride
=
1
,
act
=
None
,
name
=
"inception_"
+
name
+
"_3x3_reduce"
)
conv3
=
self
.
conv_layer
(
input
=
conv3r
,
num_filters
=
filter3
,
filter_size
=
3
,
stride
=
1
,
act
=
None
,
name
=
"inception_"
+
name
+
"_3x3"
)
conv5r
=
self
.
conv_layer
(
input
=
input
,
num_filters
=
filter5R
,
filter_size
=
1
,
stride
=
1
,
act
=
None
,
name
=
"inception_"
+
name
+
"_5x5_reduce"
)
conv5
=
self
.
conv_layer
(
input
=
conv5r
,
num_filters
=
filter5
,
filter_size
=
5
,
stride
=
1
,
act
=
None
,
name
=
"inception_"
+
name
+
"_5x5"
)
pool
=
fluid
.
layers
.
pool2d
(
input
=
input
,
pool_size
=
3
,
pool_stride
=
1
,
pool_padding
=
1
,
pool_type
=
'max'
)
convprj
=
fluid
.
layers
.
conv2d
(
input
=
pool
,
filter_size
=
1
,
num_filters
=
proj
,
stride
=
1
,
padding
=
0
,
name
=
"inception_"
+
name
+
"_3x3_proj"
,
param_attr
=
ParamAttr
(
name
=
"inception_"
+
name
+
"_3x3_proj_weights"
),
bias_attr
=
False
)
cat
=
fluid
.
layers
.
concat
(
input
=
[
conv1
,
conv3
,
conv5
,
convprj
],
axis
=
1
)
cat
=
fluid
.
layers
.
relu
(
cat
)
return
cat
def
net
(
self
,
input
,
class_dim
=
1000
):
conv
=
self
.
conv_layer
(
input
=
input
,
num_filters
=
64
,
filter_size
=
7
,
stride
=
2
,
act
=
None
,
name
=
"conv1"
)
pool
=
fluid
.
layers
.
pool2d
(
input
=
conv
,
pool_size
=
3
,
pool_type
=
'max'
,
pool_stride
=
2
)
conv
=
self
.
conv_layer
(
input
=
pool
,
num_filters
=
64
,
filter_size
=
1
,
stride
=
1
,
act
=
None
,
name
=
"conv2_1x1"
)
conv
=
self
.
conv_layer
(
input
=
conv
,
num_filters
=
192
,
filter_size
=
3
,
stride
=
1
,
act
=
None
,
name
=
"conv2_3x3"
)
pool
=
fluid
.
layers
.
pool2d
(
input
=
conv
,
pool_size
=
3
,
pool_type
=
'max'
,
pool_stride
=
2
)
ince3a
=
self
.
inception
(
pool
,
192
,
64
,
96
,
128
,
16
,
32
,
32
,
"ince3a"
)
ince3b
=
self
.
inception
(
ince3a
,
256
,
128
,
128
,
192
,
32
,
96
,
64
,
"ince3b"
)
pool3
=
fluid
.
layers
.
pool2d
(
input
=
ince3b
,
pool_size
=
3
,
pool_type
=
'max'
,
pool_stride
=
2
)
ince4a
=
self
.
inception
(
pool3
,
480
,
192
,
96
,
208
,
16
,
48
,
64
,
"ince4a"
)
ince4b
=
self
.
inception
(
ince4a
,
512
,
160
,
112
,
224
,
24
,
64
,
64
,
"ince4b"
)
ince4c
=
self
.
inception
(
ince4b
,
512
,
128
,
128
,
256
,
24
,
64
,
64
,
"ince4c"
)
ince4d
=
self
.
inception
(
ince4c
,
512
,
112
,
144
,
288
,
32
,
64
,
64
,
"ince4d"
)
ince4e
=
self
.
inception
(
ince4d
,
528
,
256
,
160
,
320
,
32
,
128
,
128
,
"ince4e"
)
pool4
=
fluid
.
layers
.
pool2d
(
input
=
ince4e
,
pool_size
=
3
,
pool_type
=
'max'
,
pool_stride
=
2
)
ince5a
=
self
.
inception
(
pool4
,
832
,
256
,
160
,
320
,
32
,
128
,
128
,
"ince5a"
)
ince5b
=
self
.
inception
(
ince5a
,
832
,
384
,
192
,
384
,
48
,
128
,
128
,
"ince5b"
)
pool5
=
fluid
.
layers
.
pool2d
(
input
=
ince5b
,
pool_size
=
7
,
pool_type
=
'avg'
,
pool_stride
=
7
)
dropout
=
fluid
.
layers
.
dropout
(
x
=
pool5
,
dropout_prob
=
0.4
)
out
=
fluid
.
layers
.
fc
(
input
=
dropout
,
size
=
class_dim
,
act
=
'softmax'
,
param_attr
=
self
.
xavier
(
1024
,
1
,
"out"
),
name
=
"out"
,
bias_attr
=
ParamAttr
(
name
=
"out_offset"
))
pool_o1
=
fluid
.
layers
.
pool2d
(
input
=
ince4a
,
pool_size
=
5
,
pool_type
=
'avg'
,
pool_stride
=
3
)
conv_o1
=
self
.
conv_layer
(
input
=
pool_o1
,
num_filters
=
128
,
filter_size
=
1
,
stride
=
1
,
act
=
None
,
name
=
"conv_o1"
)
fc_o1
=
fluid
.
layers
.
fc
(
input
=
conv_o1
,
size
=
1024
,
act
=
'relu'
,
param_attr
=
self
.
xavier
(
2048
,
1
,
"fc_o1"
),
name
=
"fc_o1"
,
bias_attr
=
ParamAttr
(
name
=
"fc_o1_offset"
))
dropout_o1
=
fluid
.
layers
.
dropout
(
x
=
fc_o1
,
dropout_prob
=
0.7
)
out1
=
fluid
.
layers
.
fc
(
input
=
dropout_o1
,
size
=
class_dim
,
act
=
'softmax'
,
param_attr
=
self
.
xavier
(
1024
,
1
,
"out1"
),
name
=
"out1"
,
bias_attr
=
ParamAttr
(
name
=
"out1_offset"
))
pool_o2
=
fluid
.
layers
.
pool2d
(
input
=
ince4d
,
pool_size
=
5
,
pool_type
=
'avg'
,
pool_stride
=
3
)
conv_o2
=
self
.
conv_layer
(
input
=
pool_o2
,
num_filters
=
128
,
filter_size
=
1
,
stride
=
1
,
act
=
None
,
name
=
"conv_o2"
)
fc_o2
=
fluid
.
layers
.
fc
(
input
=
conv_o2
,
size
=
1024
,
act
=
'relu'
,
param_attr
=
self
.
xavier
(
2048
,
1
,
"fc_o2"
),
name
=
"fc_o2"
,
bias_attr
=
ParamAttr
(
name
=
"fc_o2_offset"
))
dropout_o2
=
fluid
.
layers
.
dropout
(
x
=
fc_o2
,
dropout_prob
=
0.7
)
out2
=
fluid
.
layers
.
fc
(
input
=
dropout_o2
,
size
=
class_dim
,
act
=
'softmax'
,
param_attr
=
self
.
xavier
(
1024
,
1
,
"out2"
),
name
=
"out2"
,
bias_attr
=
ParamAttr
(
name
=
"out2_offset"
))
# last fc layer is "out"
return
out
,
out1
,
out2
PaddleSlim/quant_low_level_api/README.md
0 → 100644
浏览文件 @
377c6d32
<div
align=
"center"
>
<h3>
<a
href=
"../docs/tutorial.md"
>
算法原理介绍
</a>
<span>
|
</span>
<a
href=
"../docs/usage.md"
>
使用文档
</a>
<span>
|
</span>
<a
href=
"../docs/demo.md"
>
示例文档
</a>
<span>
|
</span>
<a
href=
"../docs/model_zoo.md"
>
Model Zoo
</a>
</h3>
</div>
---
# 量化训练Low-Level API使用示例
## 目录
-
[
量化训练Low-Level APIs介绍
](
#1-量化训练low-level-apis介绍
)
-
[
基于Low-Level API的量化训练
](
#2-基于low-level-api的量化训练
)
## 1. 量化训练Low-Level APIs介绍
量化训练Low-Level APIs主要涉及到PaddlePaddle框架中的四个IrPass,即
`QuantizationTransformPass`
、
`QuantizationFreezePass`
、
`ConvertToInt8Pass`
以及
`TransformForMobilePass`
。这四个IrPass的具体功能描述如下:
*
`QuantizationTransformPass`
: QuantizationTransformPass主要负责在IrGraph的
`conv2d`
、
`depthwise_conv2d`
、
`mul`
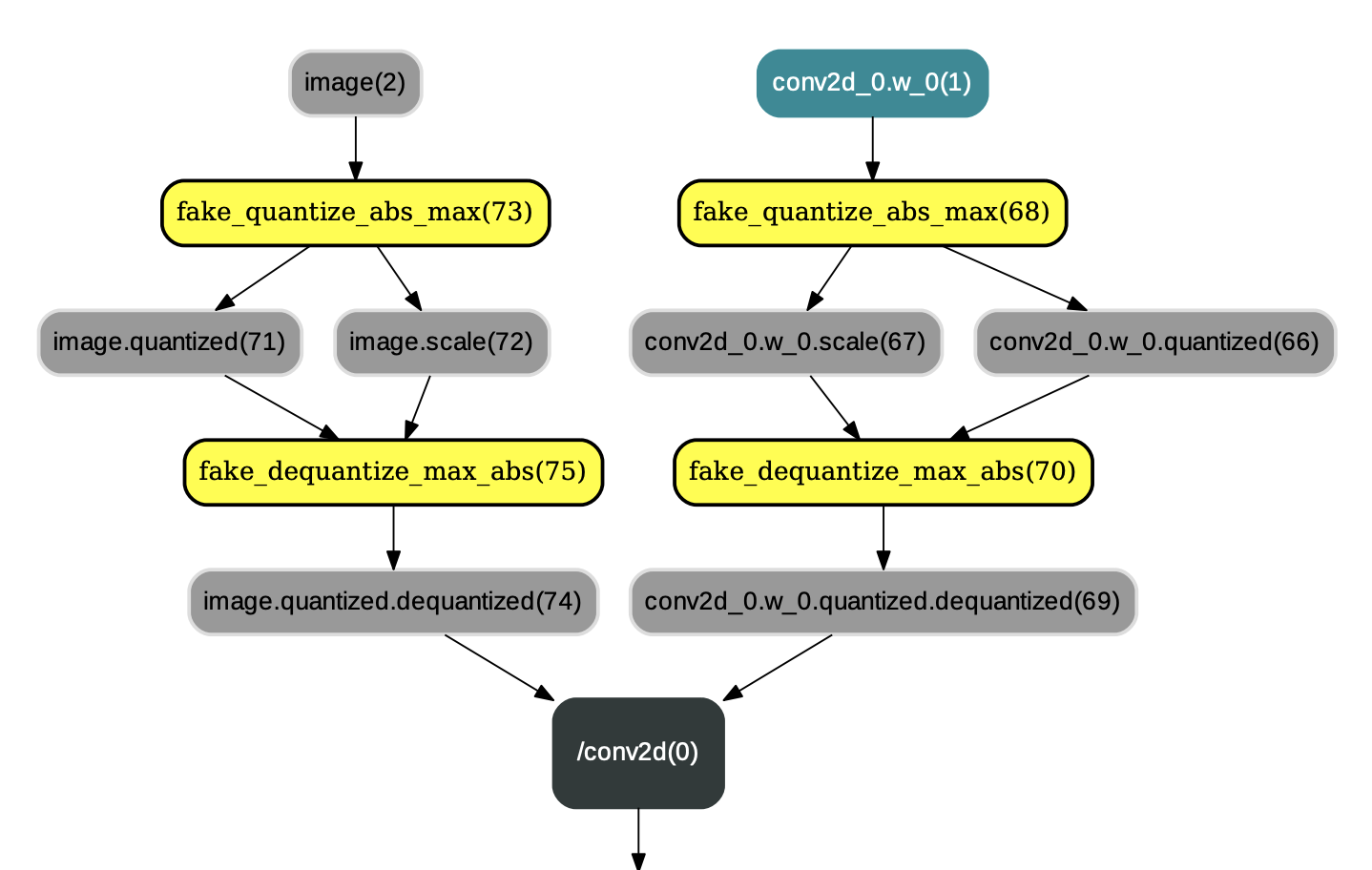
等算子的各个输入前插入连续的量化op和反量化op,并改变相应反向算子的某些输入,示例如图1:
<p
align=
"center"
>
<img
src=
"../docs/images/usage/TransformPass.png"
height=
400
width=
520
hspace=
'10'
/>
<br
/>
<strong>
图1:应用QuantizationTransformPass后的结果
</strong>
</p>
*
`QuantizationFreezePass`
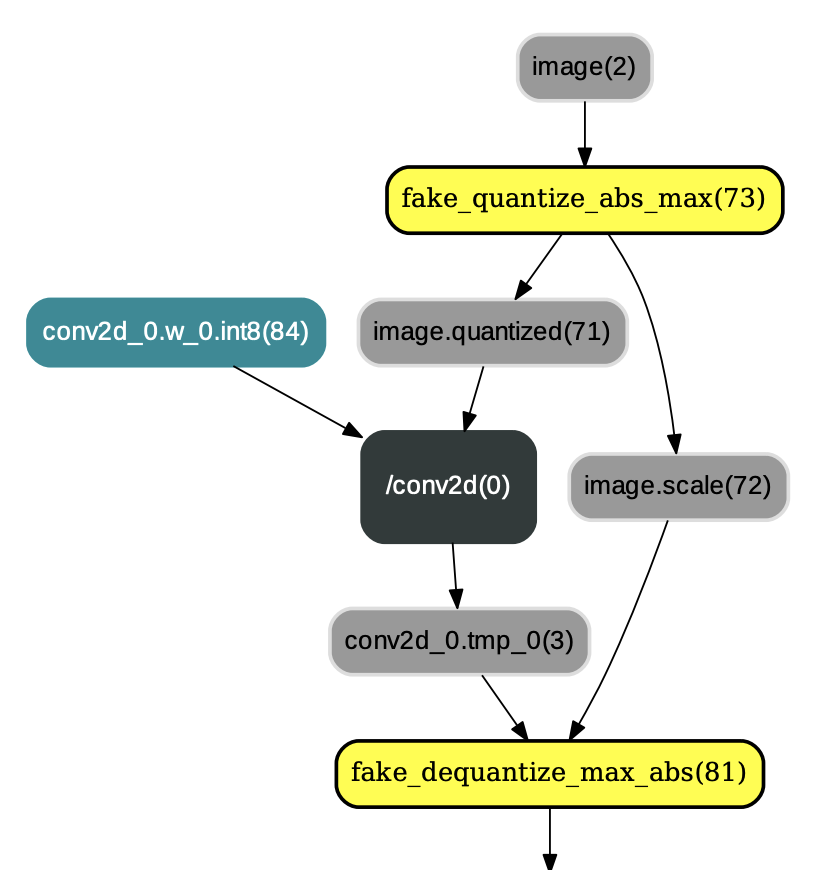
:QuantizationFreezePass主要用于改变IrGraph中量化op和反量化op的顺序,即将类似图1中的量化op和反量化op顺序改变为图2中的布局。除此之外,QuantizationFreezePass还会将
`conv2d`
、
`depthwise_conv2d`
、
`mul`
等算子的权重离线量化为int8_t范围内的值(但数据类型仍为float32),以减少预测过程中对权重的量化操作,示例如图2:
<p
align=
"center"
>
<img
src=
"../docs/images/usage/FreezePass.png"
height=
400
width=
420
hspace=
'10'
/>
<br
/>
<strong>
图2:应用QuantizationFreezePass后的结果
</strong>
</p>
*
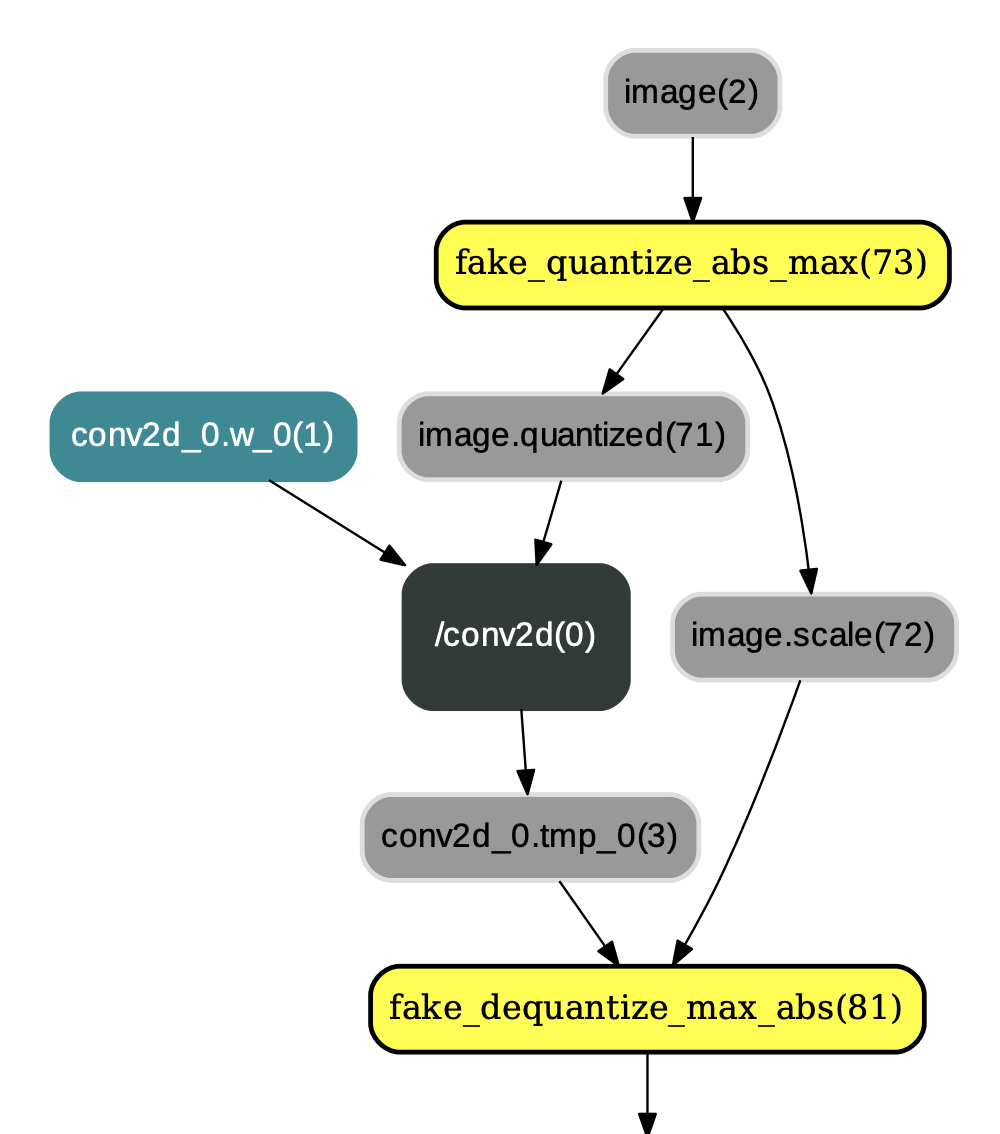
`ConvertToInt8Pass`
:ConvertToInt8Pass必须在QuantizationFreezePass之后执行,其主要目的是将执行完QuantizationFreezePass后输出的权重类型由
`FP32`
更改为
`INT8`
。换言之,用户可以选择将量化后的权重保存为float32类型(不执行ConvertToInt8Pass)或者int8_t类型(执行ConvertToInt8Pass),示例如图3:
<p
align=
"center"
>
<img
src=
"../docs/images/usage/ConvertToInt8Pass.png"
height=
400
width=
400
hspace=
'10'
/>
<br
/>
<strong>
图3:应用ConvertToInt8Pass后的结果
</strong>
</p>
*
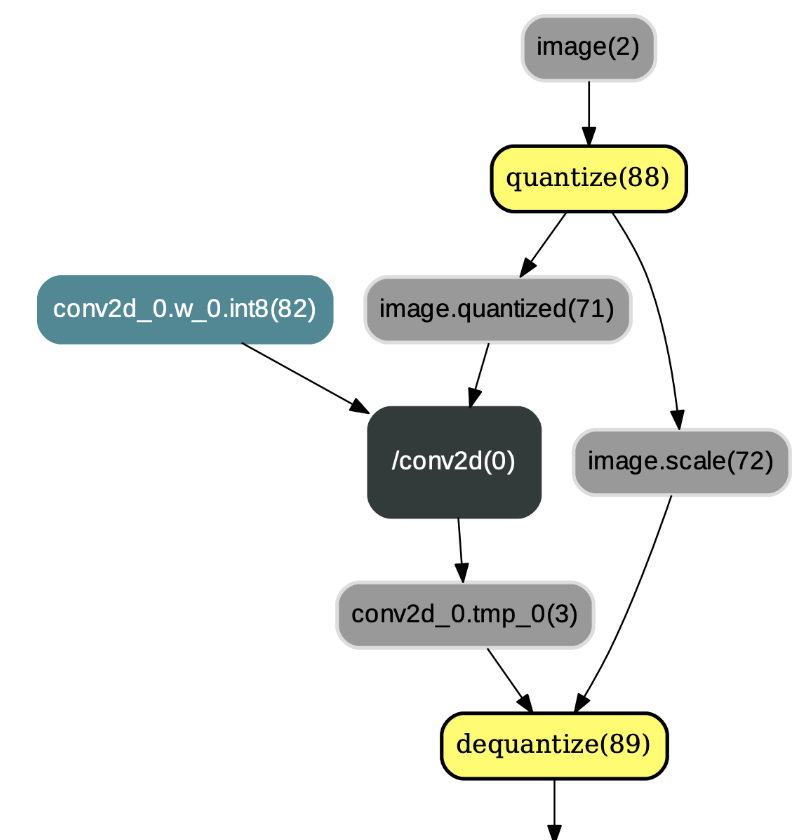
`TransformForMobilePass`
:经TransformForMobilePass转换后,用户可得到兼容
[
paddle-mobile
](
https://github.com/PaddlePaddle/paddle-mobile
)
移动端预测库的量化模型。paddle-mobile中的量化op和反量化op的名称分别为
`quantize`
和
`dequantize`
。
`quantize`
算子和PaddlePaddle框架中的
`fake_quantize_abs_max`
算子簇的功能类似,
`dequantize`
算子和PaddlePaddle框架中的
`fake_dequantize_max_abs`
算子簇的功能相同。若选择paddle-mobile执行量化训练输出的模型,则需要将
`fake_quantize_abs_max`
等算子改为
`quantize`
算子以及将
`fake_dequantize_max_abs`
等算子改为
`dequantize`
算子,示例如图4:
<p
align=
"center"
>
<img
src=
"../docs/images/usage/TransformForMobilePass.png"
height=
400
width=
400
hspace=
'10'
/>
<br
/>
<strong>
图4:应用TransformForMobilePass后的结果
</strong>
</p>
## 2. 基于Low-Level API的量化训练
本小节以ResNet50和MobileNetV1为例,介绍了PaddlePaddle量化训练Low-Level API的使用方法,具体如下:
1) 执行如下命令clone
[
Pddle models repo
](
https://github.com/PaddlePaddle/models
)
:
```
bash
git clone https://github.com/PaddlePaddle/models.git
```
2) 准备数据集(包括训练数据集和验证数据集)。以ILSVRC2012数据集为例,数据集应包含如下结构:
```
bash
data
└──ILSVRC2012
├── train
├── train_list.txt
├── val
└── val_list.txt
```
3)切换到
`models/PaddleSlim/quant_low_level_api`
目录下,修改
`run_quant.sh`
内容,即将
**data_dir**
设置为第2)步所准备的数据集路径。最后,执行
`run_quant.sh`
脚本即可进行量化训练。
### 2.1 量化训练Low-Level API使用小结:
*
参照
[
quant.py
](
quant.py
)
文件的内容,总结使用量化训练Low-Level API的方法如下:
```
python
#startup_program = fluid.Program()
#train_program = fluid.Program()
#train_cost = build_program(
# main_prog=train_program,
# startup_prog=startup_program,
# is_train=True)
#build_program(
# main_prog=test_program,
# startup_prog=startup_program,
# is_train=False)
#test_program = test_program.clone(for_test=True)
# The above pseudo code is used to build up the model.
# ---------------------------------------------------------------------------------
# The following code are part of Quantization Aware Training logic:
# 0) Convert Programs to IrGraphs.
main_graph
=
IrGraph
(
core
.
Graph
(
train_program
.
desc
),
for_test
=
False
)
test_graph
=
IrGraph
(
core
.
Graph
(
test_program
.
desc
),
for_test
=
True
)
# 1) Make some quantization transforms in the graph before training and testing.
# According to the weight and activation quantization type, the graph will be added
# some fake quantize operators and fake dequantize operators.
transform_pass
=
QuantizationTransformPass
(
scope
=
fluid
.
global_scope
(),
place
=
place
,
activation_quantize_type
=
activation_quant_type
,
weight_quantize_type
=
weight_quant_type
)
transform_pass
.
apply
(
main_graph
)
transform_pass
.
apply
(
test_graph
)
# Compile the train_graph for training.
binary
=
fluid
.
CompiledProgram
(
main_graph
.
graph
).
with_data_parallel
(
loss_name
=
train_cost
.
name
,
build_strategy
=
build_strategy
)
# Convert the transformed test_graph to test program for testing.
test_prog
=
test_graph
.
to_program
()
# For training
exe
.
run
(
binary
,
fetch_list
=
train_fetch_list
)
# For testing
exe
.
run
(
program
=
test_prog
,
fetch_list
=
test_fetch_list
)
# 2) Freeze the graph after training by adjusting the quantize
# operators' order for the inference.
freeze_pass
=
QuantizationFreezePass
(
scope
=
fluid
.
global_scope
(),
place
=
place
,
weight_quantize_type
=
weight_quant_type
)
freeze_pass
.
apply
(
test_graph
)
# 3) Convert the weights into int8_t type.
# [This step is optional.]
convert_int8_pass
=
ConvertToInt8Pass
(
scope
=
fluid
.
global_scope
(),
place
=
place
)
convert_int8_pass
.
apply
(
test_graph
)
# 4) Convert the freezed graph for paddle-mobile execution.
# [This step is optional. But, if you execute this step, you must execute the step 3).]
mobile_pass
=
TransformForMobilePass
()
mobile_pass
.
apply
(
test_graph
)
```
*
[
run_quant.sh
](
run_quant.sh
)
脚本中的命令配置详解:
```
bash
--model
:指定量化训练的模型,如MobileNet、ResNet50。
--pretrained_fp32_model
:指定预训练float32模型参数的位置。
--checkpoint
:指定模型断点训练的checkpoint路径。若指定了checkpoint路径,则不应该再指定pretrained_fp32_model路径。
--use_gpu
:选择是否使用GPU训练。
--data_dir
:指定训练数据集和验证数据集的位置。
--batch_size
:设置训练batch size大小。
--total_images
:指定训练数据图像的总数。
--class_dim
:指定类别总数。
--image_shape
:指定图像的尺寸。
--model_save_dir
:指定模型保存的路径。
--lr_strategy
:学习率衰减策略。
--num_epochs
:训练的总epoch数。
--lr
:初始学习率,指定预训练模型参数进行fine-tune时一般设置一个较小的初始学习率。
--act_quant_type
:激活量化类型,可选abs_max, moving_average_abs_max, range_abs_max。
--wt_quant_type
:权重量化类型,可选abs_max, channel_wise_abs_max。
```
> **备注:** 量化训练结束后,用户可在其指定的模型保存路径下看到float、int8和mobile三个目录。下面对三个目录下保存的模型特点进行解释说明:
> - **float目录:** 参数范围为int8范围但参数数据类型为float32的量化模型。
> - **int8目录:** 参数范围为int8范围且参数数据类型为int8的量化模型。
> - **mobile目录:** 参数特点与int8目录相同且兼容[paddle-mobile](https://github.com/PaddlePaddle/paddle-mobile)的量化模型。
>
> **注意:** 目前PaddlePaddle框架在Server端只支持使用float目录下的量化模型做预测。
PaddleSlim/quant_low_level_api/quant.py
浏览文件 @
377c6d32
...
@@ -131,7 +131,7 @@ def net_config(image, label, model, args):
...
@@ -131,7 +131,7 @@ def net_config(image, label, model, args):
avg_cost
=
avg_cost0
+
0.3
*
avg_cost1
+
0.3
*
avg_cost2
avg_cost
=
avg_cost0
+
0.3
*
avg_cost1
+
0.3
*
avg_cost2
acc_top1
=
fluid
.
layers
.
accuracy
(
input
=
out0
,
label
=
label
,
k
=
1
)
acc_top1
=
fluid
.
layers
.
accuracy
(
input
=
out0
,
label
=
label
,
k
=
1
)
acc_top5
=
fluid
.
layers
.
accuracy
(
input
=
out0
,
label
=
label
,
k
=
5
)
acc_top5
=
fluid
.
layers
.
accuracy
(
input
=
out0
,
label
=
label
,
k
=
5
)
out
=
out
2
out
=
out
0
else
:
else
:
out
=
model
.
net
(
input
=
image
,
class_dim
=
class_dim
)
out
=
model
.
net
(
input
=
image
,
class_dim
=
class_dim
)
cost
=
fluid
.
layers
.
cross_entropy
(
input
=
out
,
label
=
label
)
cost
=
fluid
.
layers
.
cross_entropy
(
input
=
out
,
label
=
label
)
...
...
PaddleSlim/quant_low_level_api/run_quant.sh
浏览文件 @
377c6d32
...
@@ -4,6 +4,8 @@
...
@@ -4,6 +4,8 @@
root_url
=
"http://paddle-imagenet-models-name.bj.bcebos.com"
root_url
=
"http://paddle-imagenet-models-name.bj.bcebos.com"
MobileNetV1
=
"MobileNetV1_pretrained.zip"
MobileNetV1
=
"MobileNetV1_pretrained.zip"
ResNet50
=
"ResNet50_pretrained.zip"
ResNet50
=
"ResNet50_pretrained.zip"
GoogleNet
=
"GoogleNet_pretrained.tar"
data_dir
=
'Your image dataset path, e.g. ILSVRC2012'
pretrain_dir
=
'../pretrain'
pretrain_dir
=
'../pretrain'
if
[
!
-d
${
pretrain_dir
}
]
;
then
if
[
!
-d
${
pretrain_dir
}
]
;
then
...
@@ -22,6 +24,11 @@ if [ ! -f ${ResNet50} ]; then
...
@@ -22,6 +24,11 @@ if [ ! -f ${ResNet50} ]; then
unzip
${
ResNet50
}
unzip
${
ResNet50
}
fi
fi
if
[
!
-f
${
GoogleNet
}
]
;
then
wget
${
root_url
}
/
${
GoogleNet
}
tar
xf
${
GoogleNet
}
fi
cd
-
cd
-
...
@@ -32,7 +39,7 @@ python quant.py \
...
@@ -32,7 +39,7 @@ python quant.py \
--model
=
MobileNet
\
--model
=
MobileNet
\
--pretrained_fp32_model
=
${
pretrain_dir
}
/MobileNetV1_pretrained
\
--pretrained_fp32_model
=
${
pretrain_dir
}
/MobileNetV1_pretrained
\
--use_gpu
=
True
\
--use_gpu
=
True
\
--data_dir
=
../data/ILSVRC2012
\
--data_dir
=
${
data_dir
}
\
--batch_size
=
256
\
--batch_size
=
256
\
--total_images
=
1281167
\
--total_images
=
1281167
\
--class_dim
=
1000
\
--class_dim
=
1000
\
...
@@ -50,7 +57,7 @@ python quant.py \
...
@@ -50,7 +57,7 @@ python quant.py \
# --model=ResNet50 \
# --model=ResNet50 \
# --pretrained_fp32_model=${pretrain_dir}/ResNet50_pretrained \
# --pretrained_fp32_model=${pretrain_dir}/ResNet50_pretrained \
# --use_gpu=True \
# --use_gpu=True \
# --data_dir=
../data/ILSVRC2012
\
# --data_dir=
${data_dir}
\
# --batch_size=128 \
# --batch_size=128 \
# --total_images=1281167 \
# --total_images=1281167 \
# --class_dim=1000 \
# --class_dim=1000 \
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}