fix
Showing
drn/README.md
已删除
100644 → 0
drn/drn.py
已删除
100644 → 0
drn/img/pic1.png
已删除
100644 → 0
{kind=link}
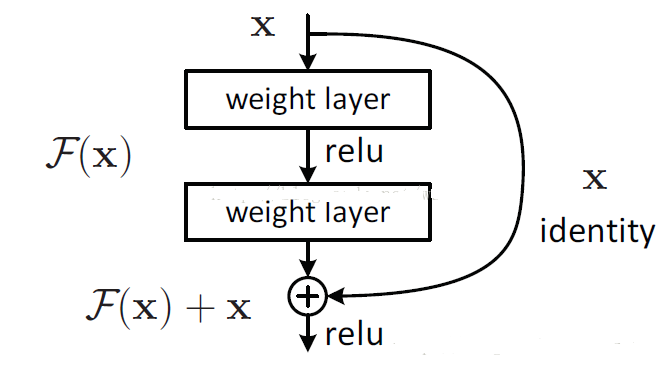
31.6 KB
drn/img/pic2.png
已删除
100644 → 0
{kind=link}
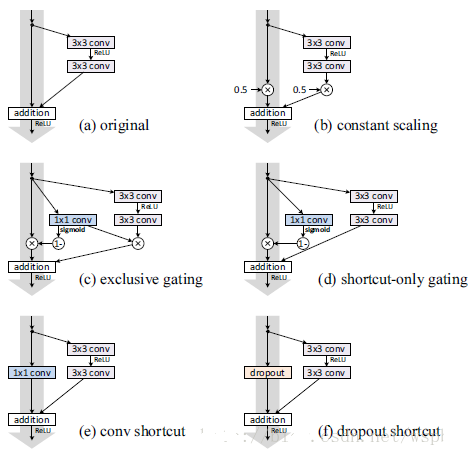
38.3 KB
drn/img/pic3.png
已删除
100644 → 0
{kind=link}
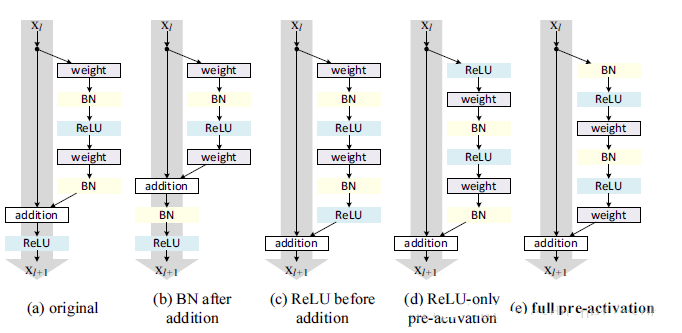
37.0 KB
drn/infer.py
已删除
100644 → 0
drn/reader.py
已删除
100644 → 0
drn/train.py
已删除
100644 → 0
drn/utils.py
已删除
100644 → 0
teach_read/README.md
已删除
100644 → 0
{kind=link}
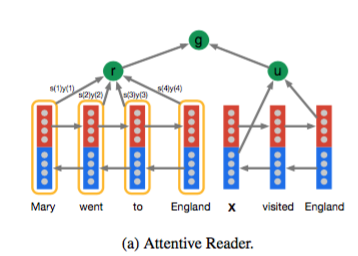
44.6 KB
{kind=link}
53.4 KB
{kind=link}

201.7 KB
{kind=link}
49.0 KB
teach_read/infer.py
已删除
100644 → 0
teach_read/train.py
已删除
100644 → 0
teach_read/two_layer_lstm.py
已删除
100644 → 0
text_cnn_classify/README.md
已删除
100644 → 0
text_cnn_classify/config.py
已删除
100644 → 0
{kind=link}
158.5 KB
{kind=link}
200.3 KB
text_cnn_classify/infer.py
已删除
100644 → 0
text_cnn_classify/train.py
已删除
100644 → 0