Merge branch 'develop' of https://github.com/PaddlePaddle/models into fix-81
Showing
ctr/index.html
0 → 100644
ltr/index.html
0 → 100644
此差异已折叠。
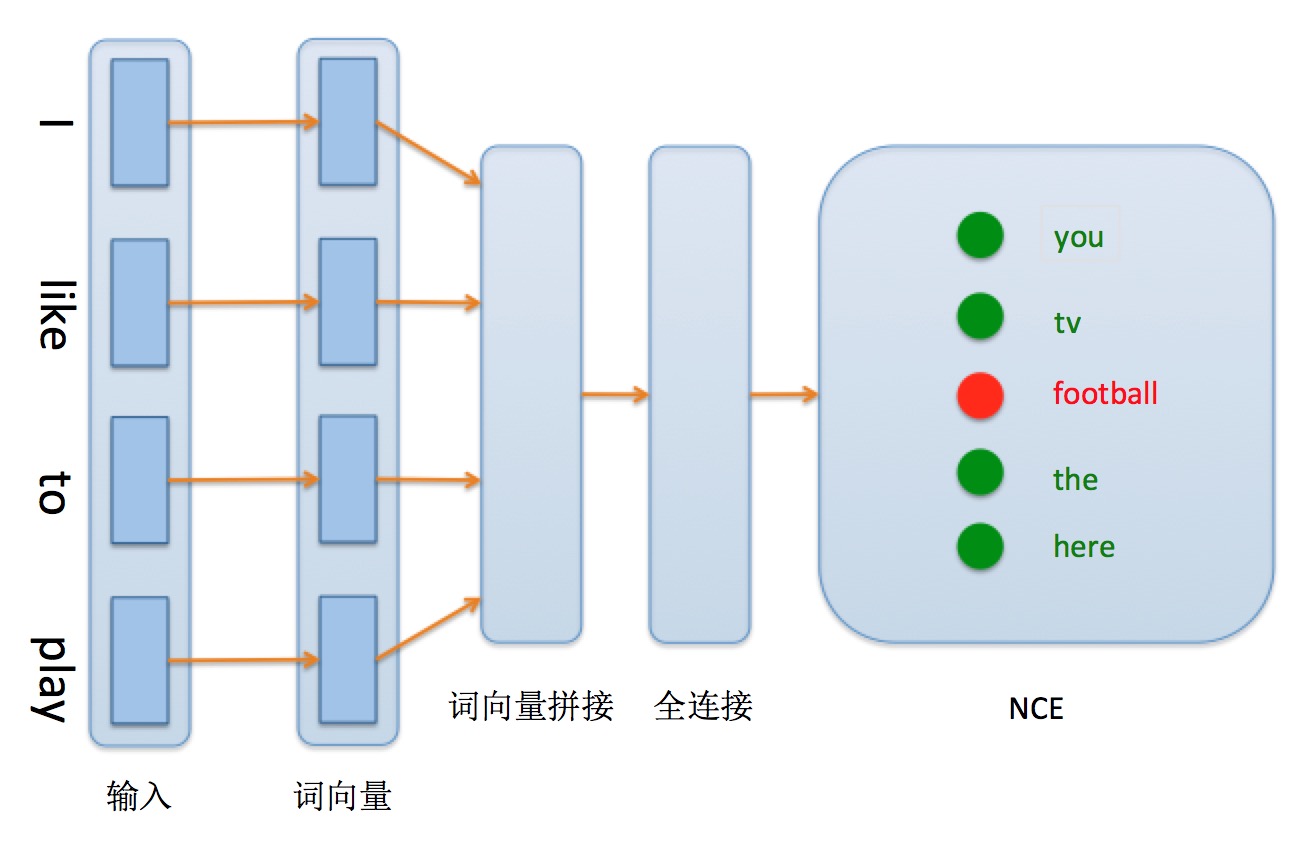
nce_cost/images/network_conf.png
0 → 100644
{kind=link}
102.9 KB
nce_cost/infer.py
0 → 100644
nce_cost/nce_conf.py
0 → 100644
nce_cost/train.py
0 → 100644
nmt_without_attention/index.html
0 → 100644
text_classification/index.html
0 → 100644
word_embedding/index.html
0 → 100644