Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
1f2f9034
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
1f2f9034
编写于
7月 03, 2018
作者:
Y
Yibing Liu
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update the cn doc of deep_asr
上级
c29f3343
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
79 addition
and
23 deletion
+79
-23
fluid/DeepASR/README_cn.md
fluid/DeepASR/README_cn.md
+79
-23
fluid/DeepASR/images/lstmp.png
fluid/DeepASR/images/lstmp.png
+0
-0
未找到文件。
fluid/DeepASR/README_cn.md
浏览文件 @
1f2f9034
...
...
@@ -2,21 +2,35 @@
---
DeepASR (Deep Automatic Speech Recognition) 是一个基于PaddlePaddle FLuid与
kaldi的语音识别系统。其利用Fluid框架完成声学模型的配置和训练,并集成kaldi的解码器。旨在方便已对kaldi的较为熟悉的用户实现语音识别
中声学模型的快速、大规模训练,并利用kaldi完成复杂的语音数据预处理和最终的解码过程。
DeepASR (Deep Automatic Speech Recognition) 是一个基于PaddlePaddle FLuid与
[
kaldi
](
http://www.kaldi-asr.org
)
的语音识别系统。其利用Fluid框架完成语音识别中声学模型的配置和训练,并集成kaldi的解码器。旨在方便已对kaldi的较为熟悉的用户实现
中声学模型的快速、大规模训练,并利用kaldi完成复杂的语音数据预处理和最终的解码过程。
### 目录
-
[
模型概览
](
#model-overview
)
-
[
安装
](
#installation
)
-
[
数据预处理
](
#data-reprocessing
)
-
[
模型训练
](
#training
)
-
[
训练过程
性能
分析
](
#perf-profiling
)
-
[
训练过程
中的时间
分析
](
#perf-profiling
)
-
[
预测和解码
](
#infer-decoding
)
-
[
Aishell示例
](
#aishell-example
)
-
[
如何贡献更多的实例
](
#how-to-contrib
)
-
[
评估错误率
](
#scoring-error-rate
)
-
[
Aishell 实例
](
#aishell-example
)
-
[
欢迎贡献更多的实例
](
#how-to-contrib
)
### 模型概览
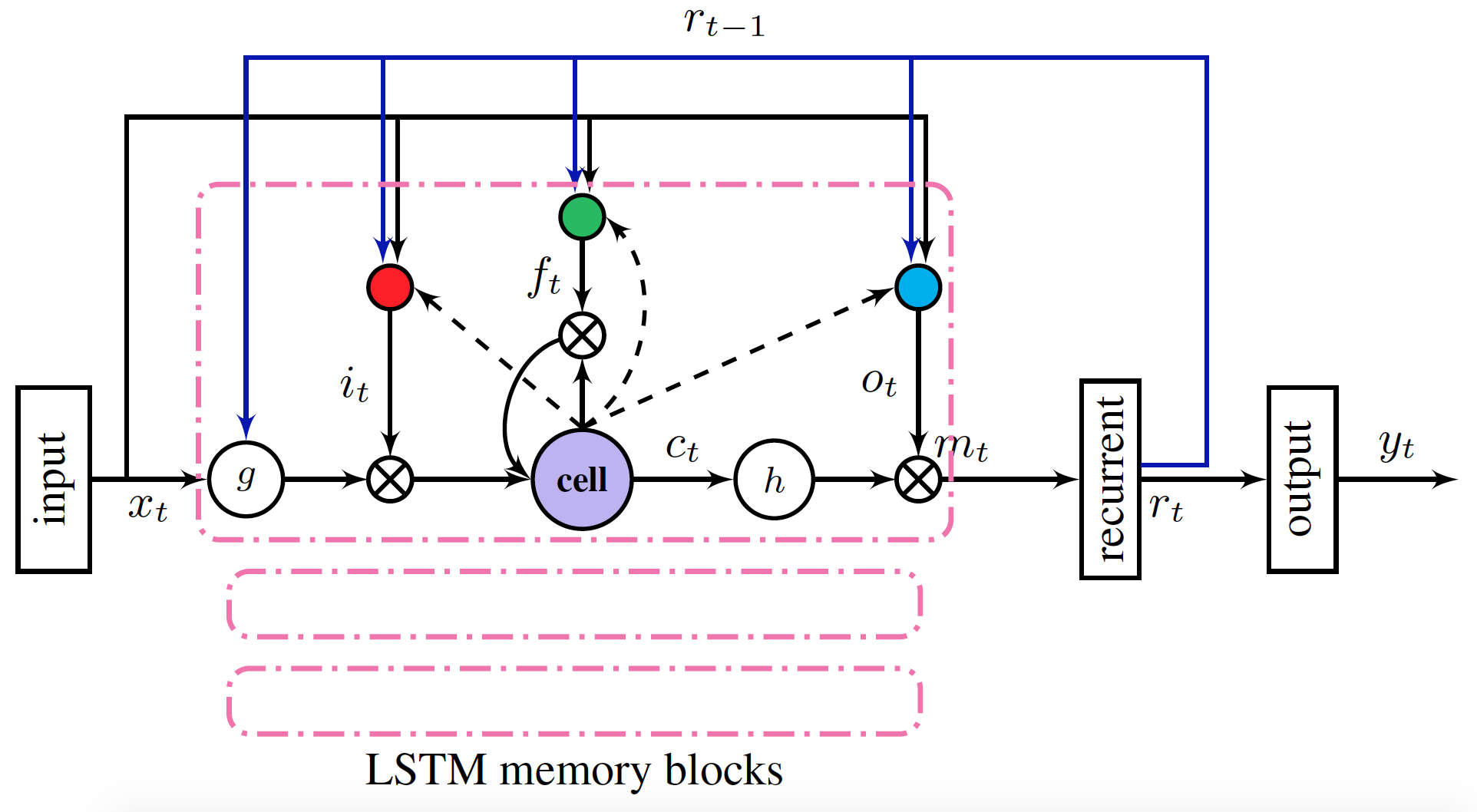
DeepASR的声学模型是一个单卷积层加多层层叠LSTMP 的结构,利用卷积来进行初步的特征提取,并用多层的LSTMP来对时序关系进行建模,所用到的损失函数是交叉熵。
[
LSTMP
](
https://arxiv.org/abs/1402.1128
)(
LSTM
with recurrent projection layer)是传统 LSTM 的拓展,在 LSTM 的基础上增加了一个映射层,将隐含层映射到较低的维度并输入下一个时间步,这种结构在大为减小 LSTM 的参数规模和计算复杂度的同时还提升了 LSTM 的性能表现。
<p
align=
"center"
>
<img
src=
"images/lstmp.png"
height=
240
width=
480
hspace=
'10'
/>
<br
/>
图1 LSTMP 的拓扑结构
</p>
### 安装
#### kaldi
DeepASR所用的解码器依赖于
[
kaldi
](
https://github.com/kaldi-asr/kaldi
)
环境, 按其中的命令安装好kaldi后设置环境变量:
#### kaldi的安装与设置
DeepASR解码过程中所用的解码器依赖于
[
Kaldi的安装
](
https://github.com/kaldi-asr/kaldi
)
,如环境中无Kaldi, 请
`git clone`
其源代码,并按给定的命令安装好kaldi,最后设置环境变量
`KALDI_ROOT`
:
```
shell
export
KALDI_ROOT
=
<kaldi的安装路径>
...
...
@@ -33,13 +47,15 @@ cd models/fluid/DeepASR/decoder
```
shell
sh setup.sh
```
即完成解码器的编译和安装
编译过程完成即成功地安转了解码器。
### 数据预处理
参考
[
Kaldi的数据准备流程
](
http://kaldi-asr.org/doc/data_prep.html
)
完成音频数据的特征提取和标签对齐
### 声学模型的训练
可选择在CPU或GPU模式下进行声学模型的训练,例如在GPU模式下的训练
可
以
选择在CPU或GPU模式下进行声学模型的训练,例如在GPU模式下的训练
```
shell
CUDA_VISIBLE_DEVICES
=
0,1,2,3 python
-u
train.py
\
...
...
@@ -50,16 +66,16 @@ CUDA_VISIBLE_DEVICES=0,1,2,3 python -u train.py \
--mean_var
global_mean_var
\
--parallel
```
实际训练过程中要正确指定建模单元大小、学习率等重要参数。关于这些参数的说明,请运行
其中
`train_feature.lst`
和
`train_label.lst`
分别是训练数据集的特征列表文件和标注列表文件,类似的,
`val_feature.lst`
和
`val_label.lst`
对应的则是验证集的列表文件。
实际训练过程中要正确指定建模单元大小、学习率等重要参数。关于这些参数的说明,请运行
```
shell
python train.py
--help
```
获取更多信息。
### 训练过程
性能
分析
### 训练过程
中的时间
分析
获取每个op
的执行时间
利用Fluid提供的性能分析工具profiler,可对训练过程进行性能分析,获取网络中operator级别
的执行时间
```
shell
CUDA_VISIBLE_DEVICES
=
0 python
-u
tools/profile.py
\
...
...
@@ -73,6 +89,8 @@ CUDA_VISIBLE_DEVICES=0 python -u tools/profile.py \
### 预测和解码
在充分训练好声学模型之后,利用训练过程中保存下来的模型checkpoint,可对输入的音频数据进行解码输出,得到声音到文字的识别结果
```
CUDA_VISIBLE_DEVICES=0,1,2,3 python -u infer_by_ckpt.py \
--batch_size 96 \
...
...
@@ -83,48 +101,86 @@ CUDA_VISIBLE_DEVICES=0,1,2,3 python -u infer_by_ckpt.py \
--parallel
```
### 评估错误率
对语音识别系统的评价常用的指标有词错误率(Word Error Rate, WER)和字错误率(Character Error Rate, CER), 在DeepASR中也实现了相关的度量工具,其运行方式为
```
python score_error_rate.py --error_rate_type cer --ref ref.txt --hyp decoding.txt
```
参数
`error_rate_type`
表示测量错误率的类型,即 WER 或 CER;
`ref.txt`
和
`decoding.txt`
分别表示参考文本和实际解码出的文本,它们有着同样的格式:
```
key1 text1
key2 text2
key3 text3
...
```
### Aishell 实例
本小节以Aishell数据为例,展示如何完成从数据预处理到解码输出。
[
Aishell数据集
](
http://www.aishelltech.com/kysjcp
)
本节以
[
Aishell数据集
](
http://www.aishelltech.com/kysjcp
)
为例,展示如何完成从数据预处理到解码输出。Aishell是由北京希尔贝克公司所开放的中文普通话语音数据集,时长178小时,包含了400名来自不同口音区域录制者的语音,原始数据可由
[
openslr
](
http://www.openslr.org/33
)
获取。为简化流程,这里提供了已完成预处理的数据集供下载:
```
cd examples/aishell
sh prepare_data.sh
```
提供已经预处理好的数据集供下载
其中包括了声学模型的训练数据以及解码过程中所用到的辅助文件等。下载数据完成后,在开始训练之前可对训练过程进行分析
```
sh pr
epare_data
.sh
sh pr
ofile
.sh
```
下载数据完成后,
执行训练
执行训练
```
sh train.sh
```
训练过程中损失和精度的变化曲线如下图所示
默认是用4卡GPU进行训练,在实际过程中可根据可用GPU的数目和显存大小对
`batch_size`
、学习率等参数进行动态调整。训练过程中典型的损失函数和精度的变化趋势如图2所示
<p
align=
"center"
>
<img
src=
"images/learning_curve.png"
height=
480
width=
640
hspace=
'10'
/>
<br
/>
Aishell数据集上训练声学模型的学习曲线
图2 在
Aishell数据集上训练声学模型的学习曲线
</p>
执行预测
完成模型训练后,即可执行预测识别测试集语音中的文字:
```
sh infer_by_ckpt.sh
```
评估误差
其中包括了声学模型的预测和解码器的解码输出两个重要的过程。以下是解码输出的样例:
```
...
BAC009S0764W0239 十一 五 期间 我 国 累计 境外 投资 七千亿 美元
BAC009S0765W0140 在 了解 送 方 的 资产 情况 与 需求 之后
BAC009S0915W0291 这 对 苹果 来说 不 是 件 容易 的 事 儿
BAC009S0769W0159 今年 土地 收入 预计 近 四万亿 元
BAC009S0907W0451 由 浦东 商店 作为 掩护
BAC009S0768W0128 土地 交易 可能 随着 供应 淡季 的 到来 而 降温
...
```
每行对应一个输出,均以音频样本的关键字开头,随后是按词分隔的解码出的中文文本。解码完成后运行脚本评估字错误率(CER)
```
sh score_cer.sh
```
利用经过20轮左右训练的声学模型,可以在Aishell的测试集上得到CER约10%的识别结果。
其输出类似于如下所示
```
Error rate[cer] = 0.101971 (10683/104765),
total 7176 sentences in hyp, 0 not presented in ref.
```
利用经过20轮左右训练的声学模型,可以在Aishell的测试集上得到CER约10%的识别结果。
###
如何
贡献更多的实例
###
欢迎
贡献更多的实例
欢迎贡献更多的实例
DeepASR目前只开放了Aishell实例,我们欢迎用户在更多的数据集上测试完整的训练流程并贡献到这个项目中。
fluid/DeepASR/images/lstmp.png
0 → 100644
浏览文件 @
1f2f9034
173.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}