Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
154c342a
M
models
项目概览
PaddlePaddle
/
models
接近 2 年 前同步成功
通知
230
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
154c342a
编写于
12月 07, 2021
作者:
D
dyning
提交者:
GitHub
12月 07, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update pd serving (#5398)
上级
4a238cf7
变更
6
隐藏空白更改
内联
并排
Showing
6 changed file
with
134 addition
and
45 deletion
+134
-45
docs/tipc/py_serving/images/py_serving_deploy_pipeline.jpg
docs/tipc/py_serving/images/py_serving_deploy_pipeline.jpg
+0
-0
docs/tipc/py_serving/py_serving.md
docs/tipc/py_serving/py_serving.md
+46
-45
docs/tipc/py_serving/template/code/config.yml
docs/tipc/py_serving/template/code/config.yml
+32
-0
docs/tipc/py_serving/template/code/pipeline_http_client.py
docs/tipc/py_serving/template/code/pipeline_http_client.py
+21
-0
docs/tipc/py_serving/template/code/web_service.py
docs/tipc/py_serving/template/code/web_service.py
+35
-0
docs/tipc/py_serving/template/model_linux_gpu_normal_normal_serving_python_linux_gpu_cpu_params.txt
...gpu_normal_normal_serving_python_linux_gpu_cpu_params.txt
+0
-0
未找到文件。
docs/tipc/py_serving/images/py_serving_deploy_pipeline.jpg
查看替换文件 @
4a238cf7
浏览文件 @
154c342a
156.7 KB
|
W:
|
H:
158.9 KB
|
W:
|
H:
2-up
Swipe
Onion skin
docs/tipc/py_serving/py_serving.md
浏览文件 @
154c342a
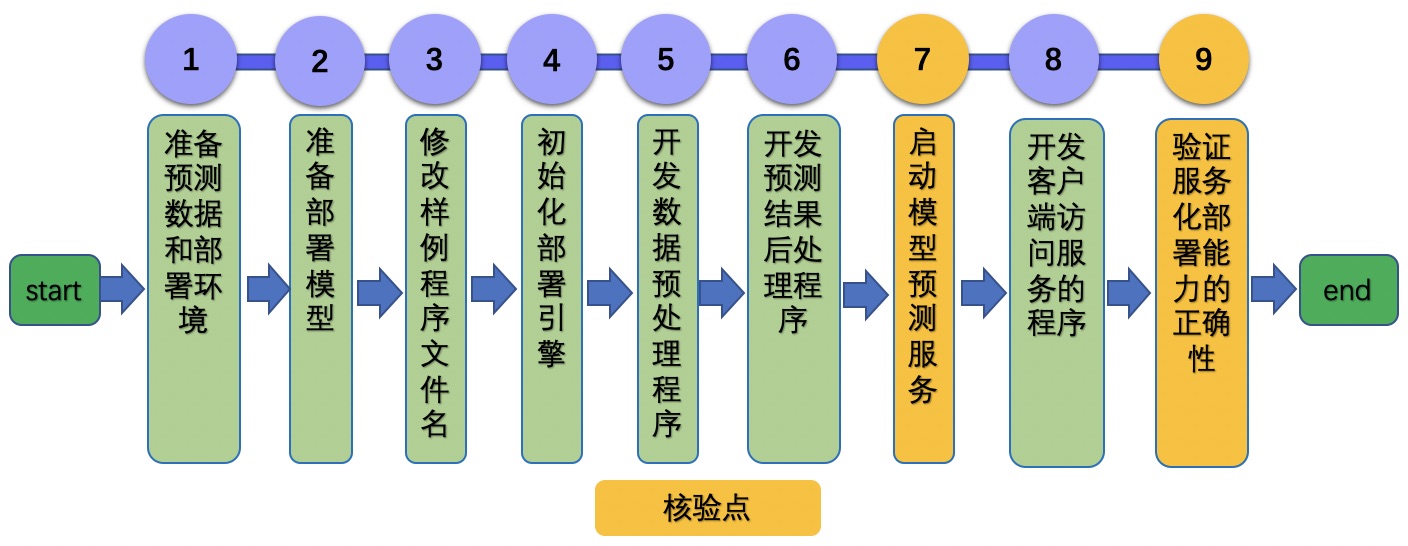
# Linux GPU/CPU 服务化部署开发文档
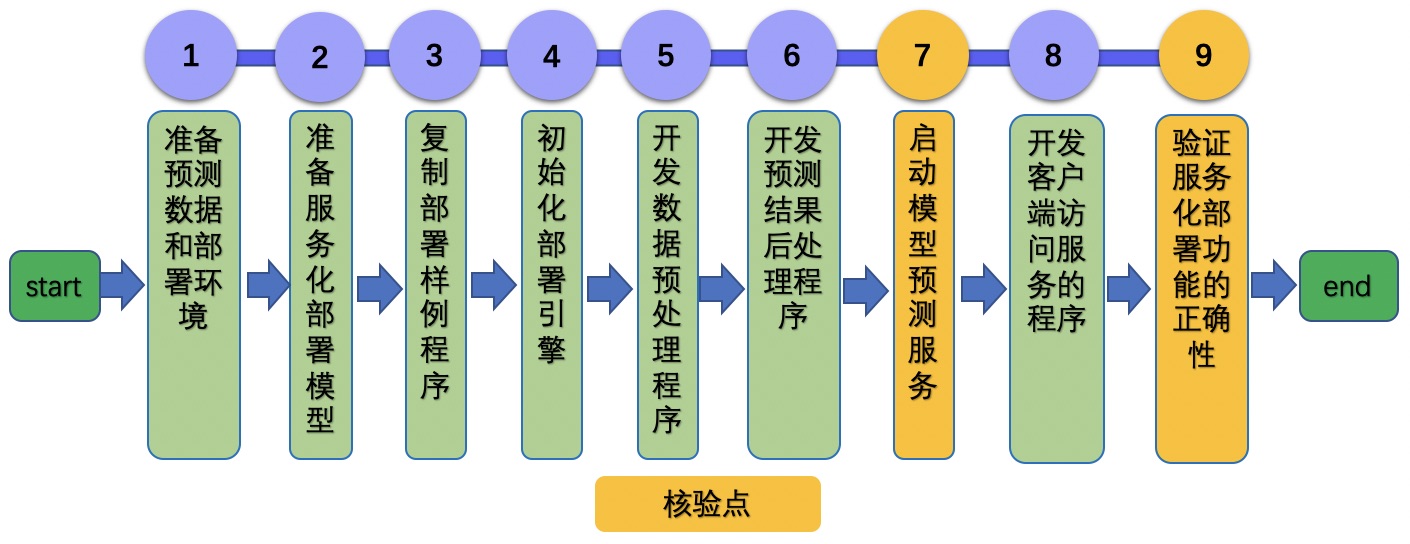
# Linux GPU/CPU 服务化部署开发文档
-
[
1 简介
](
#1---
)
-
[
1 简介
](
#1---
)
-
[
2 服务化部署
能力
开发
](
#2---
)
-
[
2 服务化部署开发
](
#2---
)
*
[
2.1 准备测试数据和部署环境
](
#21---
)
*
[
2.1 准备测试数据和部署环境
](
#21---
)
*
[
2.2 准备部署模型
](
#22---
)
*
[
2.2 准备
服务化
部署模型
](
#22---
)
*
[
2.3
修改样例程序文件名
](
#23---
)
*
[
2.3
复制部署样例程序
](
#23---
)
*
[
2.4 初始化部署引擎
](
#24---
)
*
[
2.4 初始化部署引擎
](
#24---
)
*
[
2.5 开发数据预处理程序
](
#25---
)
*
[
2.5 开发数据预处理程序
](
#25---
)
*
[
2.6 开发预测结果后处理程序
](
#26---
)
*
[
2.6 开发预测结果后处理程序
](
#26---
)
*
[
2.7 启动模型预测服务
](
#27---
)
*
[
2.7 启动模型预测服务
](
#27---
)
*
[
2.8 开发客户端访问服务的程序
](
#28---
)
*
[
2.8 开发客户端访问服务的程序
](
#28---
)
*
[
2.9 验证服务化部署
能力
的正确性
](
#29---
)
*
[
2.9 验证服务化部署
功能
的正确性
](
#29---
)
-
[
3 FAQ
](
#3---
)
-
[
3 FAQ
](
#3---
)
<a
name=
"1---"
></a>
<a
name=
"1---"
></a>
...
@@ -40,7 +40,7 @@ Paddle Serving依托深度学习框架PaddlePaddle旨在帮助深度学习开发
...
@@ -40,7 +40,7 @@ Paddle Serving依托深度学习框架PaddlePaddle旨在帮助深度学习开发
【基本流程】
【基本流程】
**(1)准备测试数据:**
从验证集或者测试集中抽出至少一张图像,用于后续推理过程验证。
后续文档中将使用测试图像 ./demo.jpg 进行说明。
**(1)准备测试数据:**
从验证集或者测试集中抽出至少一张图像,用于后续推理过程验证。
**(2)准备部署环境**
**(2)准备部署环境**
...
@@ -59,10 +59,10 @@ wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.7.0-
...
@@ -59,10 +59,10 @@ wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.7.0-
pip3 install paddle_serving_app-0.7.0-py3-none-any.whl
pip3 install paddle_serving_app-0.7.0-py3-none-any.whl
```
```
Paddle Serving Server更多不同
环境的whl包
请参考:
[
下载页面
](
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Latest_Packages_CN.md
)
Paddle Serving Server更多不同
运行环境的whl包下载地址,
请参考:
[
下载页面
](
https://github.com/PaddlePaddle/Serving/blob/v0.7.0/doc/Latest_Packages_CN.md
)
<a
name=
"22---"
></a>
<a
name=
"22---"
></a>
### 2.2 准备部署模型
### 2.2 准备
服务化
部署模型
【基本流程】
【基本流程】
...
@@ -75,49 +75,46 @@ python3 -m paddle_serving_client.convert --dirname {静态图模型路径} --mod
...
@@ -75,49 +75,46 @@ python3 -m paddle_serving_client.convert --dirname {静态图模型路径} --mod
【实战】
【实战】
针对AlexNet网络,将静态图模型
转换为服务化部署模型的示例命令如下,转换完后在本地生成serving_server和serving_client两个文件夹
。
针对AlexNet网络,将静态图模型
([模型下载地址,待补充])转换为服务化部署模型的示例命令如下,转换完后在本地生成serving_server和serving_client两个文件夹。本教程后续主要使用serving_server文件夹中的模型
。
```
python
```
python
python3
-
m
paddle_serving_client
.
convert
--
dirname
.
.
/
alexnet_infer
/
--
model_filename
inference
.
pdmodel
--
params_filename
inference
.
pdiparams
--
serving_server
serving_server
--
serving_client
serving_client
python3
-
m
paddle_serving_client
.
convert
--
dirname
.
/
alexnet_infer
/
--
model_filename
inference
.
pdmodel
--
params_filename
inference
.
pdiparams
--
serving_server
serving_server
--
serving_client
serving_client
```
```
<a
name=
"23---"
></a>
<a
name=
"23---"
></a>
### 2.3
修改样例程序文件名
### 2.3
复制部署样例程序
【基本流程】
【基本流程】
目录 pdserving/example 下面包含3个用于服务化部署的样例程序,具体如下:
服务化部署的样例程序的目录地址为:[tipc/py_serving/template/code/, 待补充地址]
该目录下面包含3个文件,具体如下:
-
tipc_
web_service.py:用于开发服务端模型预测相关程序。由于使用多卡或者多机部署预测服务,设计高效的服务调度策略比较复杂,Paddle Serving将网络预测进行了封装,在这个程序里面开发者只需要关心部署服务引擎的初始化,模型预测的前处理和后处理开发,不用关心模型预测调度问题。
-
web_service.py:用于开发服务端模型预测相关程序。由于使用多卡或者多机部署预测服务,设计高效的服务调度策略比较复杂,Paddle Serving将网络预测进行了封装,在这个程序里面开发者只需要关心部署服务引擎的初始化,模型预测的前处理和后处理开发,不用关心模型预测调度问题。
-
config.yml:服务端模型预测相关配置文件,里面有各参数的详细说明。开发者只需要关注如下配置:http_port(服务的http端口),model_config(服务化部署模型的路径),device_type(计算硬件类型),devices(计算硬件ID)。
-
config.yml:服务端模型预测相关配置文件,里面有各参数的详细说明。开发者只需要关注如下配置:http_port(服务的http端口),model_config(服务化部署模型的路径),device_type(计算硬件类型),devices(计算硬件ID)。
-
tipc_
pipeline_http_client.py:用于客户端访问服务的程序,开发者需要设置url(服务地址)、logid(日志ID)和测试图像。
-
pipeline_http_client.py:用于客户端访问服务的程序,开发者需要设置url(服务地址)、logid(日志ID)和测试图像。
【实战】
【实战】
如果服务化部署AlexNet网络,需要拷贝上述三个文件到运行目录,并修改名称如下:
如果服务化部署AlexNet网络,需要拷贝上述三个文件到运行目录。
-
tipc_web_service.py ---> alex_web_service.py
-
config.yml ---> alex_config.yml
-
tipc_pipeline_http_client.py ---> alex_pipeline_http_client.py
<a
name=
"24---"
></a>
<a
name=
"24---"
></a>
### 2.4 初始化部署引擎
### 2.4 初始化部署引擎
【基本流程】
【基本流程】
针对模型名称,修改
tipc_
web_service.py中类TIPCExampleService、TIPCExampleOp的名称,以及这些类初始化中任务名称name,同时通过uci_service.prepare_pipeline_config设置配置参数。
针对模型名称,修改web_service.py中类TIPCExampleService、TIPCExampleOp的名称,以及这些类初始化中任务名称name,同时通过uci_service.prepare_pipeline_config设置配置参数。
同时修改服务配置文件中的配置:http_port(服务的http端口),model_config(服务化部署模型的路径),device_type(计算硬件类型),devices(计算硬件ID)
同时修改服务配置文件中的配置:
OP名称,
http_port(服务的http端口),model_config(服务化部署模型的路径),device_type(计算硬件类型),devices(计算硬件ID)
【实战】
【实战】
针对AlexNet网络,
修改alex_
web_service.py文件后的代码如下:
针对AlexNet网络,
(1)修改
web_service.py文件后的代码如下:
```
```
from paddle_serving_server.web_service import WebService, Op
class AlexNetOp(Op):
class AlexNetOp(Op):
def init_op(self):
def init_op(self):
pass
pass
...
@@ -135,18 +132,23 @@ class AlexNetService(WebService):
...
@@ -135,18 +132,23 @@ class AlexNetService(WebService):
return alexnet_op
return alexnet_op
uci_service = AlexNetService(name="alexnet")
uci_service = AlexNetService(name="alexnet")
uci_service.prepare_pipeline_config("
alex_
config.yml")
uci_service.prepare_pipeline_config("config.yml")
uci_service.run_service()
uci_service.run_service()
```
```
服务配置文件alex_config.yml 这里我们使用默认配置,开发者可以根据具体运行环境情况进行修改。
(2)修改服务配置文件config.yml。
-
http_port:使用默认的端口号18080
-
OP名称:第14行更新为alexnet
-
model_config:与2.2转换后服务化部署模型文件夹路径一致,这里使用默认配置 "./serving_server"
-
device_type:使用默认配置1,基于GPU预测
-
devices:使用默认配置"0",0号卡预测
<a
name=
"25---"
></a>
<a
name=
"25---"
></a>
### 2.5 开发数据预处理程序
### 2.5 开发数据预处理程序
【基本流程】
【基本流程】
tipc_
web_service.py文件中的TIPCExampleOp类的preprocess函数用于开发数据预处理程序,包含输入、处理流程和输出三部分。
web_service.py文件中的TIPCExampleOp类的preprocess函数用于开发数据预处理程序,包含输入、处理流程和输出三部分。
**(1)输入:**
一般开发者使用时,只需要关心input_dicts和log_id两个输入参数。这两个参数与客户端访问服务程序tipc_pipeline_http_client.py中的请求参数相对应,即:
**(1)输入:**
一般开发者使用时,只需要关心input_dicts和log_id两个输入参数。这两个参数与客户端访问服务程序tipc_pipeline_http_client.py中的请求参数相对应,即:
```
```
...
@@ -165,15 +167,17 @@ tipc_web_service.py文件中的TIPCExampleOp类的preprocess函数用于开发
...
@@ -165,15 +167,17 @@ tipc_web_service.py文件中的TIPCExampleOp类的preprocess函数用于开发
【实战】
【实战】
针对AlexNet网络的数据预处理开发,需要将
Paddle Inference中的preprocess.py
复制到Paddle Serving的目录下,修改alex_web_service.py文件中代码如下:
针对AlexNet网络的数据预处理开发,需要将
[Paddle Inference中的preprocess_ops.py, 待补充文件路径]
复制到Paddle Serving的目录下,修改alex_web_service.py文件中代码如下:
添加头文件:
添加头文件:
```
py
```
py
import
numpy
as
np
import
sys
import
base64
import
base64
from
PIL
import
Image
from
PIL
import
Image
import
io
import
io
from
preprocess
import
ResizeImage
,
CenterCropImage
,
NormalizeImage
,
ToCHW
,
Compose
from
preprocess
_ops
import
ResizeImage
,
CenterCropImage
,
NormalizeImage
,
ToCHW
,
Compose
```
```
修改AlexNetOp中的init_op和preprocess函数相关代码:
修改AlexNetOp中的init_op和preprocess函数相关代码:
...
@@ -204,7 +208,7 @@ class AlexNetOp(Op):
...
@@ -204,7 +208,7 @@ class AlexNetOp(Op):
【基本流程】
【基本流程】
tipc_
web_service.py文件中的TIPCExampleOp类的 postprocess 函数用于开发预测结果后处理程序,包含输入、处理流程和输出三部分。
web_service.py文件中的TIPCExampleOp类的 postprocess 函数用于开发预测结果后处理程序,包含输入、处理流程和输出三部分。
**(1)输入:**
包含四个参数,其中参数input_dicts、log_id和数据预处理函数preprocess中一样,data_id可忽略,fetch_dict 是网络预测输出字典,其中输出的key可以通过服务化模型配置文件serving_server/serving_server_conf.prototxt中的fetch_var字典的name字段获取。
**(1)输入:**
包含四个参数,其中参数input_dicts、log_id和数据预处理函数preprocess中一样,data_id可忽略,fetch_dict 是网络预测输出字典,其中输出的key可以通过服务化模型配置文件serving_server/serving_server_conf.prototxt中的fetch_var字典的name字段获取。
...
@@ -218,11 +222,11 @@ result, None, ""
...
@@ -218,11 +222,11 @@ result, None, ""
【实战】
【实战】
针对AlexNet网络的预测结果后处理开发,修改
alex_
web_service.py文件中AlexNetOp中的postprocess函数相关代码如下:
针对AlexNet网络的预测结果后处理开发,修改web_service.py文件中AlexNetOp中的postprocess函数相关代码如下:
```
```
def postprocess(self, input_dicts, fetch_dict, data_id, log_id):
def postprocess(self, input_dicts, fetch_dict, data_id, log_id):
score_list = fetch_dict["
conv2d_5.tmp_0
"]
score_list = fetch_dict["
save_infer_model/scale_0.tmp_1
"]
result = {"class_id": [], "prob": []}
result = {"class_id": [], "prob": []}
for score in score_list:
for score in score_list:
score = score.flatten()
score = score.flatten()
...
@@ -243,34 +247,31 @@ result, None, ""
...
@@ -243,34 +247,31 @@ result, None, ""
当完成服务化部署引擎初始化、数据预处理和预测结果后处理开发,则可以按如下命令启动模型预测服务:
当完成服务化部署引擎初始化、数据预处理和预测结果后处理开发,则可以按如下命令启动模型预测服务:
```
bash
```
bash
python3
tipc_
web_service.py &
python3 web_service.py &
```
```
【实战】
【实战】
针对AlexNet网络, 模型预测服务启动命令如下:
针对AlexNet网络, 启动成功的界面如下:
```
bash
python3 alex_web_service.py &
```
启动成功的界面如下:


<a
name=
"28---"
></a>
<a
name=
"28---"
></a>
### 2.8 开发客户端访问服务的程序
### 2.8 开发客户端访问服务的程序
【基本流程】
【基本流程】
当成功启动了模型预测服务,可以修改tipc_pipeline_http_client.py程序,访问该服务。主要设置url(服务地址)、logid(日志ID)和测试图像。其中服务地址的url设置如下:
当成功启动了模型预测服务,可以修改pipeline_http_client.py程序,访问该服务。主要设置url(服务地址)、logid(日志ID)和测试图像。其中服务地址的url的样式为 "http://127.0.0.1:18080/tipc_example/prediction" ,url的设置需要将url中的tipc_example更新为TIPCExampleService类初始化的name。
【实战】
【实战】
针对AlexNet网络, 客户端访问服务的命令如下:
针对AlexNet网络, 修改pipeline_http_client.py程序中的url(服务地址)、logid(日志ID)和测试图像地址,其中url改为:
```
url = "http://127.0.0.1:18080/alexnet/prediction"
```
客户端访问服务的命令如下:
```
```
python3 alex_pipeline_http_client.py
python3 alex_pipeline_http_client.py
...
@@ -289,7 +290,7 @@ unset https_proxy
...
@@ -289,7 +290,7 @@ unset https_proxy
```
```
<a
name=
"29---"
></a>
<a
name=
"29---"
></a>
### 2.9 验证服务化部署
能力的正确性
### 2.9 验证服务化部署
功能的正确性([待若愚完善])
```
```
python3 infer.py --model-dir ../alexnet_infer/ --benchmark False --img-path ../pdserving/demo.jpg --use-gpu True
python3 infer.py --model-dir ../alexnet_infer/ --benchmark False --img-path ../pdserving/demo.jpg --use-gpu True
...
...
docs/tipc/py_serving/template/code/config.yml
0 → 100755
浏览文件 @
154c342a
#worker_num, 最大并发数。当build_dag_each_worker=True时, 框架会创建worker_num个进程,每个进程内构建grpcSever和DAG
##当build_dag_each_worker=False时,框架会设置主线程grpc线程池的max_workers=worker_num
worker_num
:
20
#http端口, rpc_port和http_port不允许同时为空。当rpc_port可用且http_port为空时,不自动生成http_port
http_port
:
18080
rpc_port
:
9993
dag
:
#op资源类型, True, 为线程模型;False,为进程模型
is_thread_op
:
False
op
:
#op名称,与web_service中的TIPCExampleService初始化name参数一致
tipc_example
:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency
:
1
#当op配置没有server_endpoints时,从local_service_conf读取本地服务配置
local_service_conf
:
#uci模型路径
model_config
:
"
./serving_server"
#计算硬件类型: 空缺时由devices决定(CPU/GPU),0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu
device_type
:
1
#计算硬件ID,当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡
devices
:
"
0"
# "0,1"
#client类型,包括brpc, grpc和local_predictor.local_predictor不启动Serving服务,进程内预测
client_type
:
local_predictor
docs/tipc/py_serving/template/code/pipeline_http_client.py
0 → 100755
浏览文件 @
154c342a
import
numpy
as
np
import
requests
import
json
import
cv2
import
base64
import
os
def
cv2_to_base64
(
image
):
return
base64
.
b64encode
(
image
).
decode
(
'utf8'
)
if
__name__
==
"__main__"
:
url
=
"http://127.0.0.1:18080/tipc_example/prediction"
logid
=
10000
img_path
=
"../../images/demo.jpg"
with
open
(
img_path
,
'rb'
)
as
file
:
image_data1
=
file
.
read
()
image
=
cv2_to_base64
(
image_data1
)
data
=
{
"key"
:
[
"image"
],
"value"
:
[
image
],
"logid"
:
logid
}
for
i
in
range
(
5
):
r
=
requests
.
post
(
url
=
url
,
data
=
json
.
dumps
(
data
))
print
(
r
.
json
())
docs/tipc/py_serving/template/code/web_service.py
0 → 100755
浏览文件 @
154c342a
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from
paddle_serving_server.web_service
import
WebService
,
Op
class
TIPCExampleOp
(
Op
):
def
init_op
(
self
):
pass
def
preprocess
(
self
,
input_dicts
,
data_id
,
log_id
):
pass
def
postprocess
(
self
,
input_dicts
,
fetch_dict
,
data_id
,
log_id
):
pass
class
TIPCExampleService
(
WebService
):
def
get_pipeline_response
(
self
,
read_op
):
tipc_example_op
=
TIPCExampleOp
(
name
=
"tipc_example"
,
input_ops
=
[
read_op
])
return
tipc_example_op
uci_service
=
TIPCExampleService
(
name
=
"tipc_example"
)
uci_service
.
prepare_pipeline_config
(
"config.yml"
)
uci_service
.
run_service
()
docs/tipc/py_serving/template/model_linux_gpu_normal_normal_serving_python_linux_gpu_cpu_params.txt
已删除
100644 → 0
浏览文件 @
4a238cf7
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}