Pass 0, batch 9, loss 7.43522, accucacys: [0.00390625, 0.00390625]
Pass 0, batch 9, loss 7.43522, accucacys: [0.00390625, 0.00390625]
```
```
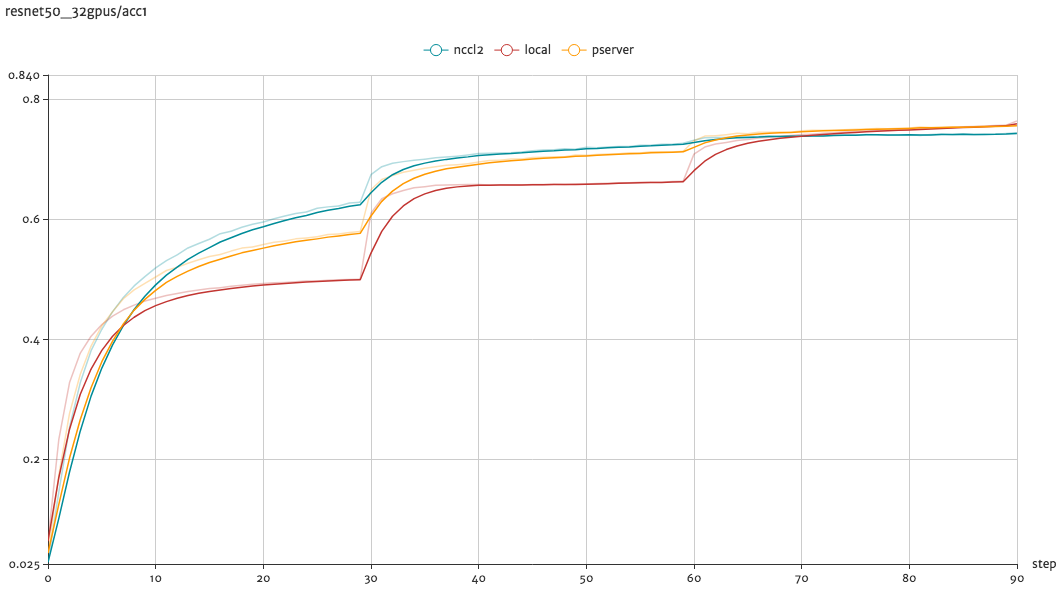
The training accucacys top1 of local training, distributed training with NCCL2 and parameter server architecture on the ResNet50 model are shown in the below figure:
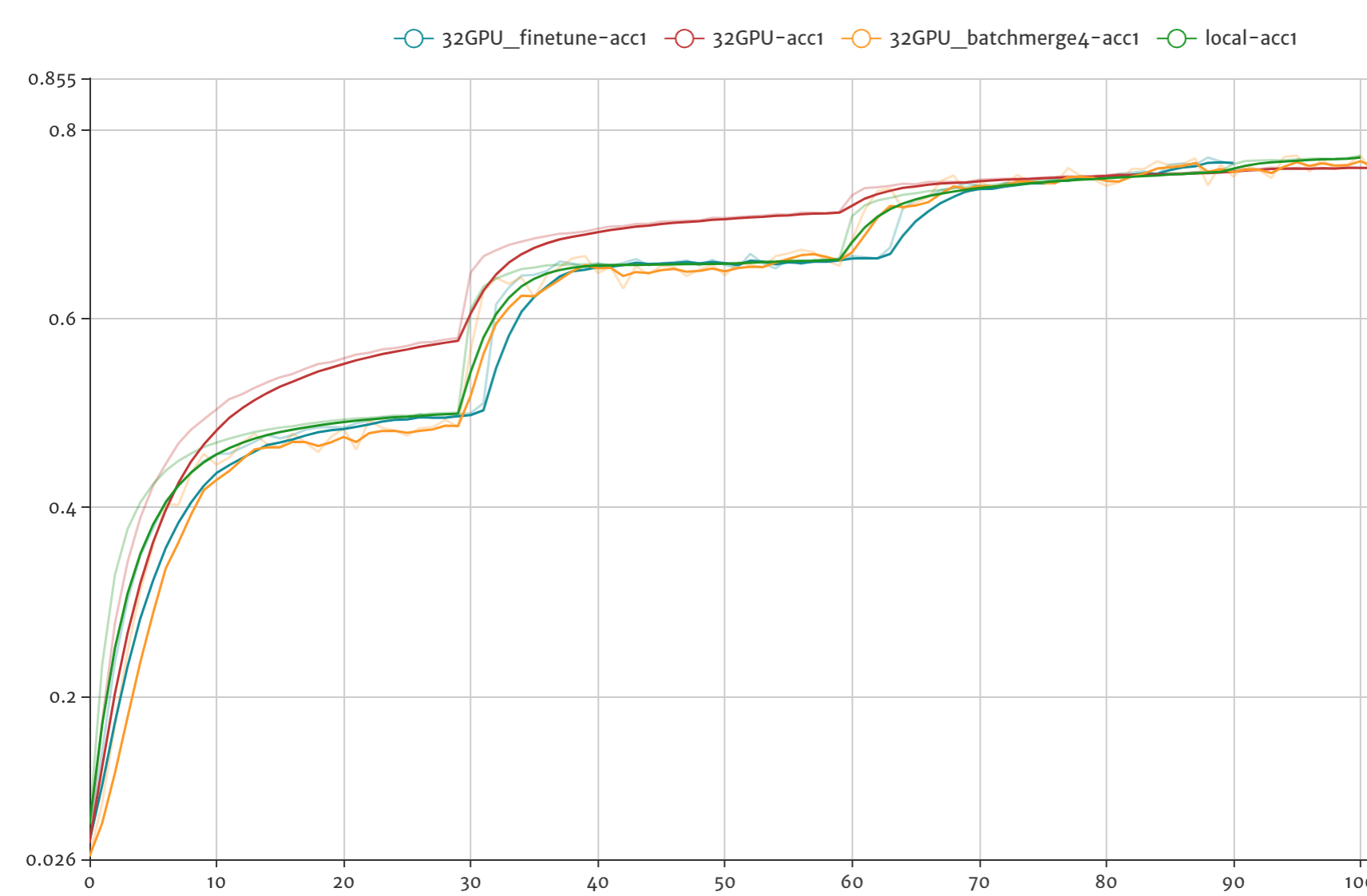
The below figure shows top 1 train accuracy for local training with 8 GPUs and distributed training
with 32 GPUs, and also distributed training with batch merge feature turned on. Note that the
red curve is train with origin model configuration, which do not have warmup and some detailed modifications.
For distributed training with 32GPUs using `--model DistResnet` we can achieve test accuracy 75.5% after
90 passes of training (the test accuracy is not shown in below figure).
{kind=link}
{kind=link}