Add document for slim demo. (#1967) (#2126)
* Add README.md * Update url of images. * Add images. * Add usage.md * Add demo.md * Fix demo.md * Add model_zoo.md * Fix pretrain models download in model zoo. * Refine documents. 1. Rename python to Python 2. Fix README.md: vgg->VGG, resnet->ResNet, mobilenet->MobileNet 3. Rename flops to FLOPS * Move docs of PaddleSlim from models.fluid.PaddleSlim to models.PaddleSlim * 1. Introduce model format in README.md 2. Merge results of combined strategies into one table. * Refine README.md * Refine README 1. Fix some terms in README.md 2. Fix description of model format in README.md 3. Add Channel-Wise into feature list 4. Rename 'paddle mobile' to 'Paddle Mobile' 5. Add comments for dynamic quantization and static quantization 6. Add entry url for Model Zoo in README.md * Refine README.
Showing
PaddleSlim/README.md
0 → 100644
PaddleSlim/docs/demo.md
0 → 100644
文件已添加
{kind=link}
142.7 KB
{kind=link}
127.9 KB
{kind=link}
152.2 KB
{kind=link}
182.2 KB
{kind=link}
57.7 KB
{kind=link}
190.3 KB
{kind=link}
36.6 KB
{kind=link}
18.8 KB
{kind=link}
80.1 KB
{kind=link}
181.4 KB
{kind=link}
183.4 KB
{kind=link}
47.1 KB
{kind=link}
30.5 KB
{kind=link}
36.5 KB
{kind=link}
308.5 KB
{kind=link}
125.2 KB
PaddleSlim/docs/model_zoo.md
0 → 100644
PaddleSlim/docs/tutorial.md
0 → 100644
PaddleSlim/docs/usage.md
0 → 100644
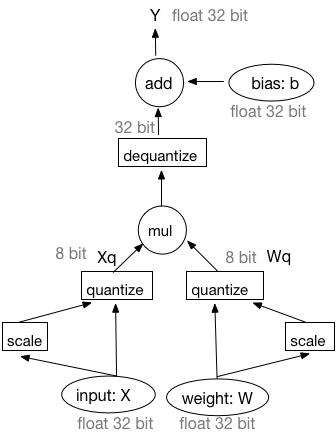
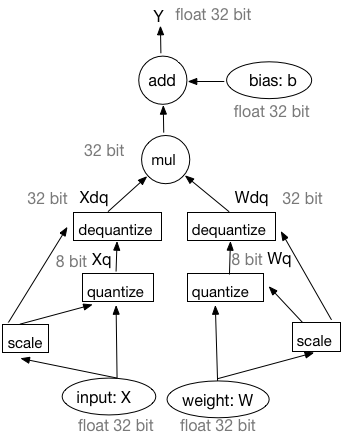
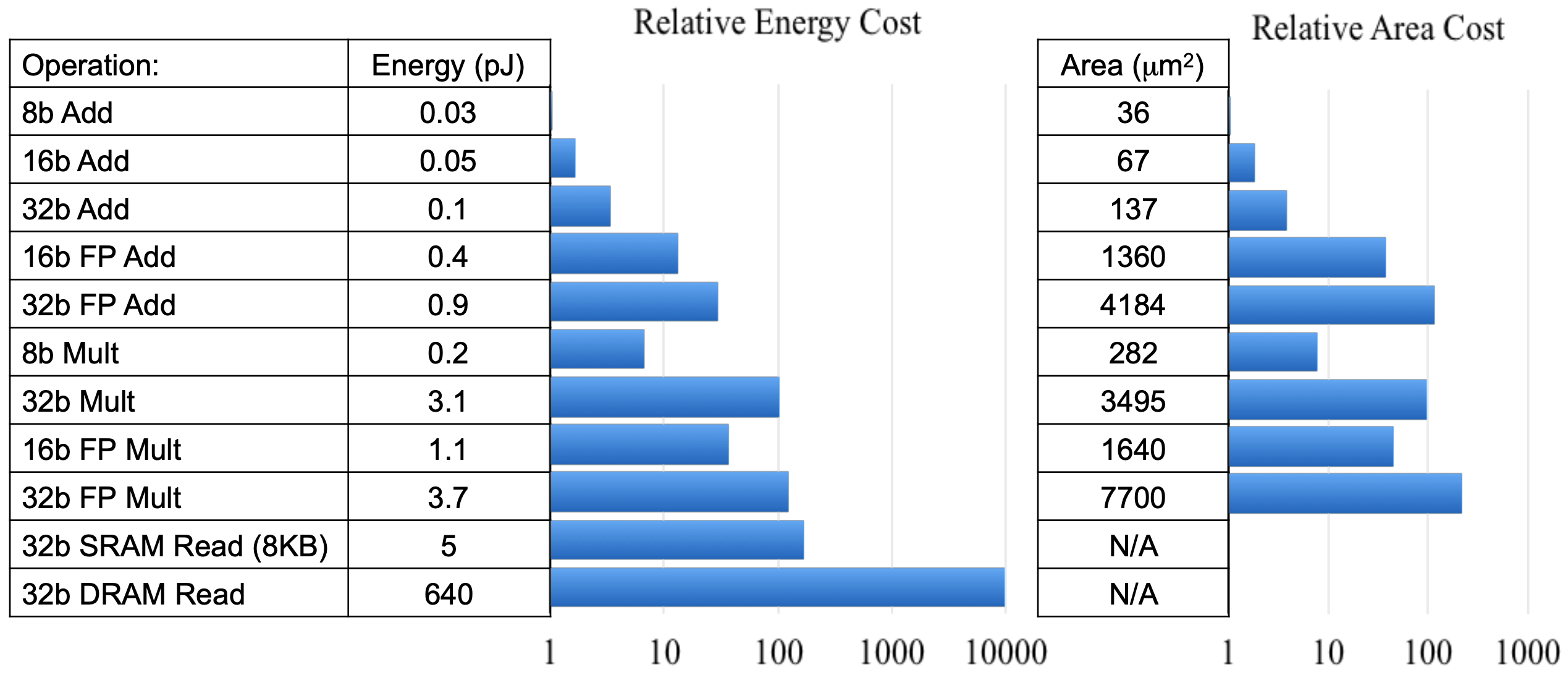
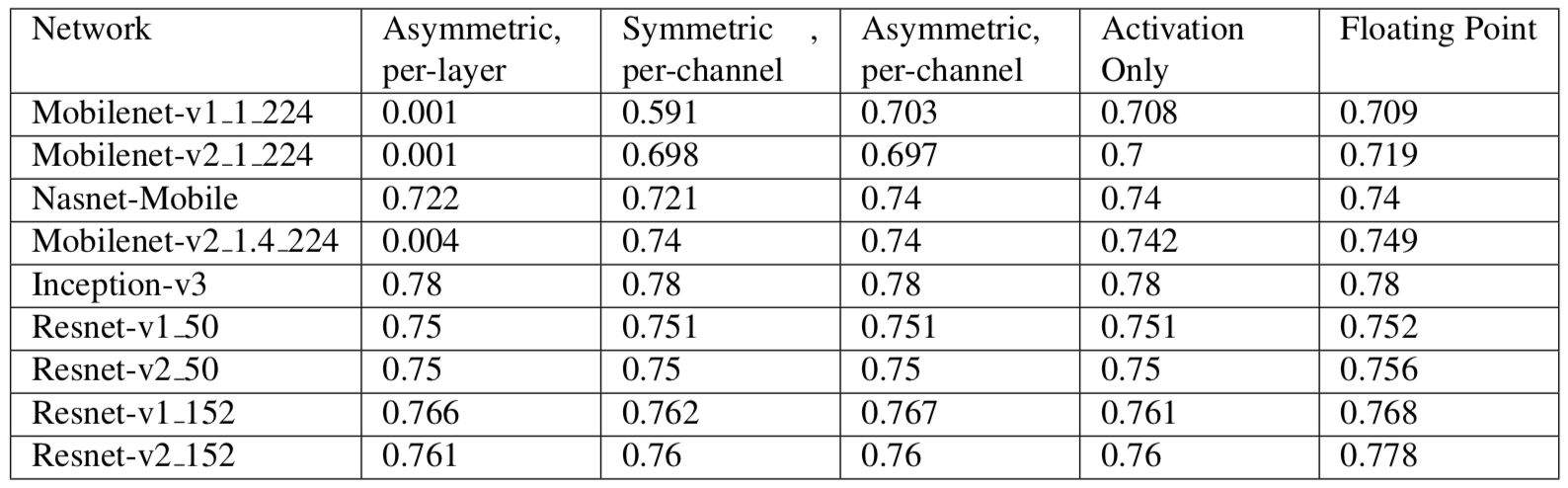
此差异已折叠。