***pretrained_model**: model path for pretraining. Default: None.
***pretrained_model**: model path for pretraining. Default: None.
***checkpoint**: the checkpoint path to resume. Default: None.
***checkpoint**: the checkpoint path to resume. Default: None.
***model_category**: the category of models, ("models"|"models_name"). Default: "models".
Or can start the training step by running the ```run.sh```.
**data reader introduction:** Data reader is defined in ```reader.py```. In [training stage](#training-a-model), random crop and flipping are used, while center crop is used in [evaluation](#inference) and [inference](#inference) stages. Supported data augmentation includes:
**data reader introduction:** Data reader is defined in ```reader.py```. In [training stage](#training-a-model), random crop and flipping are used, while center crop is used in [evaluation](#inference) and [inference](#inference) stages. Supported data augmentation includes:
* rotation
* rotation
...
@@ -183,26 +186,23 @@ Test-12-score: [15.040644], class [386]
...
@@ -183,26 +186,23 @@ Test-12-score: [15.040644], class [386]
## Supported models and performances
## Supported models and performances
Models consists of two categories: Models with specified parameters names in model definition and Models without specified parameters, Generate named model by indicating ```model_category = models_name```.
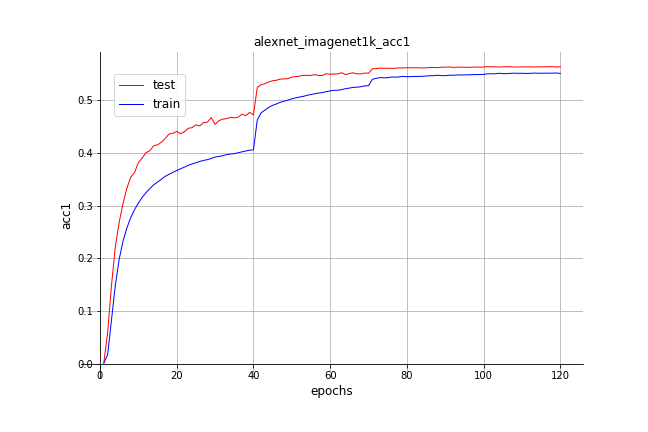
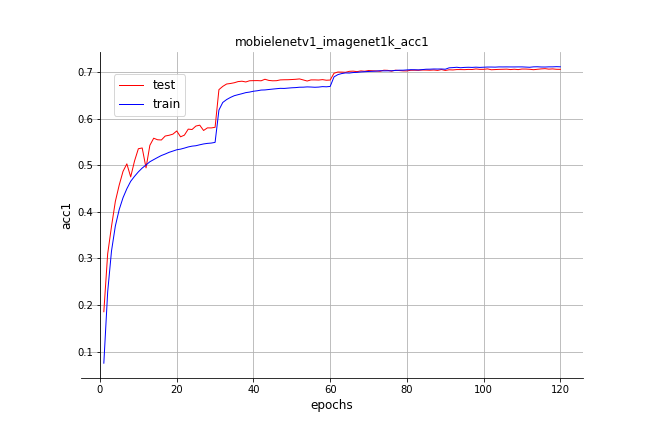
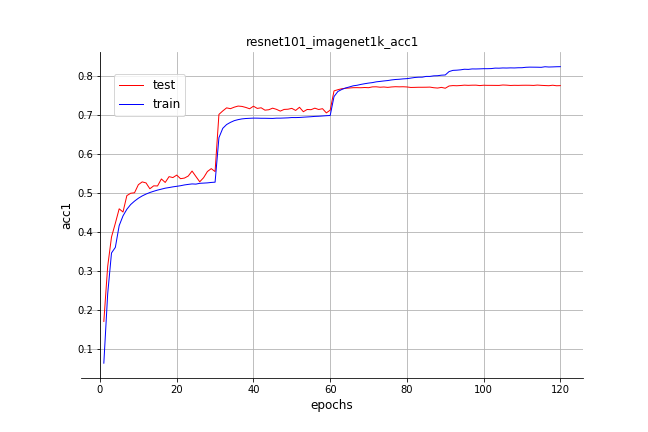
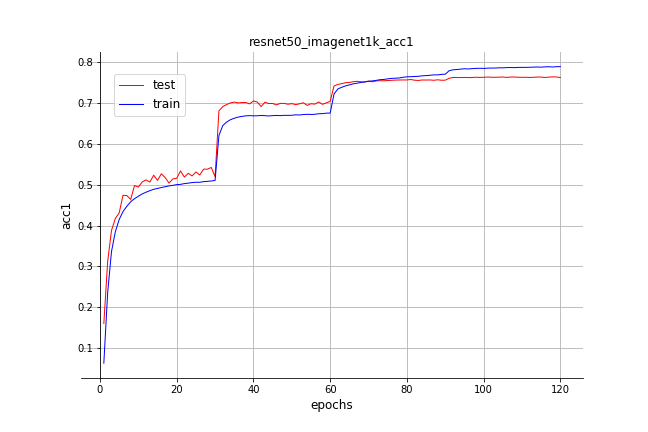
Models are trained by starting with learning rate ```0.1``` and decaying it by ```0.1``` after each pre-defined epoches, if not special introduced. Available top-1/top-5 validation accuracy on ImageNet 2012 are listed in table. Pretrained models can be downloaded by clicking related model names.
Models are trained by starting with learning rate ```0.1``` and decaying it by ```0.1``` after each pre-defined epoches, if not special introduced. Available top-1/top-5 validation accuracy on ImageNet 2012 are listed in table. Pretrained models can be downloaded by clicking related model names.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}