Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
models
提交
07ba10b1
M
models
项目概览
PaddlePaddle
/
models
大约 2 年 前同步成功
通知
232
Star
6828
Fork
2962
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
602
列表
看板
标记
里程碑
合并请求
255
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
M
models
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
602
Issue
602
列表
看板
标记
里程碑
合并请求
255
合并请求
255
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
07ba10b1
编写于
5月 26, 2017
作者:
S
Superjom
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
fix markdown display
上级
04fbeb5e
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
209 addition
and
185 deletion
+209
-185
ctr/README.md
ctr/README.md
+95
-85
ctr/dataset.md
ctr/dataset.md
+114
-100
ctr/images/lr-vs-dnn.jpg
ctr/images/lr-vs-dnn.jpg
+0
-0
ctr/images/wide-deep.png
ctr/images/wide-deep.png
+0
-0
未找到文件。
ctr/README.md
浏览文件 @
07ba10b1
...
@@ -2,29 +2,29 @@
...
@@ -2,29 +2,29 @@
<h2>
Table of Contents
</h2>
<h2>
Table of Contents
</h2>
<div
id=
"text-table-of-contents"
>
<div
id=
"text-table-of-contents"
>
<ul>
<ul>
<li><a
href=
"#org
50629cf
"
>
1. 背景介绍
</a>
<li><a
href=
"#org
466cf34
"
>
1. 背景介绍
</a>
<ul>
<ul>
<li><a
href=
"#org
82d29f2
"
>
1.1. LR vs DNN
</a></li>
<li><a
href=
"#org
f06d0ce
"
>
1.1. LR vs DNN
</a></li>
</ul>
</ul>
</li>
</li>
<li><a
href=
"#org
71b628e
"
>
2. 数据和任务抽象
</a></li>
<li><a
href=
"#org
b599ca8
"
>
2. 数据和任务抽象
</a></li>
<li><a
href=
"#org
a33b812
"
>
3. Wide
&
Deep Learning Model
</a>
<li><a
href=
"#org
9ca5c95
"
>
3. Wide
&
Deep Learning Model
</a>
<ul>
<ul>
<li><a
href=
"#org8
3aff73
"
>
3.1. 模型简介
</a></li>
<li><a
href=
"#org8
ce8325
"
>
3.1. 模型简介
</a></li>
<li><a
href=
"#org
5ea2bba
"
>
3.2. 编写模型输入
</a></li>
<li><a
href=
"#org
7c4e5de
"
>
3.2. 编写模型输入
</a></li>
<li><a
href=
"#org1
7c16e7
"
>
3.3. 编写 Wide 部分
</a></li>
<li><a
href=
"#org1
8b2115
"
>
3.3. 编写 Wide 部分
</a></li>
<li><a
href=
"#org
ed3e908
"
>
3.4. 编写 Deep 部分
</a></li>
<li><a
href=
"#org
80d7554
"
>
3.4. 编写 Deep 部分
</a></li>
<li><a
href=
"#org
80056a6
"
>
3.5. 两者融合
</a></li>
<li><a
href=
"#org
e8947b8
"
>
3.5. 两者融合
</a></li>
<li><a
href=
"#org
6afcbfa
"
>
3.6. 训练任务的定义
</a></li>
<li><a
href=
"#org
af3e9f2
"
>
3.6. 训练任务的定义
</a></li>
</ul>
</ul>
</li>
</li>
<li><a
href=
"#org
bfe2993
"
>
4. 引用
</a></li>
<li><a
href=
"#org
ad3893f
"
>
4. 引用
</a></li>
</ul>
</ul>
</div>
</div>
</div>
</div>
<a
id=
"org
50629cf
"
></a>
<a
id=
"org
466cf34
"
></a>
# 背景介绍
# 背景介绍
...
@@ -51,7 +51,7 @@ CTR(Click-through rate) 是用来表示用户点击一个特定链接的概率
...
@@ -51,7 +51,7 @@ CTR(Click-through rate) 是用来表示用户点击一个特定链接的概率
逐渐地接过 CTR 预估任务的大旗。
逐渐地接过 CTR 预估任务的大旗。
<a
id=
"org
82d29f2
"
></a>
<a
id=
"org
f06d0ce
"
></a>
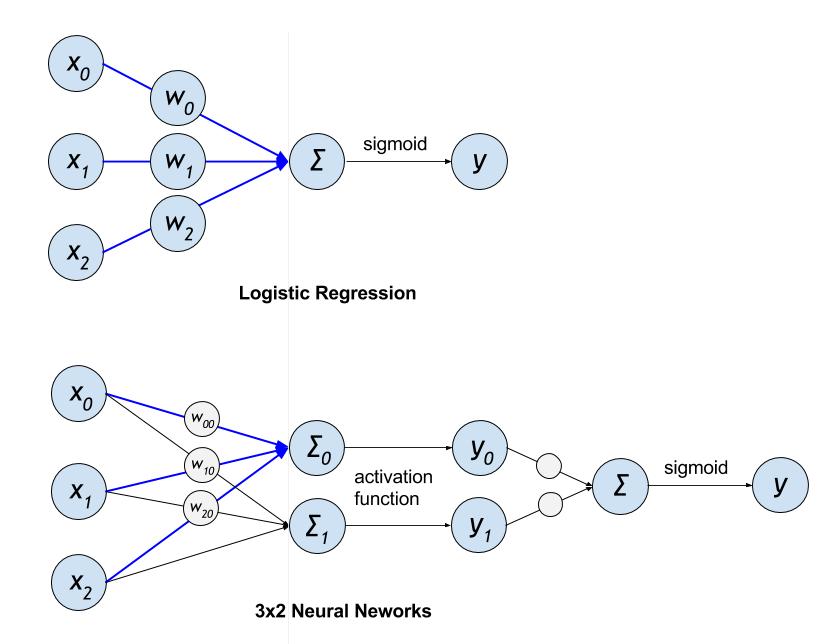
## LR vs DNN
## LR vs DNN
...
@@ -73,7 +73,7 @@ LR 对于 NN 模型的优势是对大规模稀疏特征的容纳能力,包括
...
@@ -73,7 +73,7 @@ LR 对于 NN 模型的优势是对大规模稀疏特征的容纳能力,包括
本文后面的章节会演示如何使用 PaddlePaddle 编写一个结合两者优点的模型。
本文后面的章节会演示如何使用 PaddlePaddle 编写一个结合两者优点的模型。
<a
id=
"org
71b628e
"
></a>
<a
id=
"org
b599ca8
"
></a>
# 数据和任务抽象
# 数据和任务抽象
...
@@ -90,14 +90,14 @@ LR 对于 NN 模型的优势是对大规模稀疏特征的容纳能力,包括
...
@@ -90,14 +90,14 @@ LR 对于 NN 模型的优势是对大规模稀疏特征的容纳能力,包括
具体的特征处理方法参看
[
data process
](
./dataset.md
)
具体的特征处理方法参看
[
data process
](
./dataset.md
)
<a
id=
"org
a33b812
"
></a>
<a
id=
"org
9ca5c95
"
></a>
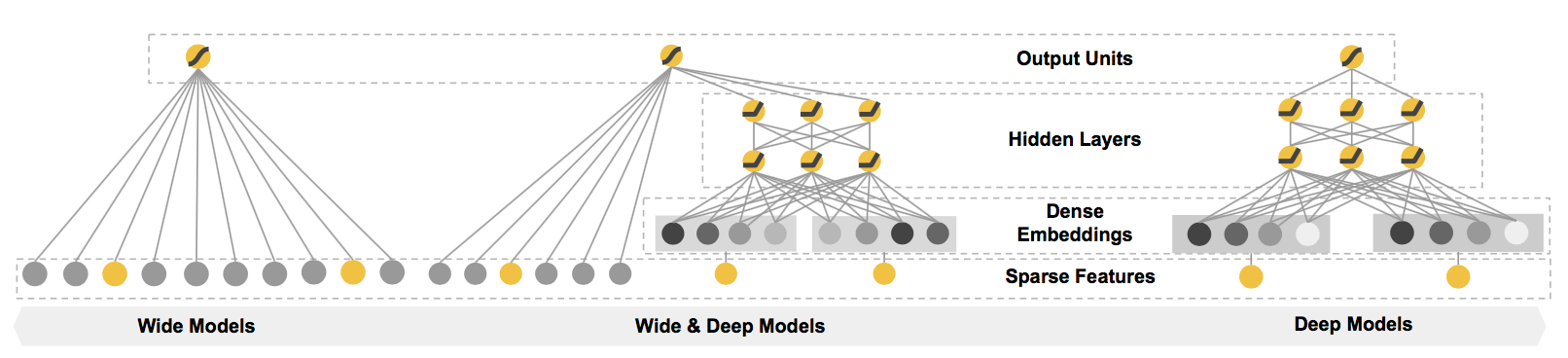
# Wide & Deep Learning Model
# Wide & Deep Learning Model
谷歌在 16 年提出了 Wide & Deep Learning 的模型框架,用于融合适合学习抽象特征的 DNN 和 适用于大规模稀疏特征的 LR 两种模型的优点。
谷歌在 16 年提出了 Wide & Deep Learning 的模型框架,用于融合适合学习抽象特征的 DNN 和 适用于大规模稀疏特征的 LR 两种模型的优点。
<a
id=
"org8
3aff73
"
></a>
<a
id=
"org8
ce8325
"
></a>
## 模型简介
## 模型简介
...
@@ -112,7 +112,7 @@ Wide & Deep Learning Model 可以作为一种相对成熟的模型框架使用
...
@@ -112,7 +112,7 @@ Wide & Deep Learning Model 可以作为一种相对成熟的模型框架使用
而模型右边的 Deep 部分,能够学习特征间的隐含关系,在相同数量的特征下有更好的学习和推导能力。
而模型右边的 Deep 部分,能够学习特征间的隐含关系,在相同数量的特征下有更好的学习和推导能力。
<a
id=
"org
5ea2bba
"
></a>
<a
id=
"org
7c4e5de
"
></a>
## 编写模型输入
## 编写模型输入
...
@@ -123,51 +123,57 @@ Wide & Deep Learning Model 可以作为一种相对成熟的模型框架使用
...
@@ -123,51 +123,57 @@ Wide & Deep Learning Model 可以作为一种相对成熟的模型框架使用
-
`click`
, 点击与否,作为二分类模型学习的标签
-
`click`
, 点击与否,作为二分类模型学习的标签
```
python
```
python
dnn_merged_input
=
layer
.
data
(
dnn_merged_input
=
layer
.
data
(
name
=
'dnn_input'
,
name
=
'dnn_input'
,
type
=
paddle
.
data_type
.
sparse_binary_vector
(
data_meta_info
[
'dnn_input'
]))
type
=
paddle
.
data_type
.
sparse_binary_vector
(
data_meta_info
[
'dnn_input'
]))
lr_merged_input
=
layer
.
data
(
lr_merged_input
=
layer
.
data
(
name
=
'lr_input'
,
name
=
'lr_input'
,
type
=
paddle
.
data_type
.
sparse_binary_vector
(
data_meta_info
[
'lr_input'
]))
type
=
paddle
.
data_type
.
sparse_binary_vector
(
data_meta_info
[
'lr_input'
]))
click
=
paddle
.
layer
.
data
(
name
=
'click'
,
type
=
dtype
.
dense_vector
(
1
))
click
=
paddle
.
layer
.
data
(
name
=
'click'
,
type
=
dtype
.
dense_vector
(
1
))
<
a
id
=
"org17c16e7"
></
a
>
```
<a
id=
"org18b2115"
></a>
## 编写 Wide 部分
## 编写 Wide 部分
Wide 部分直接使用了 LR 模型,但激活函数改成了
`RELU`
来加速
Wide 部分直接使用了 LR 模型,但激活函数改成了
`RELU`
来加速
```
python
```
python
def build_lr_submodel():
def
build_lr_submodel
():
fc = layer.fc(
fc
=
layer
.
fc
(
input=lr_merged_input, size=1, name='lr', act=paddle.activation.Relu())
input
=
lr_merged_input
,
size
=
1
,
name
=
'lr'
,
act
=
paddle
.
activation
.
Relu
())
return fc
return
fc
<a
id=
"orged3e908"
></a>
```
<a
id=
"org80d7554"
></a>
## 编写 Deep 部分
## 编写 Deep 部分
Deep 部分使用了标准的多层前向传导的 NN 模型
Deep 部分使用了标准的多层前向传导的 NN 模型
```
python
```
python
def
build_dnn_submodel
(
dnn_layer_dims
):
def
build_dnn_submodel
(
dnn_layer_dims
):
dnn_embedding
=
layer
.
fc
(
input
=
dnn_merged_input
,
size
=
dnn_layer_dims
[
0
])
dnn_embedding
=
layer
.
fc
(
input
=
dnn_merged_input
,
size
=
dnn_layer_dims
[
0
])
_input_layer
=
dnn_embedding
_input_layer
=
dnn_embedding
for
no
,
dim
in
enumerate
(
dnn_layer_dims
[
1
:]):
for
no
,
dim
in
enumerate
(
dnn_layer_dims
[
1
:]):
fc
=
layer
.
fc
(
fc
=
layer
.
fc
(
input
=
_input_layer
,
input
=
_input_layer
,
size
=
dim
,
size
=
dim
,
act
=
paddle
.
activation
.
Relu
(),
act
=
paddle
.
activation
.
Relu
(),
name
=
'dnn-fc-%d'
%
no
)
name
=
'dnn-fc-%d'
%
no
)
_input_layer
=
fc
_input_layer
=
fc
return
_input_layer
return
_input_layer
<
a
id
=
"org80056a6"
></
a
>
```
<a
id=
"orge8947b8"
></a>
## 两者融合
## 两者融合
...
@@ -175,66 +181,70 @@ Deep 部分使用了标准的多层前向传导的 NN 模型
...
@@ -175,66 +181,70 @@ Deep 部分使用了标准的多层前向传导的 NN 模型
来逼近训练数据中二元类别的分布,最终作为 CTR 预估的值使用。
来逼近训练数据中二元类别的分布,最终作为 CTR 预估的值使用。
```
python
```
python
# conbine DNN and LR submodels
# conbine DNN and LR submodels
def combine_submodels(dnn, lr):
def
combine_submodels
(
dnn
,
lr
):
merge_layer = layer.concat(input=[dnn, lr])
merge_layer
=
layer
.
concat
(
input
=
[
dnn
,
lr
])
fc = layer.fc(
fc
=
layer
.
fc
(
input=merge_layer,
input
=
merge_layer
,
size=1,
size
=
1
,
name='output',
name
=
'output'
,
# use sigmoid function to approximate ctr rate, a float value between 0 and 1.
# use sigmoid function to approximate ctr rate, a float value between 0 and 1.
act=paddle.activation.Sigmoid())
act
=
paddle
.
activation
.
Sigmoid
())
return fc
return
fc
<a
id=
"org6afcbfa"
></a>
```
<a
id=
"orgaf3e9f2"
></a>
## 训练任务的定义
## 训练任务的定义
```
python
```
python
dnn
=
build_dnn_submodel
(
dnn_layer_dims
)
dnn
=
build_dnn_submodel
(
dnn_layer_dims
)
lr
=
build_lr_submodel
()
lr
=
build_lr_submodel
()
output
=
combine_submodels
(
dnn
,
lr
)
output
=
combine_submodels
(
dnn
,
lr
)
# ==============================================================================
# cost and train period
# ==============================================================================
classification_cost
=
paddle
.
layer
.
multi_binary_label_cross_entropy_cost
(
input
=
output
,
label
=
click
)
# ==============================================================================
params
=
paddle
.
parameters
.
create
(
classification_cost
)
# cost and train period
# ==============================================================================
classification_cost
=
paddle
.
layer
.
multi_binary_label_cross_entropy_cost
(
input
=
output
,
label
=
click
)
params
=
paddle
.
parameters
.
create
(
classification_cost
)
optimizer
=
paddle
.
optimizer
.
Momentum
(
momentum
=
0
)
optimizer
=
paddle
.
optimizer
.
Momentum
(
momentum
=
0
)
trainer
=
paddle
.
trainer
.
SGD
(
cost
=
classification_cost
,
parameters
=
params
,
update_equation
=
optimizer
)
trainer
=
paddle
.
trainer
.
SGD
(
dataset
=
AvazuDataset
(
train_data_path
,
n_records_as_test
=
test_set_size
)
cost
=
classification_cost
,
parameters
=
params
,
update_equation
=
optimizer
)
dataset
=
AvazuDataset
(
train_data_path
,
n_records_as_test
=
test_set_size
)
def
event_handler
(
event
):
if
isinstance
(
event
,
paddle
.
event
.
EndIteration
):
if
event
.
batch_id
%
100
==
0
:
logging
.
warning
(
"Pass %d, Samples %d, Cost %f"
%
(
event
.
pass_id
,
event
.
batch_id
*
batch_size
,
event
.
cost
))
def
event_handler
(
event
):
if
event
.
batch_id
%
1000
==
0
:
if
isinstance
(
event
,
paddle
.
event
.
EndIteration
):
result
=
trainer
.
test
(
if
event
.
batch_id
%
100
==
0
:
reader
=
paddle
.
batch
(
dataset
.
test
,
batch_size
=
1000
),
logging
.
warning
(
"Pass %d, Samples %d, Cost %f"
%
(
feeding
=
field_index
)
event
.
pass_id
,
event
.
batch_id
*
batch_size
,
event
.
cost
))
logging
.
warning
(
"Test %d-%d, Cost %f"
%
(
event
.
pass_id
,
event
.
batch_id
,
result
.
cost
))
if
event
.
batch_id
%
1000
==
0
:
result
=
trainer
.
test
(
reader
=
paddle
.
batch
(
dataset
.
test
,
batch_size
=
1000
),
feeding
=
field_index
)
logging
.
warning
(
"Test %d-%d, Cost %f"
%
(
event
.
pass_id
,
event
.
batch_id
,
result
.
cost
))
trainer
.
train
(
reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
dataset
.
train
,
buf_size
=
500
),
batch_size
=
batch_size
),
feeding
=
field_index
,
event_handler
=
event_handler
,
num_passes
=
100
)
trainer
.
train
(
reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
dataset
.
train
,
buf_size
=
500
),
batch_size
=
batch_size
),
feeding
=
field_index
,
event_handler
=
event_handler
,
num_passes
=
100
)
```
<
a
id
=
"org
bfe2993
"
></
a
>
<a
id=
"org
ad3893f
"
></a>
# 引用
# 引用
...
...
ctr/dataset.md
浏览文件 @
07ba10b1
...
@@ -2,34 +2,34 @@
...
@@ -2,34 +2,34 @@
<h2>
Table of Contents
</h2>
<h2>
Table of Contents
</h2>
<div
id=
"text-table-of-contents"
>
<div
id=
"text-table-of-contents"
>
<ul>
<ul>
<li><a
href=
"#org
a96c5e8
"
>
1. 数据集介绍
</a></li>
<li><a
href=
"#org
c5babdf
"
>
1. 数据集介绍
</a></li>
<li><a
href=
"#org
e73ddcc
"
>
2. 特征提取
</a>
<li><a
href=
"#org
bbc9886
"
>
2. 特征提取
</a>
<ul>
<ul>
<li><a
href=
"#org
be379b1
"
>
2.1. 类别类特征
</a></li>
<li><a
href=
"#org
ce8b3e2
"
>
2.1. 类别类特征
</a></li>
<li><a
href=
"#org
811ca7c
"
>
2.2. ID 类特征
</a></li>
<li><a
href=
"#org
36ef5ff
"
>
2.2. ID 类特征
</a></li>
<li><a
href=
"#org
c1d7d23
"
>
2.3. 数值型特征
</a></li>
<li><a
href=
"#org
86e6ead
"
>
2.3. 数值型特征
</a></li>
</ul>
</ul>
</li>
</li>
<li><a
href=
"#org
609b660
"
>
3. 特征处理
</a>
<li><a
href=
"#org
b22787c
"
>
3. 特征处理
</a>
<ul>
<ul>
<li><a
href=
"#org
5fdd532
"
>
3.1. 类别型特征
</a></li>
<li><a
href=
"#org
e3814aa
"
>
3.1. 类别型特征
</a></li>
<li><a
href=
"#org
ad85d3e
"
>
3.2. ID 类特征
</a></li>
<li><a
href=
"#org
0d48201
"
>
3.2. ID 类特征
</a></li>
<li><a
href=
"#org
0cbe90e
"
>
3.3. 交叉类特征
</a></li>
<li><a
href=
"#org
399e146
"
>
3.3. 交叉类特征
</a></li>
<li><a
href=
"#org
4bdb372
"
>
3.4. 特征维度
</a>
<li><a
href=
"#org
2ce9054
"
>
3.4. 特征维度
</a>
<ul>
<ul>
<li><a
href=
"#org0
530a25
"
>
3.4.1. Deep submodel(DNN)特征
</a></li>
<li><a
href=
"#org0
2df08b
"
>
3.4.1. Deep submodel(DNN)特征
</a></li>
<li><a
href=
"#org
ed20ff2
"
>
3.4.2. Wide submodel(LR)特征
</a></li>
<li><a
href=
"#org
76983ab
"
>
3.4.2. Wide submodel(LR)特征
</a></li>
</ul>
</ul>
</li>
</li>
</ul>
</ul>
</li>
</li>
<li><a
href=
"#org
70ad7d8
"
>
4. 输入到 PaddlePaddle 中
</a></li>
<li><a
href=
"#org
38b7a5c
"
>
4. 输入到 PaddlePaddle 中
</a></li>
</ul>
</ul>
</div>
</div>
</div>
</div>
<a
id=
"org
a96c5e8
"
></a>
<a
id=
"org
c5babdf
"
></a>
# 数据集介绍
# 数据集介绍
...
@@ -54,7 +54,7 @@
...
@@ -54,7 +54,7 @@
-
C14-C21
–
anonymized categorical variables
-
C14-C21
–
anonymized categorical variables
<a
id=
"org
e73ddcc
"
></a>
<a
id=
"org
bbc9886
"
></a>
# 特征提取
# 特征提取
...
@@ -64,24 +64,30 @@
...
@@ -64,24 +64,30 @@
1.
ID 类特征(稀疏,数量多)
1.
ID 类特征(稀疏,数量多)
```
python
```
python
-
id
-
id
-
site
<
sub
>
id
</
sub
>
-
site
<
sub
>
id
</
sub
>
-
app
<
sub
>
id
</
sub
>
-
app
<
sub
>
id
</
sub
>
-
device
<
sub
>
id
</
sub
>
-
device
<
sub
>
id
</
sub
>
```
2.
类别类特征(稀疏,但数量有限)
2.
类别类特征(稀疏,但数量有限)
```
python
```
python
-
C1
-
C1
-
site
<sub>
category
</sub>
-
site
<
sub
>
category
</
sub
>
-
device
<sub>
type
</sub>
-
device
<
sub
>
type
</
sub
>
-
C14-C21
-
C14
-
C21
```
3.
数值型特征转化为类别型特征
3.
数值型特征转化为类别型特征
```
python
```
python
-
hour
(
可以转化成数值
,
也可以按小时为单位转化为类别
)
-
hour
(
可以转化成数值
,
也可以按小时为单位转化为类别
)
```
<
a
id
=
"org
be379b1
"
></
a
>
<a
id=
"org
ce8b3e2
"
></a>
## 类别类特征
## 类别类特征
...
@@ -91,7 +97,7 @@
...
@@ -91,7 +97,7 @@
2.
类似词向量,用一个 Embedding Table 将每个类别映射到对应的向量
2.
类似词向量,用一个 Embedding Table 将每个类别映射到对应的向量
<
a
id
=
"org
811ca7c
"
></
a
>
<a
id=
"org
36ef5ff
"
></a>
## ID 类特征
## ID 类特征
...
@@ -106,7 +112,7 @@ ID 类特征的特点是稀疏数据,但量比较大,直接使用 One-hot
...
@@ -106,7 +112,7 @@ ID 类特征的特点是稀疏数据,但量比较大,直接使用 One-hot
上面的方法尽管存在一定的碰撞概率,但能够处理任意数量的 ID 特征,并保留一定的效果[2]。
上面的方法尽管存在一定的碰撞概率,但能够处理任意数量的 ID 特征,并保留一定的效果[2]。
<
a
id
=
"org
c1d7d23
"
></
a
>
<a
id=
"org
86e6ead
"
></a>
## 数值型特征
## 数值型特征
...
@@ -116,12 +122,12 @@ ID 类特征的特点是稀疏数据,但量比较大,直接使用 One-hot
...
@@ -116,12 +122,12 @@ ID 类特征的特点是稀疏数据,但量比较大,直接使用 One-hot
-
用区间分割处理成类别类特征,稀疏化表示,模糊细微上的差别
-
用区间分割处理成类别类特征,稀疏化表示,模糊细微上的差别
<
a
id
=
"org
609b660
"
></
a
>
<a
id=
"org
b22787c
"
></a>
# 特征处理
# 特征处理
<
a
id
=
"org
5fdd532
"
></
a
>
<a
id=
"org
e3814aa
"
></a>
## 类别型特征
## 类别型特征
...
@@ -130,46 +136,48 @@ ID 类特征的特点是稀疏数据,但量比较大,直接使用 One-hot
...
@@ -130,46 +136,48 @@ ID 类特征的特点是稀疏数据,但量比较大,直接使用 One-hot
这种特征在输入到模型时,一般使用 One-hot 表示,相关处理方法如下:
这种特征在输入到模型时,一般使用 One-hot 表示,相关处理方法如下:
```
python
```
python
class CategoryFeatureGenerator(object):
class
CategoryFeatureGenerator
(
object
):
'''
Generator category features.
Register all records by calling ~register~ first, then call ~gen~ to generate
one-hot representation for a record.
'''
def
__init__
(
self
):
self
.
dic
=
{
'unk'
:
0
}
self
.
counter
=
1
def
register
(
self
,
key
):
'''
Register record.
'''
'''
Generator category features.
if
key
not
in
self
.
dic
:
self
.
dic
[
key
]
=
self
.
counter
self
.
counter
+=
1
Register all records by calling ~register~ first, then call ~gen~ to generate
def
size
(
self
):
one-hot representation for a record.
return
len
(
self
.
dic
)
def
gen
(
self
,
key
):
'''
Generate one-hot representation for a record.
'''
'''
if
key
not
in
self
.
dic
:
res
=
self
.
dic
[
'unk'
]
else
:
res
=
self
.
dic
[
key
]
return
[
res
]
def
__repr__
(
self
):
return
'<CategoryFeatureGenerator %d>'
%
len
(
self
.
dic
)
def __init__(self):
```
self.dic = {'unk': 0}
self.counter = 1
def register(self, key):
'''
Register record.
'''
if key not in self.dic:
self.dic[key] = self.counter
self.counter += 1
def size(self):
return len(self.dic)
def gen(self, key):
'''
Generate one-hot representation for a record.
'''
if key not in self.dic:
res = self.dic['unk']
else:
res = self.dic[key]
return [res]
def __repr__(self):
return '<CategoryFeatureGenerator %d>' % len(self.dic)
本任务中,类别类特征会输入到 DNN 中使用。
本任务中,类别类特征会输入到 DNN 中使用。
<a
id=
"org
ad85d3e
"
></a>
<a
id=
"org
0d48201
"
></a>
## ID 类特征
## ID 类特征
...
@@ -177,25 +185,27 @@ ID 类特征代稀疏值,且值的空间很大的情况,一般用模操作
...
@@ -177,25 +185,27 @@ ID 类特征代稀疏值,且值的空间很大的情况,一般用模操作
之后可以当成类别类特征使用,这里我们会将 ID 类特征输入到 LR 模型中使用。
之后可以当成类别类特征使用,这里我们会将 ID 类特征输入到 LR 模型中使用。
```
python
```
python
class
IDfeatureGenerator
(
object
):
class
IDfeatureGenerator
(
object
):
def
__init__
(
self
,
max_dim
):
def
__init__
(
self
,
max_dim
):
'''
'''
@max_dim: int
@max_dim: int
Size of the id elements' space
Size of the id elements' space
'''
'''
self
.
max_dim
=
max_dim
self
.
max_dim
=
max_dim
def
gen
(
self
,
key
):
'''
Generate one-hot representation for records
'''
return
[
hash
(
key
)
%
self
.
max_dim
]
def
gen
(
self
,
key
):
def
size
(
self
):
'''
return
self
.
max_dim
Generate one-hot representation for records
'''
return
[
hash
(
key
)
%
self
.
max_dim
]
def
size
(
self
):
return
self
.
max_dim
```
<
a
id
=
"org
0cbe90e
"
></
a
>
<a
id=
"org
399e146
"
></a>
## 交叉类特征
## 交叉类特征
...
@@ -205,20 +215,22 @@ LR 模型作为 Wide & Deep model 的 `wide` 部分,可以输入很 wide 的
...
@@ -205,20 +215,22 @@ LR 模型作为 Wide & Deep model 的 `wide` 部分,可以输入很 wide 的
这里我们依旧使用模操作来约束最终组合出的特征空间的大小,具体实现是直接在
`IDfeatureGenerator`
中添加一个~gen
<sub>
cross
</sub><sub>
feature
</sub>
~ 的方法:
这里我们依旧使用模操作来约束最终组合出的特征空间的大小,具体实现是直接在
`IDfeatureGenerator`
中添加一个~gen
<sub>
cross
</sub><sub>
feature
</sub>
~ 的方法:
```
python
```
python
def gen_cross_fea(self, fea1, fea2):
def
gen_cross_fea
(
self
,
fea1
,
fea2
):
key = str(fea1) + str(fea2)
key
=
str
(
fea1
)
+
str
(
fea2
)
return self.gen(key)
return
self
.
gen
(
key
)
```
比如,我们觉得原始数据中,
`device_id`
和
`site_id`
有一些关联(比如某个 device 倾向于浏览特定 site),
比如,我们觉得原始数据中,
`device_id`
和
`site_id`
有一些关联(比如某个 device 倾向于浏览特定 site),
我们通过组合出两者组合来捕捉这类信息。
我们通过组合出两者组合来捕捉这类信息。
<a
id=
"org
4bdb372
"
></a>
<a
id=
"org
2ce9054
"
></a>
## 特征维度
## 特征维度
<a
id=
"org0
530a25
"
></a>
<a
id=
"org0
2df08b
"
></a>
### Deep submodel(DNN)特征
### Deep submodel(DNN)特征
...
@@ -277,7 +289,7 @@ LR 模型作为 Wide & Deep model 的 `wide` 部分,可以输入很 wide 的
...
@@ -277,7 +289,7 @@ LR 模型作为 Wide & Deep model 的 `wide` 部分,可以输入很 wide 的
</table>
</table>
<a
id=
"org
ed20ff2
"
></a>
<a
id=
"org
76983ab
"
></a>
### Wide submodel(LR)特征
### Wide submodel(LR)特征
...
@@ -336,7 +348,7 @@ LR 模型作为 Wide & Deep model 的 `wide` 部分,可以输入很 wide 的
...
@@ -336,7 +348,7 @@ LR 模型作为 Wide & Deep model 的 `wide` 部分,可以输入很 wide 的
</table>
</table>
<a
id=
"org
70ad7d8
"
></a>
<a
id=
"org
38b7a5c
"
></a>
# 输入到 PaddlePaddle 中
# 输入到 PaddlePaddle 中
...
@@ -350,23 +362,25 @@ Deep 和 Wide 两部分均以 `sparse_binary_vector` 的格式[1]输入,输入
...
@@ -350,23 +362,25 @@ Deep 和 Wide 两部分均以 `sparse_binary_vector` 的格式[1]输入,输入
拼合特征的方法:
拼合特征的方法:
```
python
```
python
def
concat_sparse_vectors
(
inputs
,
dims
):
def
concat_sparse_vectors
(
inputs
,
dims
):
'''
'''
concaterate sparse vectors into one
concaterate sparse vectors into one
@inputs: list
@inputs: list
list of sparse vector
list of sparse vector
@dims: list of int
@dims: list of int
dimention of each sparse vector
dimention of each sparse vector
'''
'''
res
=
[]
res
=
[]
assert
len
(
inputs
)
==
len
(
dims
)
assert
len
(
inputs
)
==
len
(
dims
)
start
=
0
start
=
0
for
no
,
vec
in
enumerate
(
inputs
):
for
no
,
vec
in
enumerate
(
inputs
):
for
v
in
vec
:
for
v
in
vec
:
res
.
append
(
v
+
start
)
res
.
append
(
v
+
start
)
start
+=
dims
[
no
]
start
+=
dims
[
no
]
return
res
return
res
```
[1]
<https://github.com/PaddlePaddle/Paddle/blob/develop/doc/api/v1/data_provider/pydataprovider2_en.rst>
[1]
<https://github.com/PaddlePaddle/Paddle/blob/develop/doc/api/v1/data_provider/pydataprovider2_en.rst>
ctr/images/lr-vs-dnn.jpg
0 → 100644
浏览文件 @
07ba10b1
43.1 KB
ctr/images/wide-deep.png
0 → 100644
浏览文件 @
07ba10b1
139.6 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}