
fix inference log (#5401)
* fix inference log * add train infer python md * fix
Showing
{kind=link}
{kind=link}
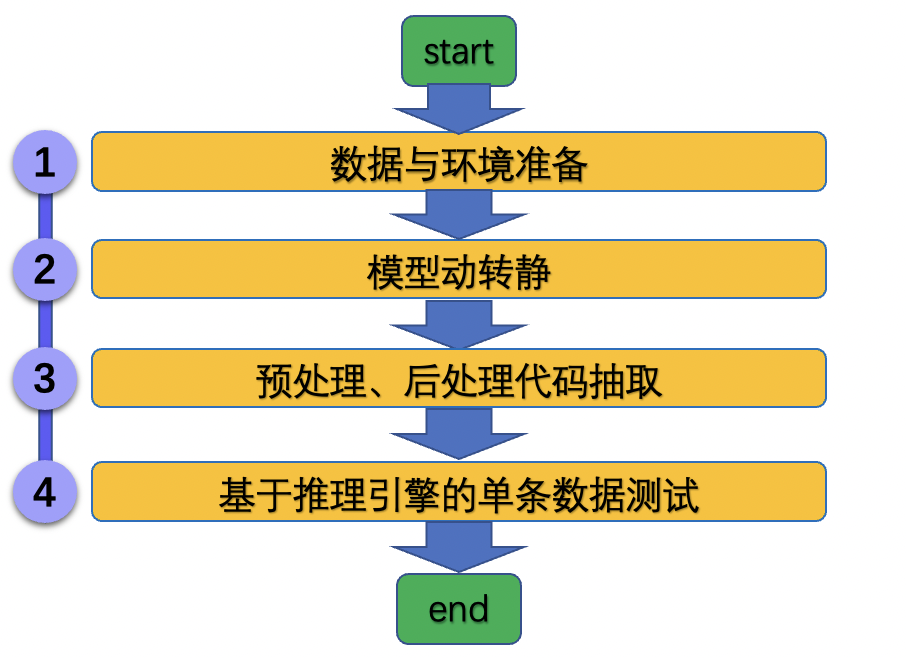
| W: | H:
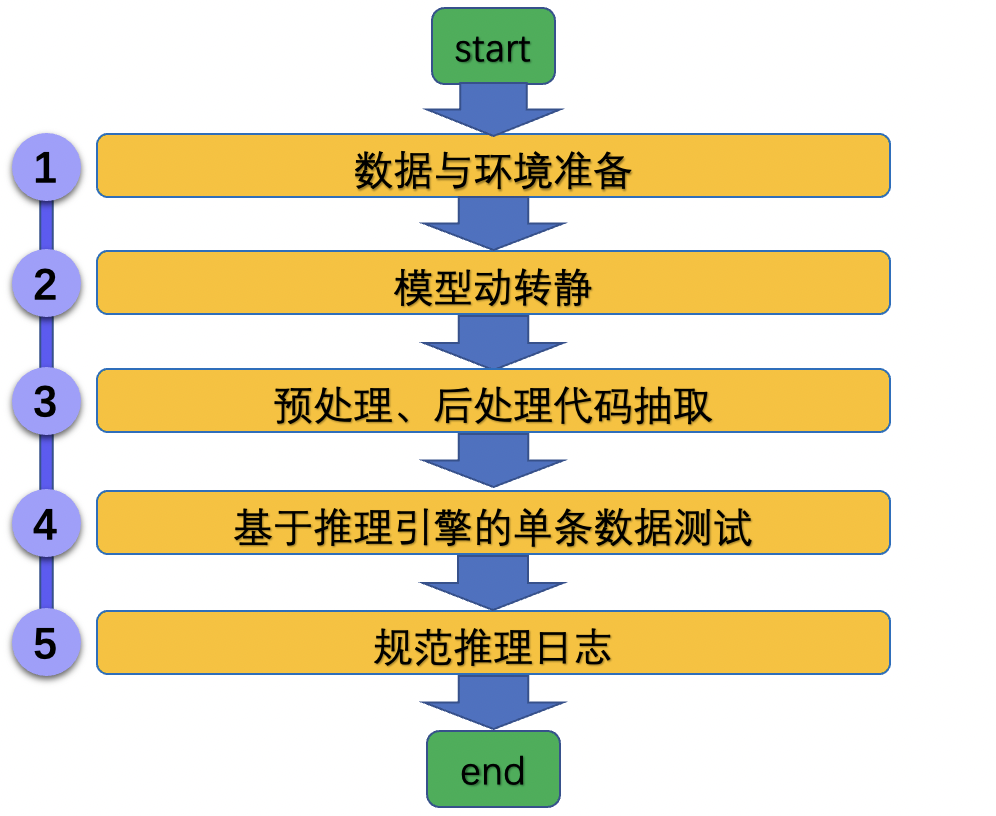
| W: | H:
docs/tipc/train_infer_python.md
0 → 100644
* fix inference log * add train infer python md * fix
| W: | H:
| W: | H: