Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
hapi
提交
ed0360ea
H
hapi
项目概览
PaddlePaddle
/
hapi
通知
11
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
4
列表
看板
标记
里程碑
合并请求
7
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
H
hapi
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
4
Issue
4
列表
看板
标记
里程碑
合并请求
7
合并请求
7
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
ed0360ea
编写于
4月 01, 2020
作者:
D
dengkaipeng
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add image and dataset
上级
285753a9
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
211 addition
and
2 deletion
+211
-2
tsm/README.md
tsm/README.md
+2
-2
tsm/dataset/README.md
tsm/dataset/README.md
+78
-0
tsm/dataset/kinetics/generate_label.py
tsm/dataset/kinetics/generate_label.py
+44
-0
tsm/dataset/kinetics/video2pkl.py
tsm/dataset/kinetics/video2pkl.py
+87
-0
tsm/images/temporal_shift.png
tsm/images/temporal_shift.png
+0
-0
未找到文件。
tsm/README.md
浏览文件 @
ed0360ea
...
...
@@ -14,7 +14,7 @@
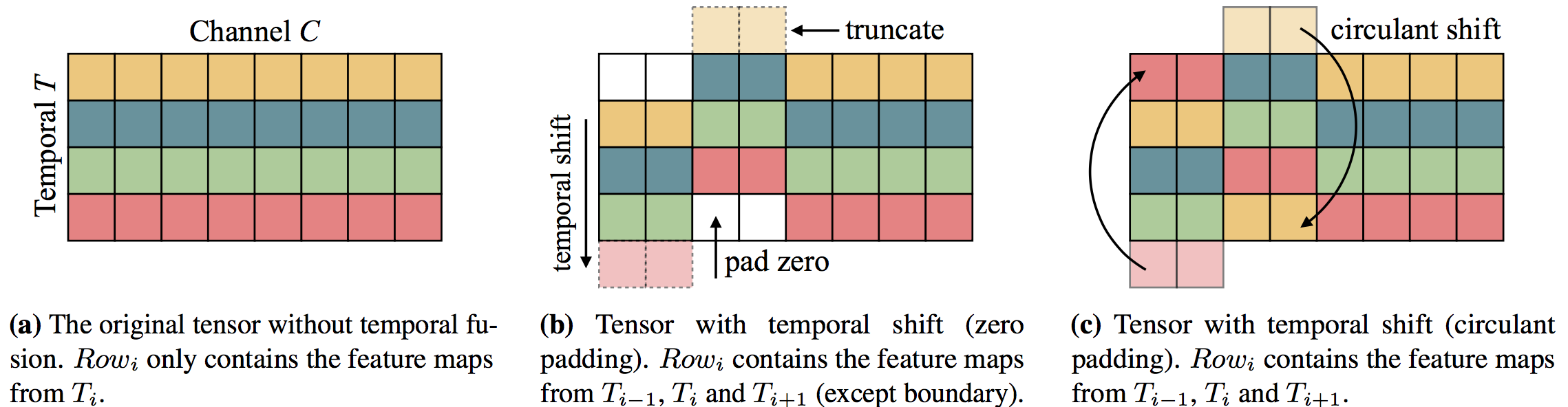
Temporal Shift Module是由MIT和IBM Watson AI Lab的Ji Lin,Chuang Gan和Song Han等人提出的通过时间位移来提高网络视频理解能力的模块,其位移操作原理如下图所示。
<p
align=
"center"
>
<img
src=
".
./..
/images/temporal_shift.png"
height=
250
width=
800
hspace=
'10'
/>
<br
/>
<img
src=
"./images/temporal_shift.png"
height=
250
width=
800
hspace=
'10'
/>
<br
/>
Temporal shift module
</p>
...
...
@@ -44,7 +44,7 @@ TSM模型是将Temporal Shift Module插入到ResNet网络中构建的视频分
### 数据准备
TSM的训练数据采用由DeepMind公布的Kinetics-400动作识别数据集。数据下载及准备请参考
[
数据说明
](
https://github.com/PaddlePaddle/models/blob/release/1.7/PaddleCV/video/data
/dataset/README.md
)
TSM的训练数据采用由DeepMind公布的Kinetics-400动作识别数据集。数据下载及准备请参考
[
数据说明
](
.
/dataset/README.md
)
#### 小数据集验证
...
...
tsm/dataset/README.md
0 → 100644
浏览文件 @
ed0360ea
# 数据使用说明
## Kinetics数据集
Kinetics数据集是DeepMind公开的大规模视频动作识别数据集,有Kinetics400与Kinetics600两个版本。这里使用Kinetics400数据集,具体的数据预处理过程如下。
### mp4视频下载
在Code
\_
Root目录下创建文件夹
cd $Code_Root/data/dataset && mkdir kinetics
cd kinetics && mkdir data_k400 && cd data_k400
mkdir train_mp4 && mkdir val_mp4
ActivityNet官方提供了Kinetics的下载工具,具体参考其
[
官方repo
](
https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics
)
即可下载Kinetics400的mp4视频集合。将kinetics400的训练与验证集合分别下载到data/dataset/kinetics/data
\_
k400/train
\_
mp4与data/dataset/kinetics/data
\_
k400/val
\_
mp4。
### mp4文件预处理
为提高数据读取速度,提前将mp4文件解帧并打pickle包,dataloader从视频的pkl文件中读取数据(该方法耗费更多存储空间)。pkl文件里打包的内容为(video-id, label, [frame1, frame2,...,frameN])。
在 data/dataset/kinetics/data
\_
k400目录下创建目录train
\_
pkl和val
\_
pkl
cd $Code_Root/data/dataset/kinetics/data_k400
mkdir train_pkl && mkdir val_pkl
进入$Code
\_
Root/data/dataset/kinetics目录,使用video2pkl.py脚本进行数据转化。首先需要下载
[
train
](
https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics/data/kinetics-400_train.csv
)
和
[
validation
](
https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics/data/kinetics-400_val.csv
)
数据集的文件列表。
首先生成预处理需要的数据集标签文件
python generate_label.py kinetics-400_train.csv kinetics400_label.txt
然后执行如下程序:
python video2pkl.py kinetics-400_train.csv $Source_dir $Target_dir 8 #以8个进程为例
-
该脚本依赖
`ffmpeg`
库,请预先安装
`ffmpeg`
对于train数据,
Source_dir = $Code_Root/data/dataset/kinetics/data_k400/train_mp4
Target_dir = $Code_Root/data/dataset/kinetics/data_k400/train_pkl
对于val数据,
Source_dir = $Code_Root/data/dataset/kinetics/data_k400/val_mp4
Target_dir = $Code_Root/data/dataset/kinetics/data_k400/val_pkl
这样即可将mp4文件解码并保存为pkl文件。
### 生成训练和验证集list
··
cd $Code_Root/data/dataset/kinetics
ls $Code_Root/data/dataset/kinetics/data_k400/train_pkl/* > train.list
ls $Code_Root/data/dataset/kinetics/data_k400/val_pkl/* > val.list
ls $Code_Root/data/dataset/kinetics/data_k400/val_pkl/* > test.list
ls $Code_Root/data/dataset/kinetics/data_k400/val_pkl/* > infer.list
即可生成相应的文件列表,train.list和val.list的每一行表示一个pkl文件的绝对路径,示例如下:
/ssd1/user/models/PaddleCV/PaddleVideo/data/dataset/kinetics/data_k400/train_pkl/data_batch_100-097
/ssd1/user/models/PaddleCV/PaddleVideo/data/dataset/kinetics/data_k400/train_pkl/data_batch_100-114
/ssd1/user/models/PaddleCV/PaddleVideo/data/dataset/kinetics/data_k400/train_pkl/data_batch_100-118
...
或者
/ssd1/user/models/PaddleCV/PaddleVideo/data/dataset/kinetics/data_k400/val_pkl/data_batch_102-085
/ssd1/user/models/PaddleCV/PaddleVideo/data/dataset/kinetics/data_k400/val_pkl/data_batch_102-086
/ssd1/user/models/PaddleCV/PaddleVideo/data/dataset/kinetics/data_k400/val_pkl/data_batch_102-090
...
tsm/dataset/kinetics/generate_label.py
0 → 100644
浏览文件 @
ed0360ea
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
sys
# kinetics-400_train.csv should be down loaded first and set as sys.argv[1]
# sys.argv[2] can be set as kinetics400_label.txt
# python generate_label.py kinetics-400_train.csv kinetics400_label.txt
num_classes
=
400
fname
=
sys
.
argv
[
1
]
outname
=
sys
.
argv
[
2
]
fl
=
open
(
fname
).
readlines
()
fl
=
fl
[
1
:]
outf
=
open
(
outname
,
'w'
)
label_list
=
[]
for
line
in
fl
:
label
=
line
.
strip
().
split
(
','
)[
0
].
strip
(
'"'
)
if
label
in
label_list
:
continue
else
:
label_list
.
append
(
label
)
assert
len
(
label_list
)
==
num_classes
,
"there should be {} labels in list, but "
.
format
(
num_classes
,
len
(
label_list
))
label_list
.
sort
()
for
i
in
range
(
num_classes
):
outf
.
write
(
'{} {}'
.
format
(
label_list
[
i
],
i
)
+
'
\n
'
)
outf
.
close
()
tsm/dataset/kinetics/video2pkl.py
0 → 100644
浏览文件 @
ed0360ea
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
#
#Licensed under the Apache License, Version 2.0 (the "License");
#you may not use this file except in compliance with the License.
#You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
#Unless required by applicable law or agreed to in writing, software
#distributed under the License is distributed on an "AS IS" BASIS,
#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
#See the License for the specific language governing permissions and
#limitations under the License.
import
os
import
sys
import
glob
try
:
import
cPickle
as
pickle
except
:
import
pickle
from
multiprocessing
import
Pool
# example command line: python generate_k400_pkl.py kinetics-400_train.csv 8
#
# kinetics-400_train.csv is the training set file of K400 official release
# each line contains laebl,youtube_id,time_start,time_end,split,is_cc
assert
(
len
(
sys
.
argv
)
==
5
)
f
=
open
(
sys
.
argv
[
1
])
source_dir
=
sys
.
argv
[
2
]
target_dir
=
sys
.
argv
[
3
]
num_threads
=
sys
.
argv
[
4
]
all_video_entries
=
[
x
.
strip
().
split
(
','
)
for
x
in
f
.
readlines
()]
all_video_entries
=
all_video_entries
[
1
:]
f
.
close
()
category_label_map
=
{}
f
=
open
(
'kinetics400_label.txt'
)
for
line
in
f
:
ens
=
line
.
strip
().
split
(
' '
)
category
=
" "
.
join
(
ens
[
0
:
-
1
])
label
=
int
(
ens
[
-
1
])
category_label_map
[
category
]
=
label
f
.
close
()
def
generate_pkl
(
entry
):
mode
=
entry
[
4
]
category
=
entry
[
0
].
strip
(
'"'
)
category_dir
=
category
video_path
=
os
.
path
.
join
(
'./'
,
entry
[
1
]
+
"_%06d"
%
int
(
entry
[
2
])
+
"_%06d"
%
int
(
entry
[
3
])
+
".mp4"
)
video_path
=
os
.
path
.
join
(
source_dir
,
category_dir
,
video_path
)
label
=
category_label_map
[
category
]
vid
=
'./'
+
video_path
.
split
(
'/'
)[
-
1
].
split
(
'.'
)[
0
]
if
os
.
path
.
exists
(
video_path
):
if
not
os
.
path
.
exists
(
vid
):
os
.
makedirs
(
vid
)
os
.
system
(
'ffmpeg -i '
+
video_path
+
' -q 0 '
+
vid
+
'/%06d.jpg'
)
else
:
print
(
"File not exists {}"
.
format
(
video_path
))
return
images
=
sorted
(
glob
.
glob
(
vid
+
'/*.jpg'
))
ims
=
[]
for
img
in
images
:
f
=
open
(
img
,
'rb'
)
ims
.
append
(
f
.
read
())
f
.
close
()
output_pkl
=
vid
+
".pkl"
output_pkl
=
os
.
path
.
join
(
target_dir
,
output_pkl
)
f
=
open
(
output_pkl
,
'wb'
)
pickle
.
dump
((
vid
,
label
,
ims
),
f
,
protocol
=
2
)
f
.
close
()
os
.
system
(
'rm -rf %s'
%
vid
)
pool
=
Pool
(
processes
=
int
(
sys
.
argv
[
4
]))
pool
.
map
(
generate_pkl
,
all_video_entries
)
pool
.
close
()
pool
.
join
()
tsm/images/temporal_shift.png
0 → 100644
浏览文件 @
ed0360ea
166.4 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}