“94736d6072a3fd5551b696d559a77603cafbad08”上不存在“python/paddle/distributed/run/context/event.py”
Merge branch 'master' of https://github.com/PaddlePaddle/hapi into add-hapi-seq2seq
Showing
bmn/BMN.png
0 → 100644
{kind=link}
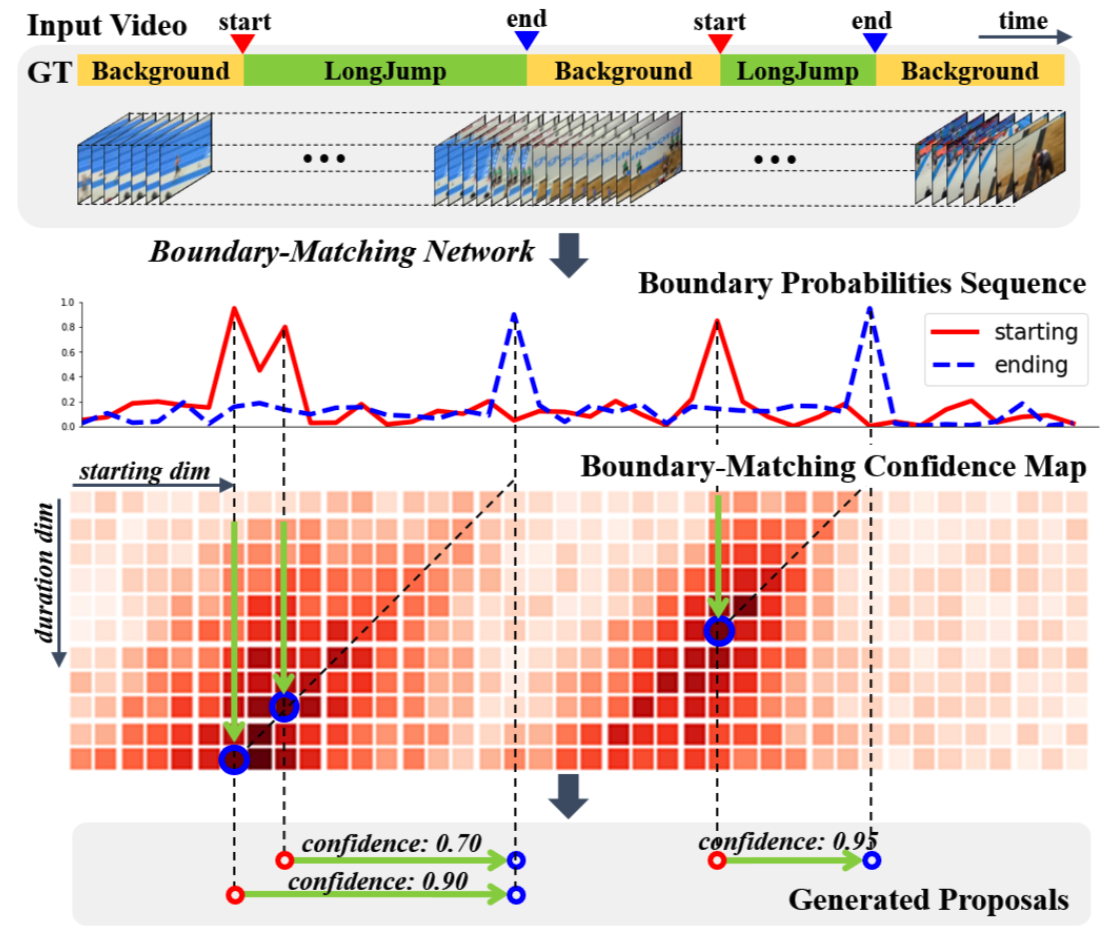
520.3 KB
bmn/README.md
0 → 100644
bmn/bmn.yaml
0 → 100644
bmn/bmn_metric.py
0 → 100644
bmn/bmn_model.py
0 → 100644
bmn/bmn_utils.py
0 → 100644
bmn/config_utils.py
0 → 100644
bmn/eval.py
0 → 100644
bmn/eval_anet_prop.py
0 → 100644
bmn/infer.list
0 → 100644
bmn/predict.py
0 → 100644
bmn/reader.py
0 → 100644
bmn/run.sh
0 → 100644
bmn/train.py
0 → 100644
cyclegan/README.md
0 → 100644
cyclegan/__init__.py
0 → 100644
cyclegan/check.py
0 → 100644
cyclegan/cyclegan.py
0 → 100644
cyclegan/data.py
0 → 100644
cyclegan/image/A2B.png
0 → 100644
{kind=link}

154.5 KB
cyclegan/image/B2A.png
0 → 100644
{kind=link}

143.2 KB
cyclegan/image/net.png
0 → 100644
{kind=link}

152.5 KB
cyclegan/image/testA/123_A.jpg
0 → 100644
{kind=link}

33.4 KB
cyclegan/image/testB/78_B.jpg
0 → 100644
{kind=link}

24.8 KB
cyclegan/infer.py
0 → 100644
cyclegan/layers.py
0 → 100644
cyclegan/test.py
0 → 100644
cyclegan/train.py
0 → 100644
datasets/folder.py
0 → 100644
image_classification/README.MD
0 → 100644
image_classification/main.py
0 → 100644
lac.py
0 → 100644
models/__init__.py
0 → 100644
models/darknet.py
0 → 100755
models/download.py
0 → 100644
models/mobilenetv1.py
0 → 100644
models/mobilenetv2.py
0 → 100644
models/resnet.py
0 → 100644
models/tsm.py
0 → 100644
models/vgg.py
0 → 100644
models/yolov3.py
0 → 100644
text.py
0 → 100644
transformer/README.md
0 → 100644
transformer/gen_data.sh
0 → 100644
{kind=link}

104.5 KB
{kind=link}
259.1 KB
transformer/predict.py
0 → 100644
transformer/reader.py
0 → 100644
transformer/train.py
0 → 100644
transformer/transformer.py
0 → 100644
transformer/transformer.yaml
0 → 100644
transformer/utils/__init__.py
0 → 100644
transformer/utils/check.py
0 → 100644
transformer/utils/configure.py
0 → 100644
tsm/README.md
0 → 100644
tsm/check.py
0 → 100644
tsm/dataset/README.md
0 → 100644
tsm/dataset/kinetics/video2pkl.py
0 → 100644
tsm/images/temporal_shift.png
0 → 100644
{kind=link}
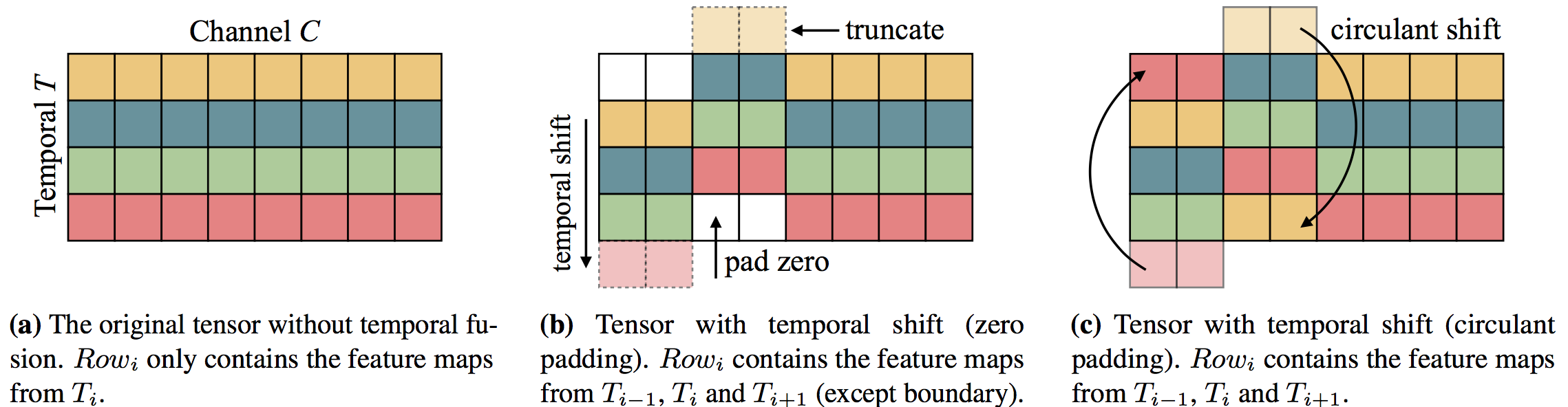
166.4 KB
tsm/infer.py
0 → 100644
tsm/kinetics_dataset.py
0 → 100644
tsm/main.py
0 → 100644
tsm/transforms.py
0 → 100644
yolov3.py
已删除
100644 → 0
yolov3/README.md
0 → 100644
yolov3/coco.py
0 → 100644
yolov3/dataset/download_voc.py
0 → 100644
yolov3/image/YOLOv3.jpg
0 → 100644
{kind=link}
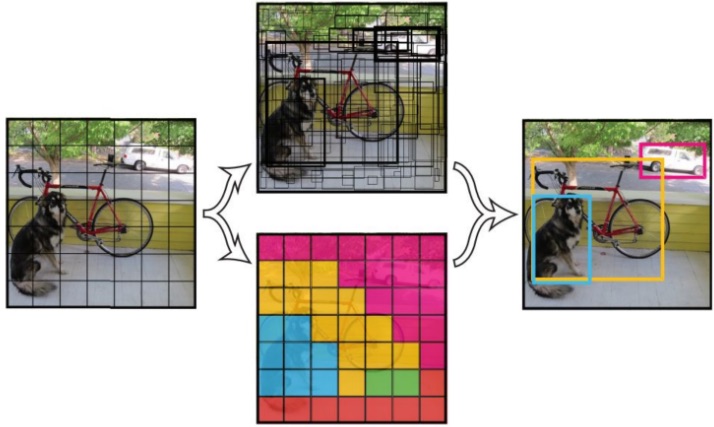
68.4 KB
yolov3/image/YOLOv3_structure.jpg
0 → 100644
{kind=link}
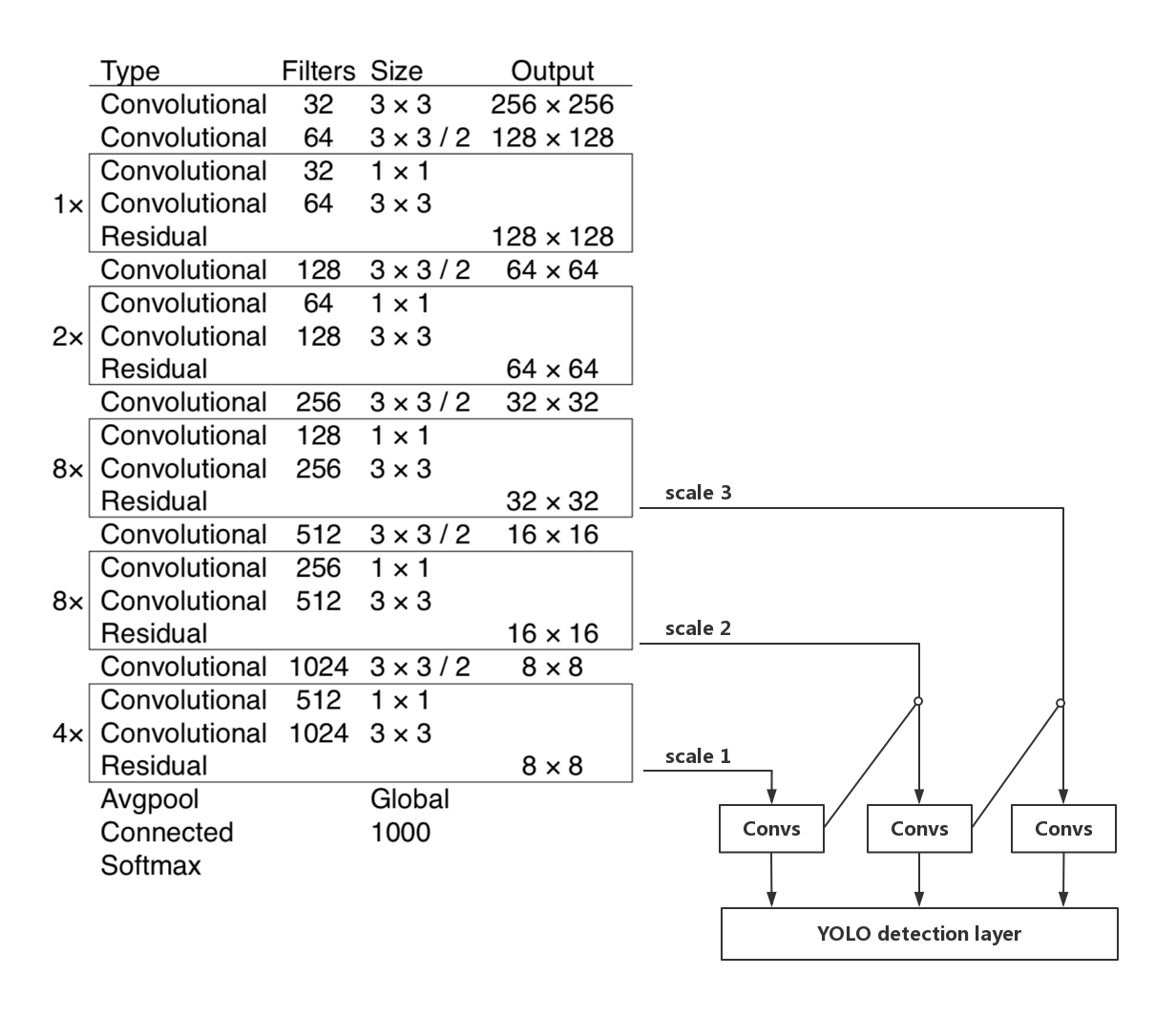
288.4 KB
yolov3/image/dog.jpg
0 → 100644
{kind=link}

159.9 KB
yolov3/infer.py
0 → 100644
yolov3/main.py
0 → 100644
yolov3/transforms.py
0 → 100644
yolov3/visualizer.py
0 → 100644