Merge pull request #23 from heavengate/yolov3
add YOLOv3
Showing
models/darknet.py
0 → 100755
models/yolov3.py
0 → 100644
yolov3.py
已删除
100644 → 0
此差异已折叠。
yolov3/README.md
0 → 100644
yolov3/coco.py
0 → 100644
yolov3/image/YOLOv3.jpg
0 → 100644
{kind=link}
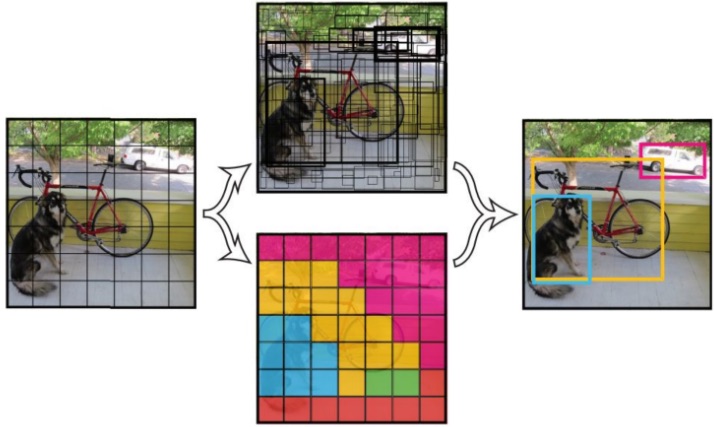
68.4 KB
yolov3/image/YOLOv3_structure.jpg
0 → 100644
{kind=link}
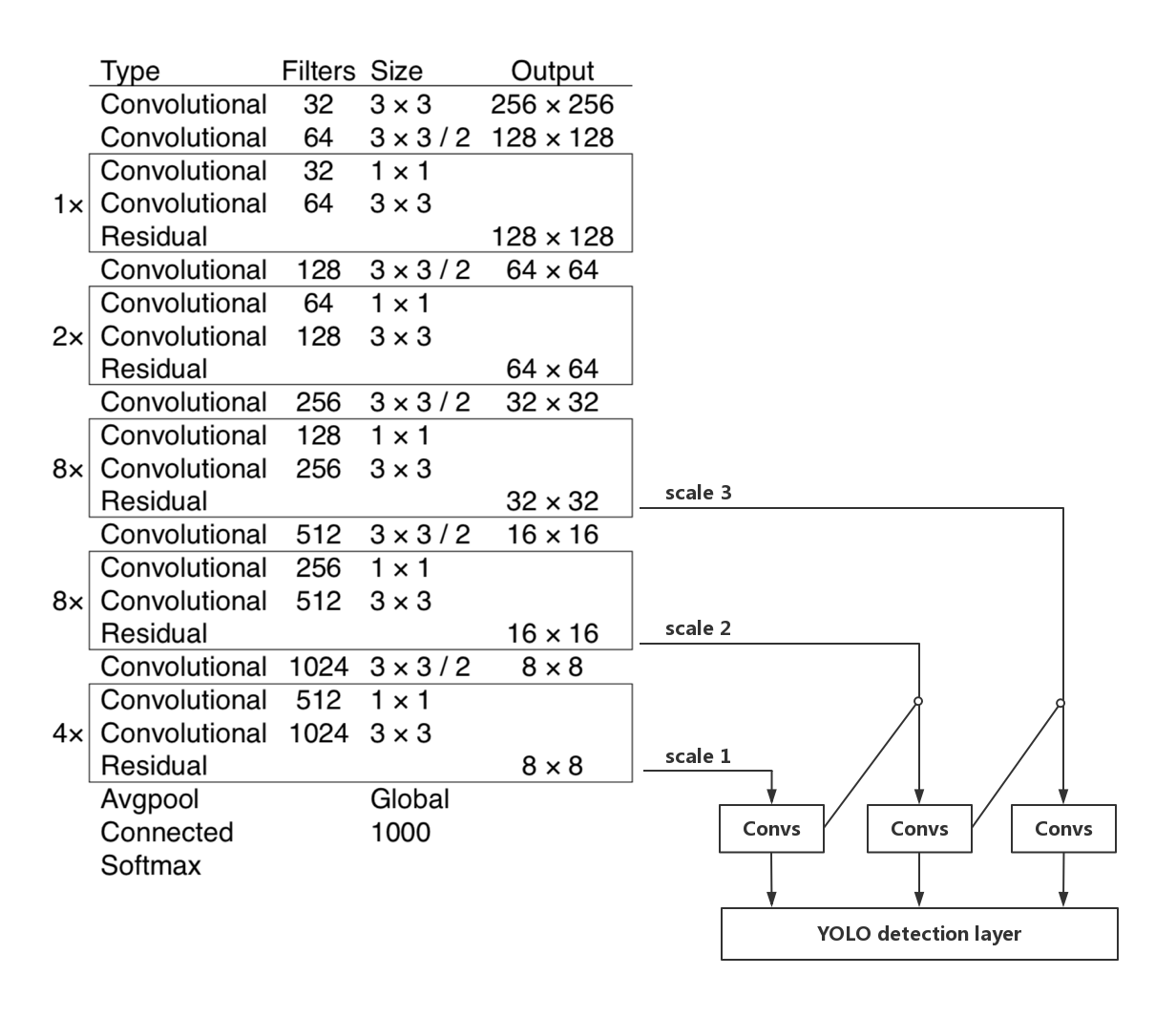
288.4 KB
yolov3/image/dog.jpg
0 → 100644
{kind=link}

159.9 KB
yolov3/infer.py
0 → 100644
yolov3/main.py
0 → 100644
yolov3/transforms.py
0 → 100644
此差异已折叠。
yolov3/visualizer.py
0 → 100644