Merge branch 'master' of https://github.com/PaddlePaddle/hapi into cyclegan
Showing
bmn/BMN.png
0 → 100644
{kind=link}
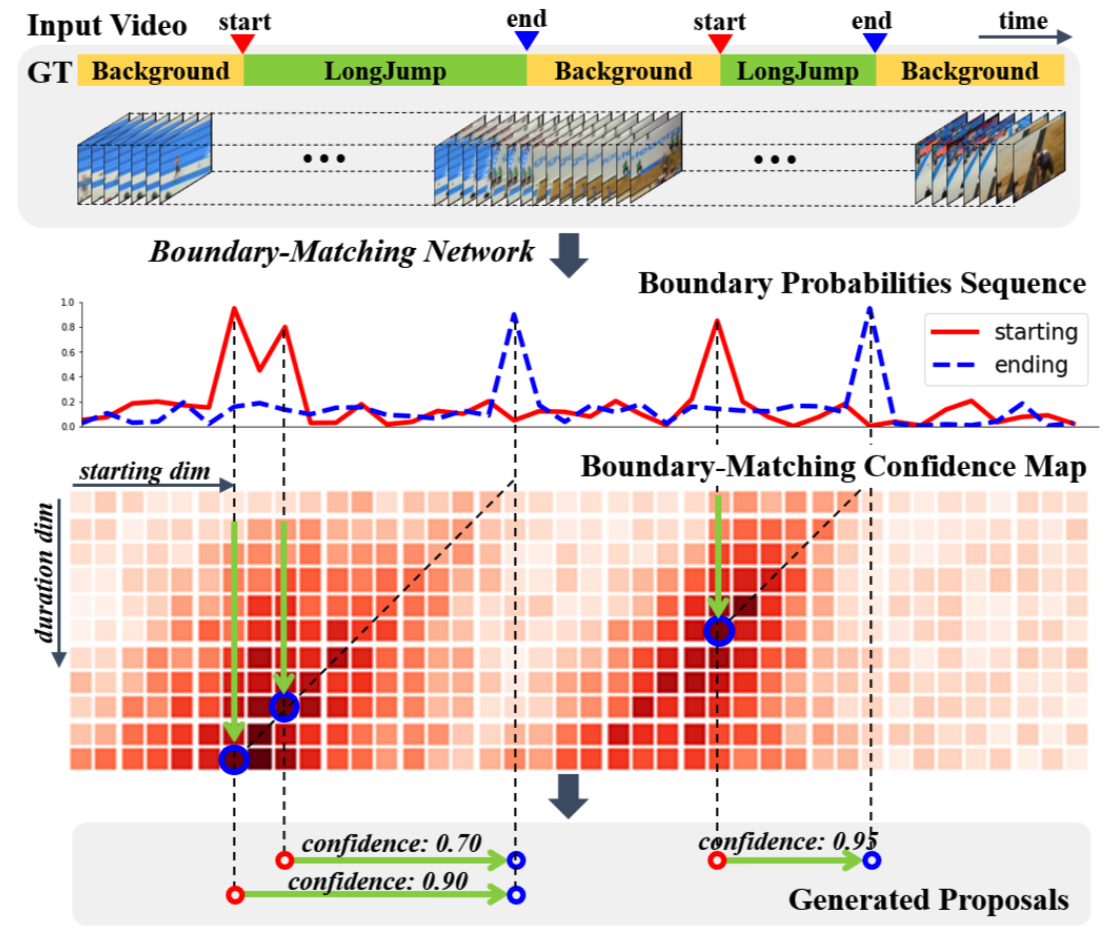
520.3 KB
bmn/README.md
0 → 100644
bmn/bmn.yaml
0 → 100644
bmn/bmn_metric.py
0 → 100644
bmn/bmn_model.py
0 → 100644
bmn/bmn_utils.py
0 → 100644
bmn/config_utils.py
0 → 100644
bmn/eval.py
0 → 100644
bmn/eval_anet_prop.py
0 → 100644
bmn/infer.list
0 → 100644
bmn/predict.py
0 → 100644
bmn/reader.py
0 → 100644
bmn/run.sh
0 → 100644
bmn/train.py
0 → 100644
datasets/folder.py
0 → 100644
image_classification/README.MD
0 → 100644
image_classification/main.py
0 → 100644
models/__init__.py
0 → 100644
models/download.py
0 → 100644
models/resnet.py
0 → 100644
text.py
0 → 100644
此差异已折叠。
transformer/README.md
0 → 100644
{kind=link}
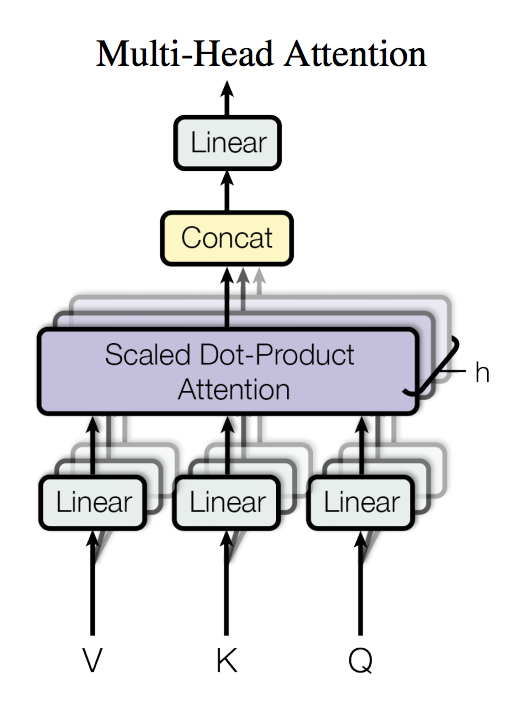
104.5 KB
{kind=link}
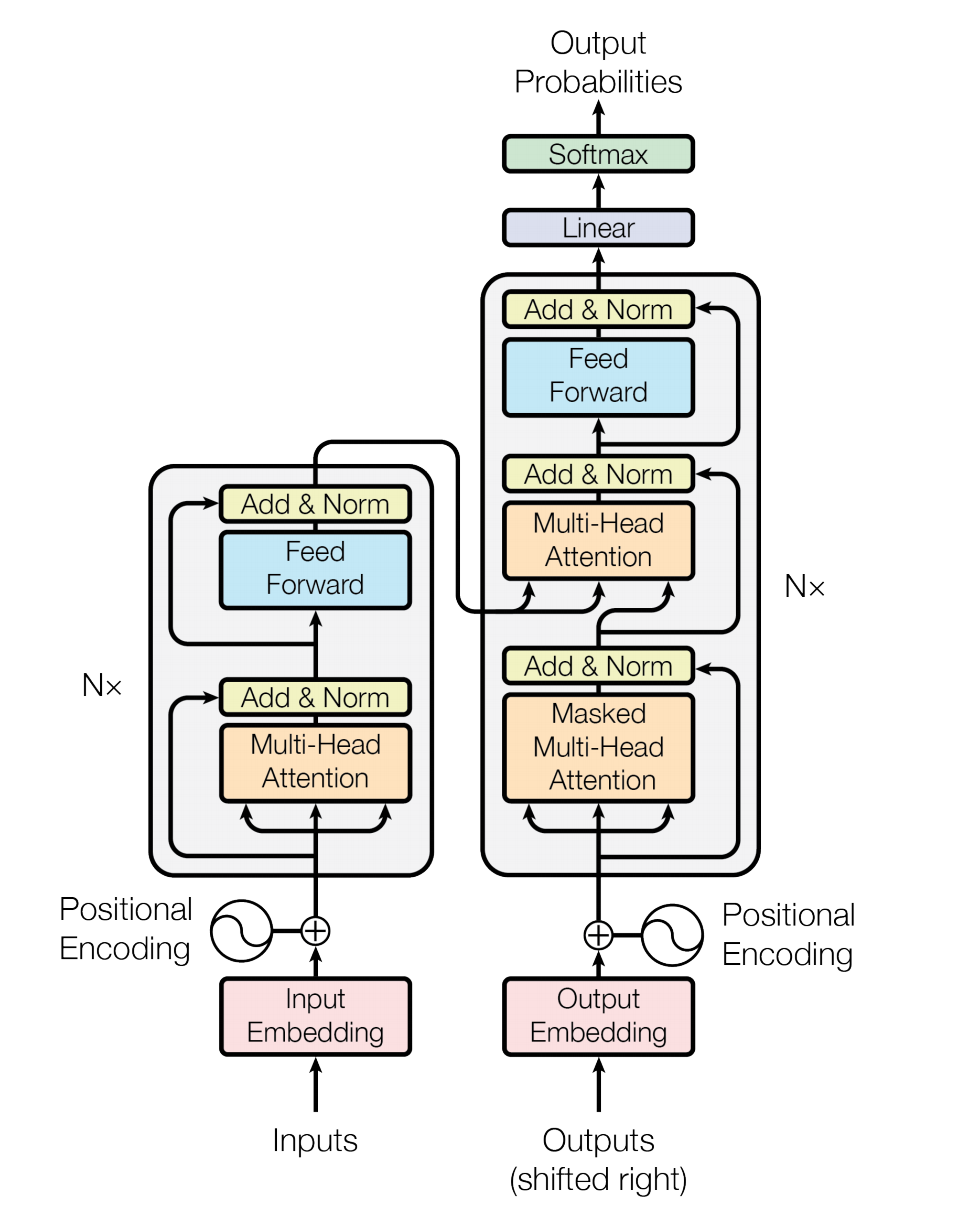
259.1 KB
transformer/predict.py
0 → 100644
transformer/reader.py
0 → 100644
transformer/run.sh
0 → 100644
transformer/train.py
0 → 100644
transformer/transformer.py
0 → 100644
此差异已折叠。
transformer/transformer.yaml
0 → 100644
transformer/utils/__init__.py
0 → 100644
transformer/utils/check.py
0 → 100644
transformer/utils/configure.py
0 → 100644
此差异已折叠。