Transformer with hapi
Showing
transformer/README.md
0 → 100644
{kind=link}
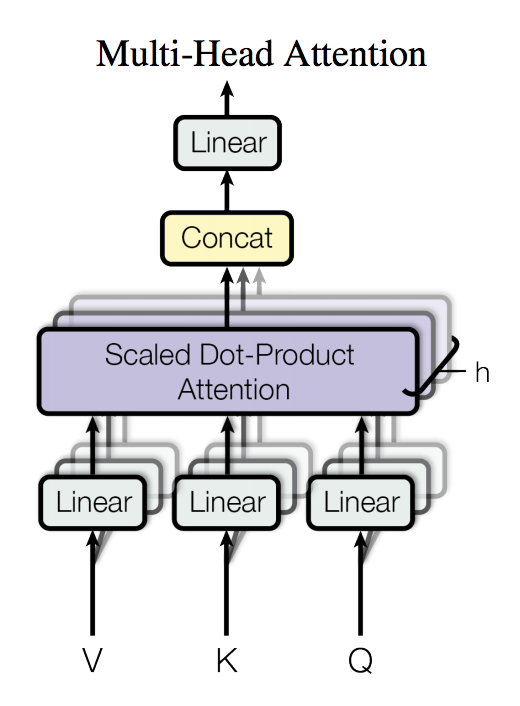
104.5 KB
{kind=link}
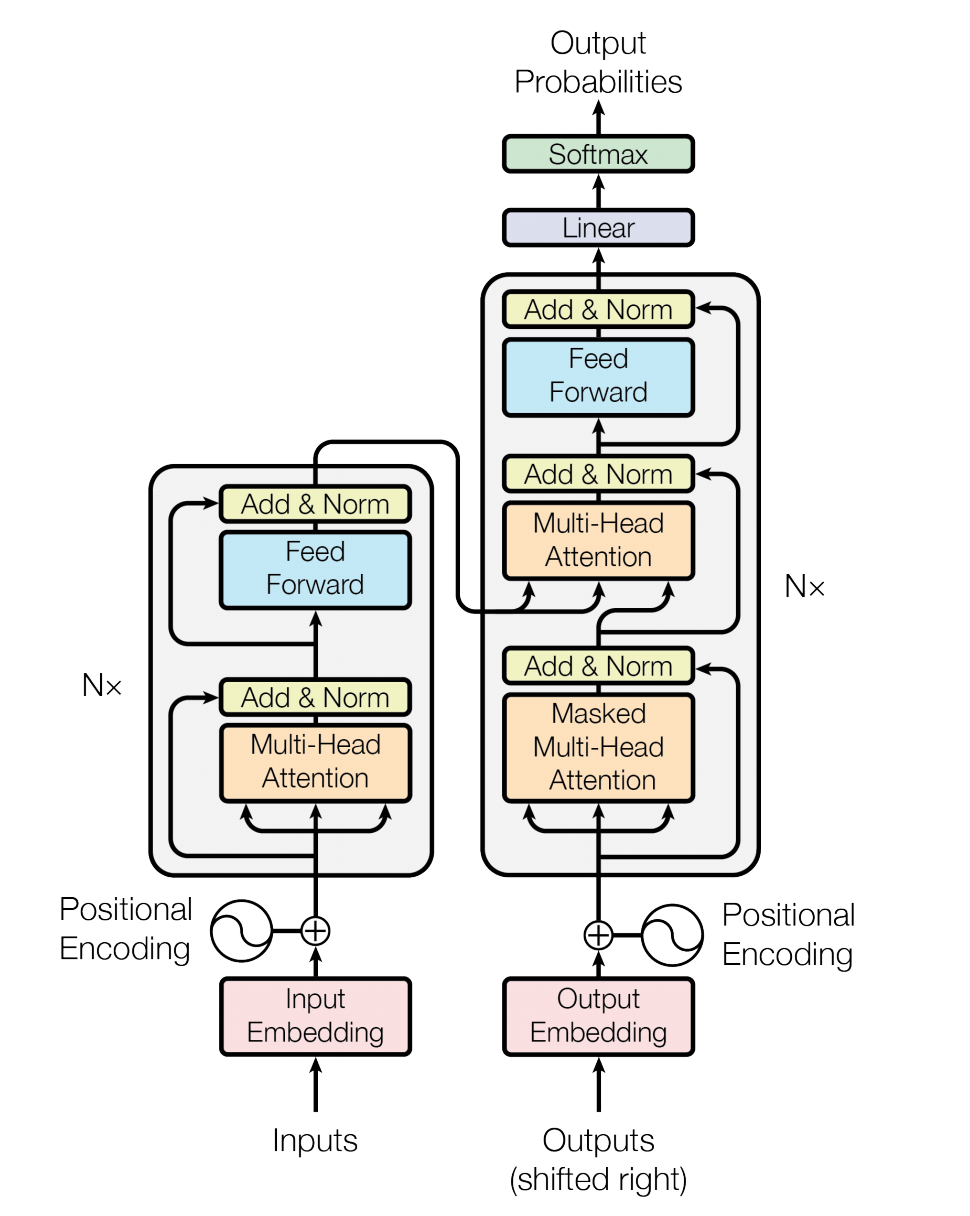
259.1 KB
transformer/predict.py
0 → 100644
transformer/reader.py
0 → 100644
此差异已折叠。
transformer/train.py
0 → 100644
transformer/transformer.py
0 → 100644
此差异已折叠。
transformer/transformer.yaml
0 → 100644
transformer/utils/__init__.py
0 → 100644
transformer/utils/check.py
0 → 100644
transformer/utils/configure.py
0 → 100644