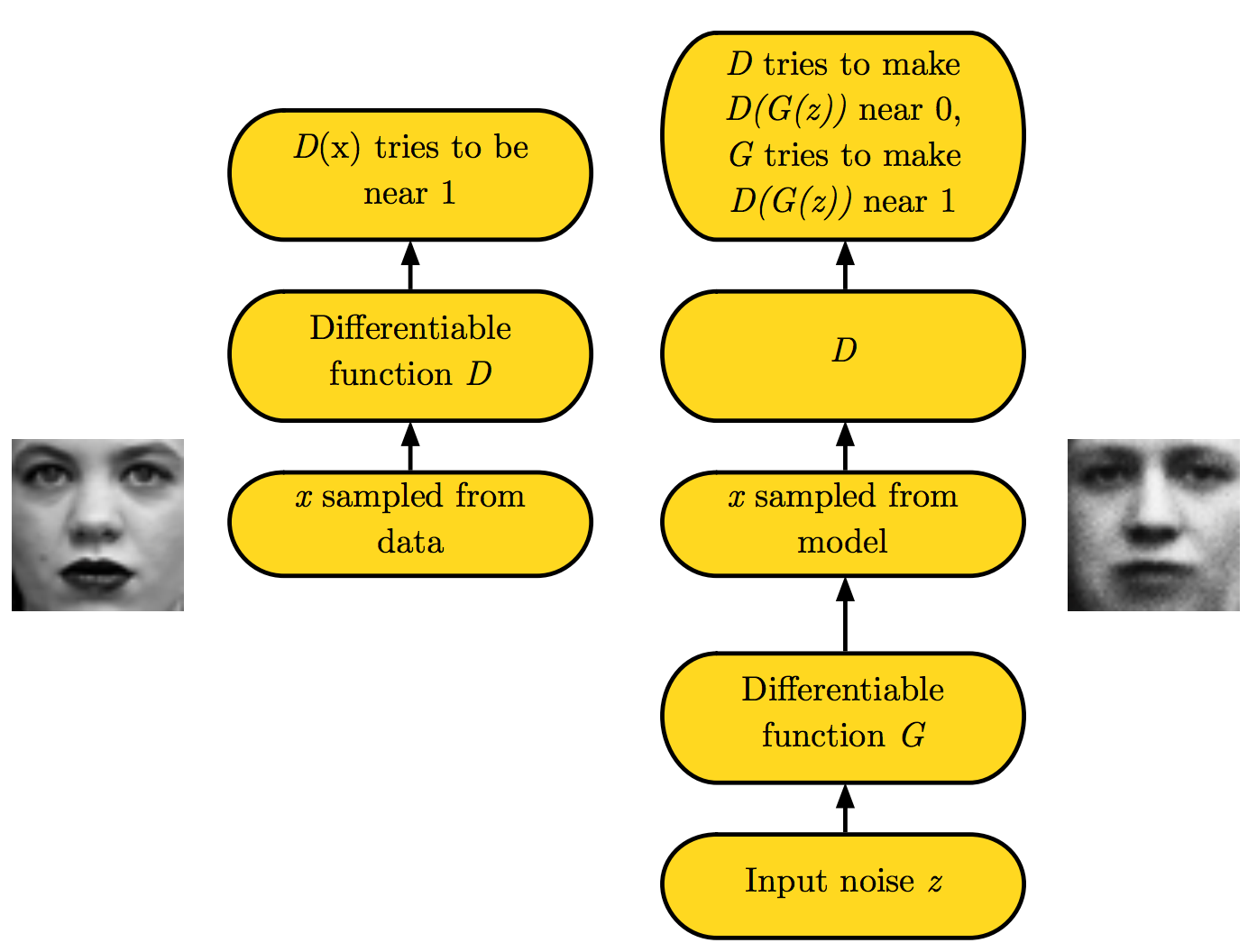
由于上面的这种网络都是由全联接层组成,所以没有办法很好的生成图片数据,也没有办法做的很深。所以在随后的论文中,人们提出了深度卷积对抗式生成网络(deep convolutional generative adversarial network or DCGAN)\[[2](#参考文献)\]。在DCGAN中,生成器 G 是由多个卷积转置层(transposed convolution)组成的,这样可以用更少的参数来生成质量更高的图片。具体网络结果可参见图4。而判别器是由多个卷积层组成。
由于上面的这种网络都是由全联接层组成,所以没有办法很好的生成图片数据,也没有办法做的很深。所以在随后的论文中,人们提出了深度卷积对抗式生成网络(deep convolutional generative adversarial network or DCGAN)\[[2](#参考文献)\]。在DCGAN中,生成器 G 是由多个卷积转置层(transposed convolution)组成的,这样可以用更少的参数来生成质量更高的图片。具体网络结果可参见图4。而判别器是由多个卷积层组成。
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}