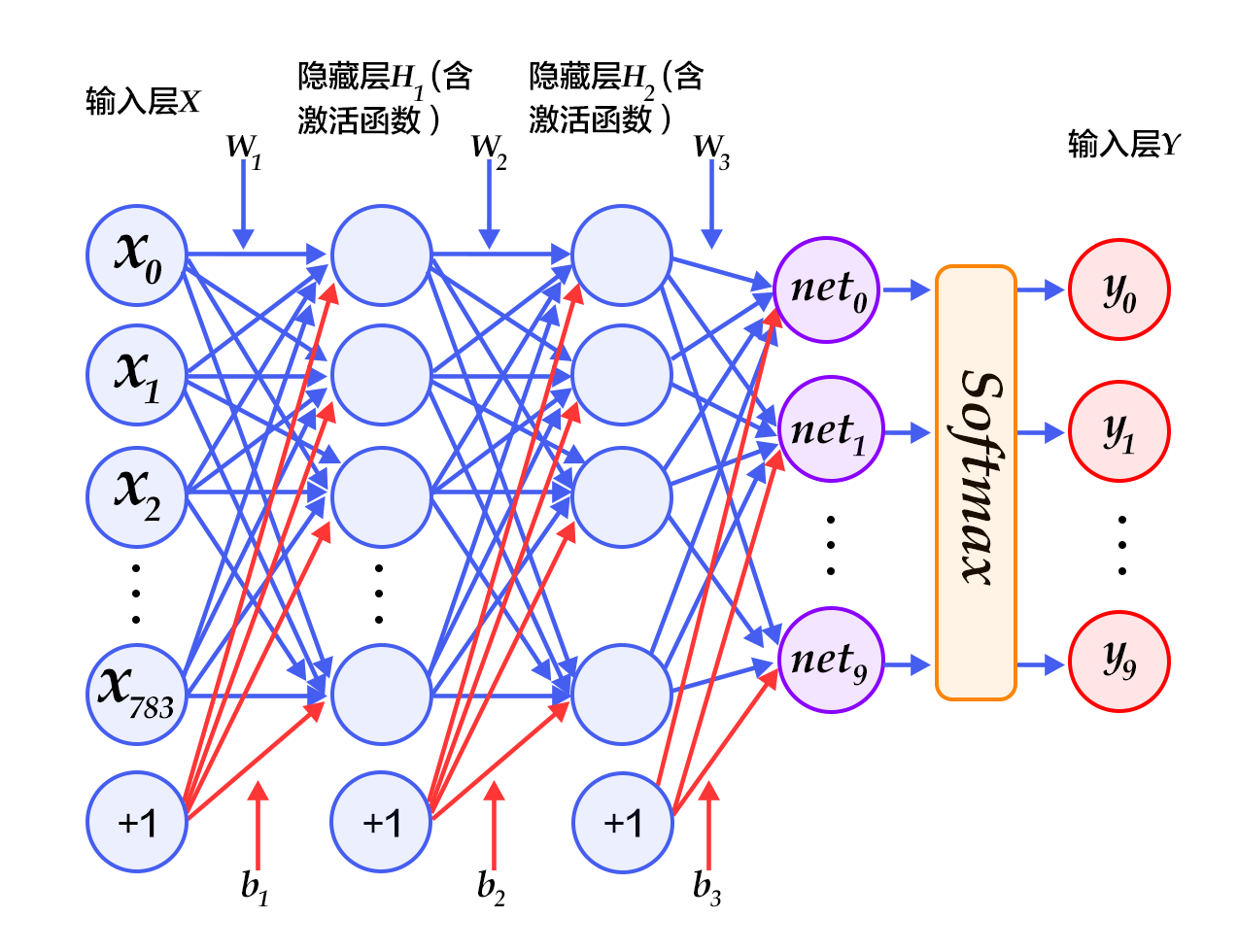
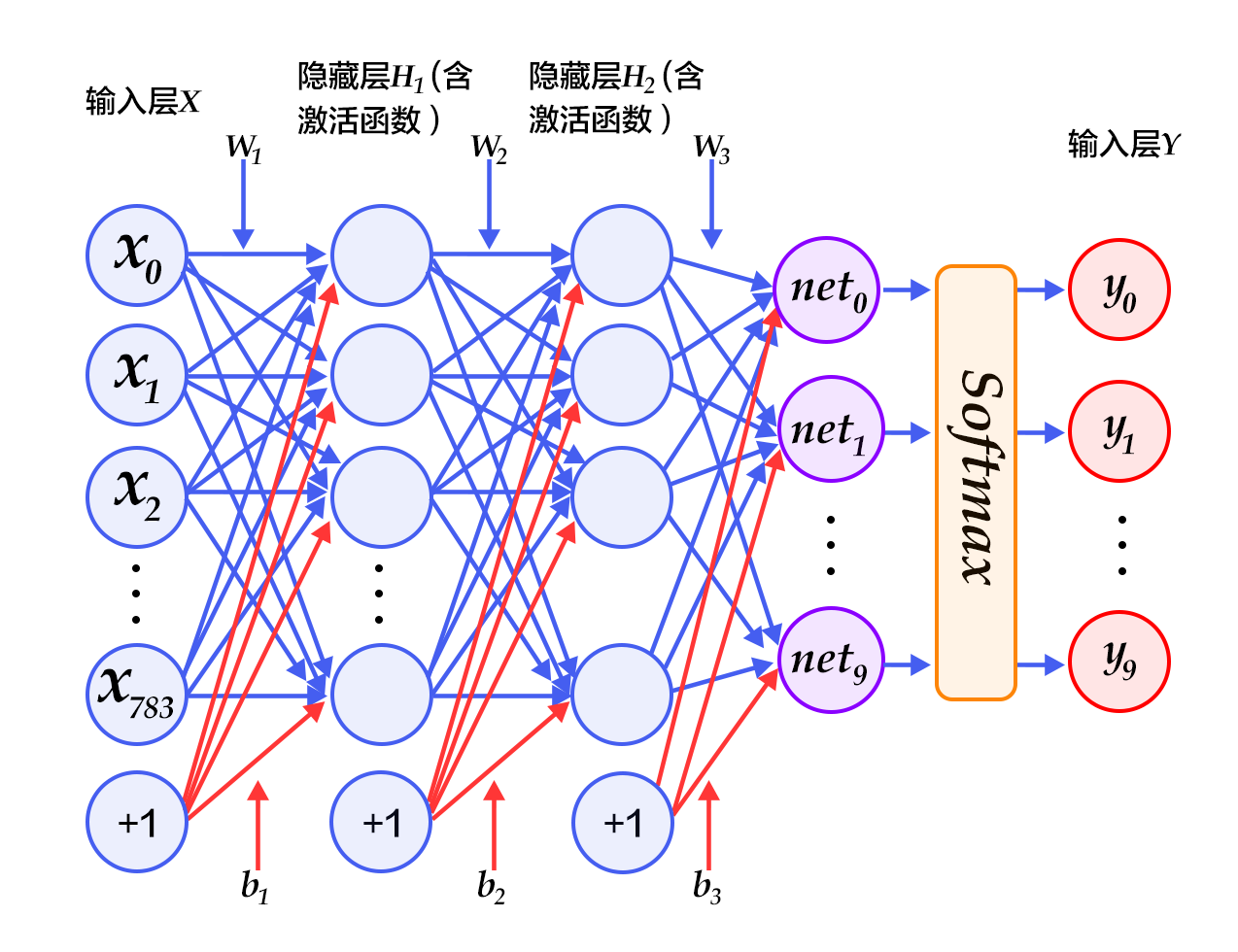
我们使用从[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)获得的波士顿房价数据集进行模型的训练和预测。下面的散点图展示了使用模型对部分房屋价格进行的预测。其中,每个点的横坐标表示同一类房屋真实价格的中位数,纵坐标表示线性回归模型根据特征预测的结果,当二者值完全相等的时候就会落在虚线上。所以模型预测得越准确,则点离虚线越近。
<palign="center">
<imgsrc = "image/predictions.png"><br/>
<imgsrc = "image/predictions.png"width=400><br/>
图1. 预测值 V.S. 真实值
</p>
...
...
@@ -83,7 +83,7 @@ cd data && python prepare_data.py
- 很多的机器学习技巧/模型(例如L1,L2正则项,向量空间模型-Vector Space Model)都基于这样的假设:所有的属性取值都差不多是以0为均值且取值范围相近的。
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的\[[4](#参考文献)\]。自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory\[[5](#参考文献)\]等)在自然语言处理的多个领域,如语言模型、句法解析、语义角色标注(或一般的序列标注)、语义表示、图文生成、对话、机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
{kind=link}
{kind=link}