auto format and fix conflict
Showing
fit_a_line/train.py
0 → 100644
此差异已折叠。
{kind=link}
105.2 KB
{kind=link}

222.6 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}

31.0 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
50.9 KB
{kind=link}
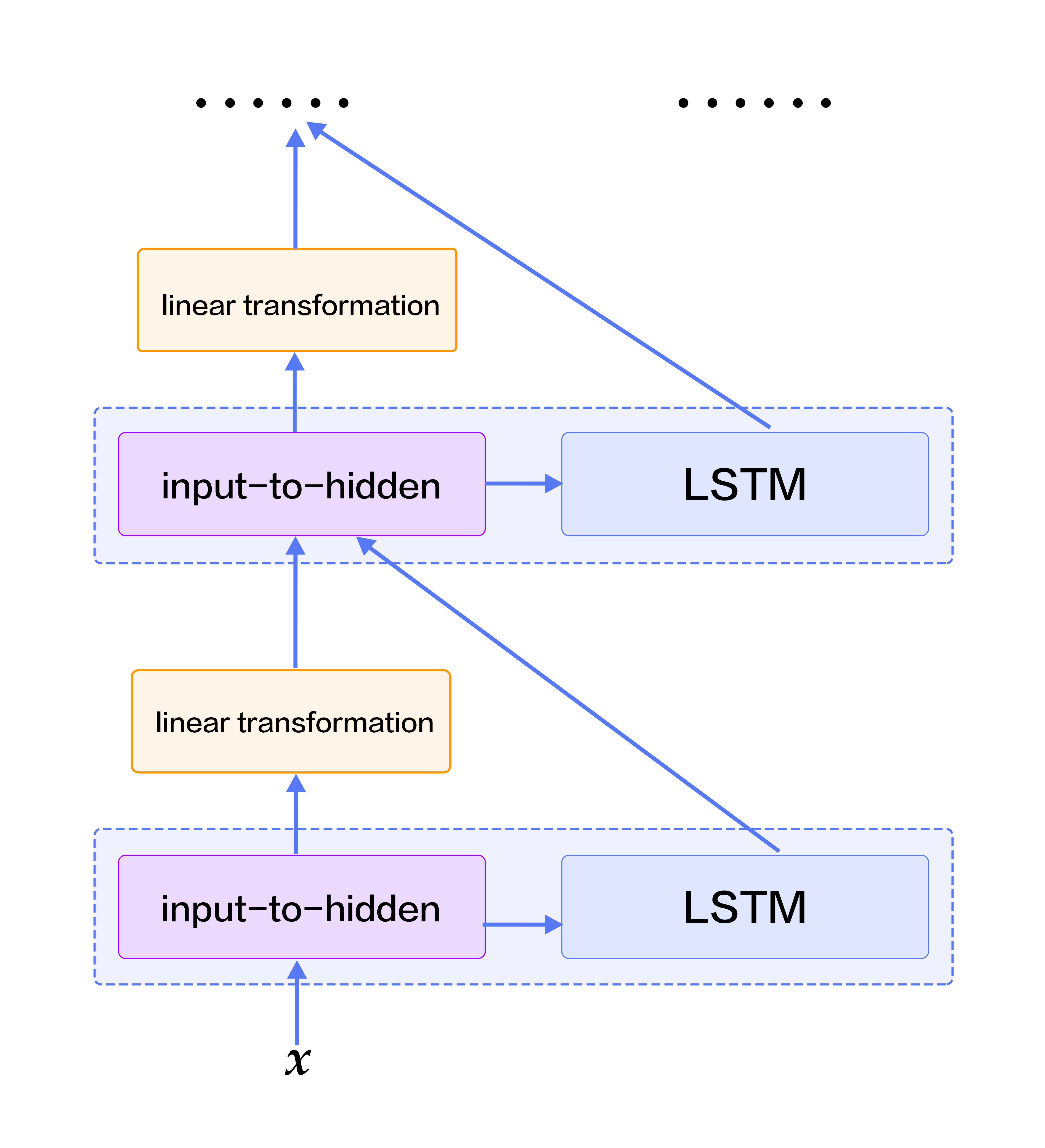
237.9 KB
machine_translation/api_train.py
0 → 100644
{kind=link}
{kind=link}
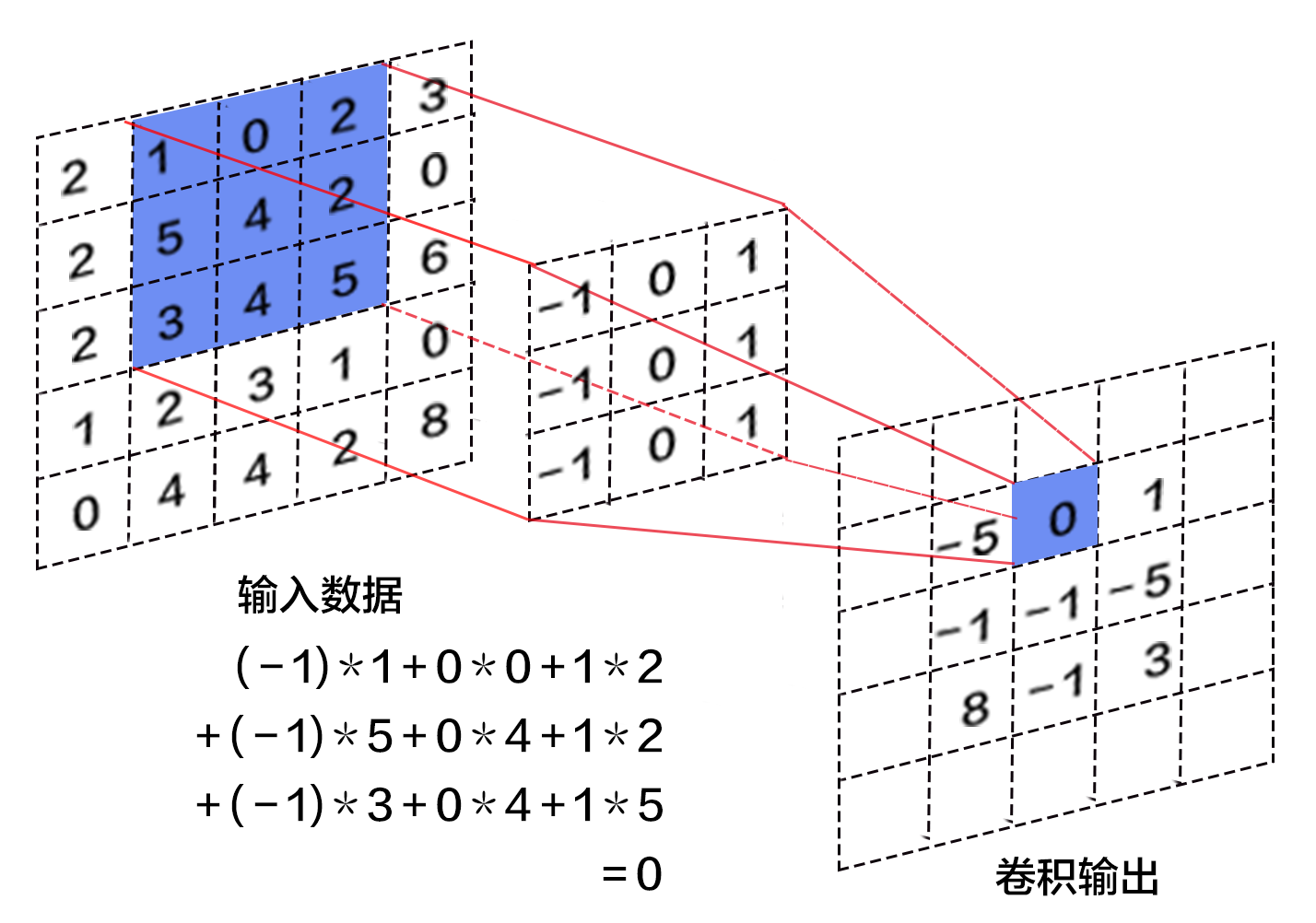
| W: | H:

| W: | H:
recognize_digits/train.py
0 → 100644
此差异已折叠。
recommender_system/.gitignore
0 → 100644
recommender_system/README.ipynb
0 → 100644
此差异已折叠。
{kind=link}
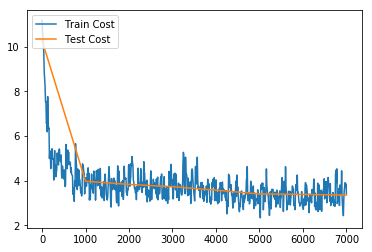
21.1 KB
{kind=link}
{kind=link}
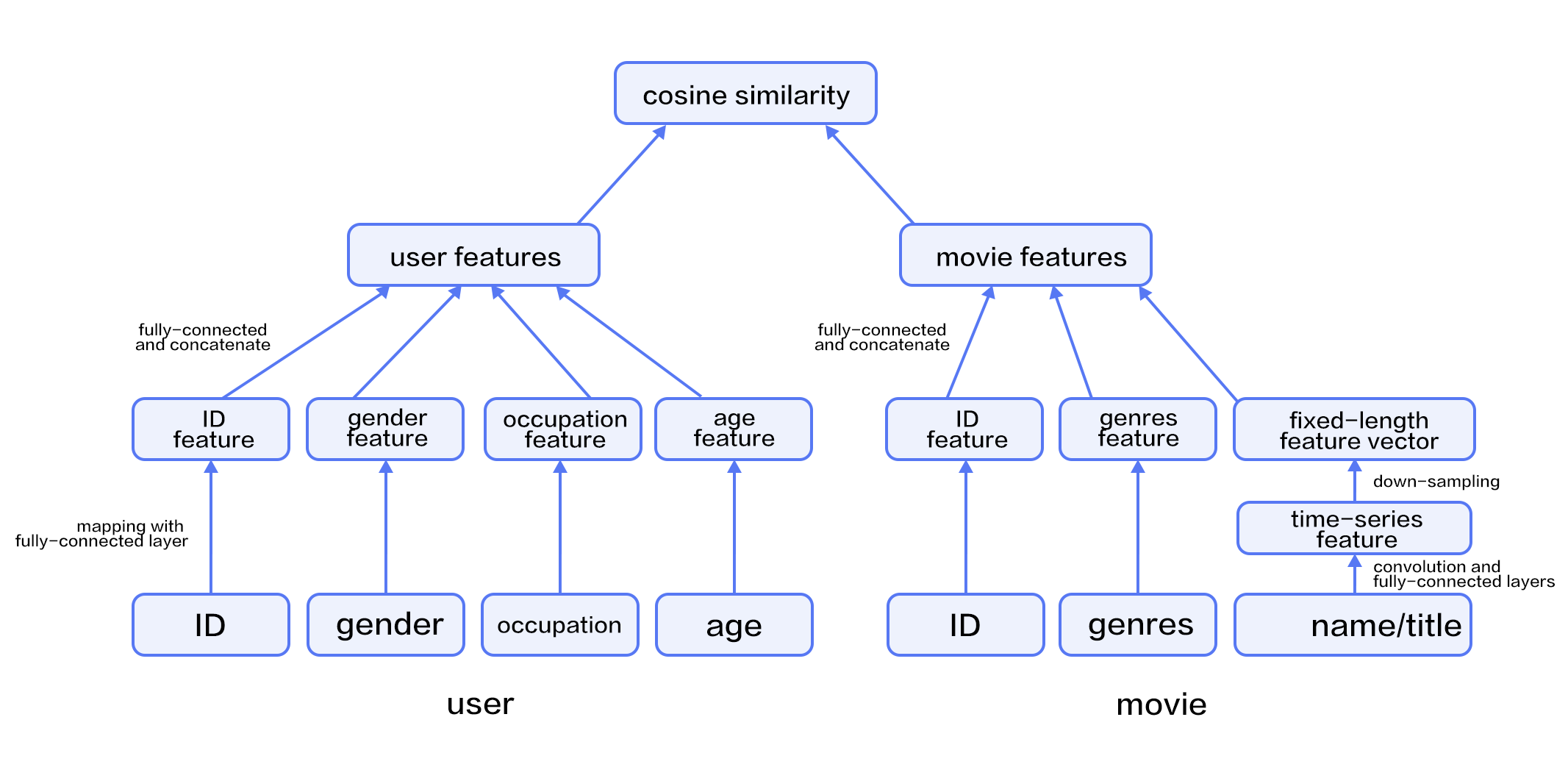
| W: | H:
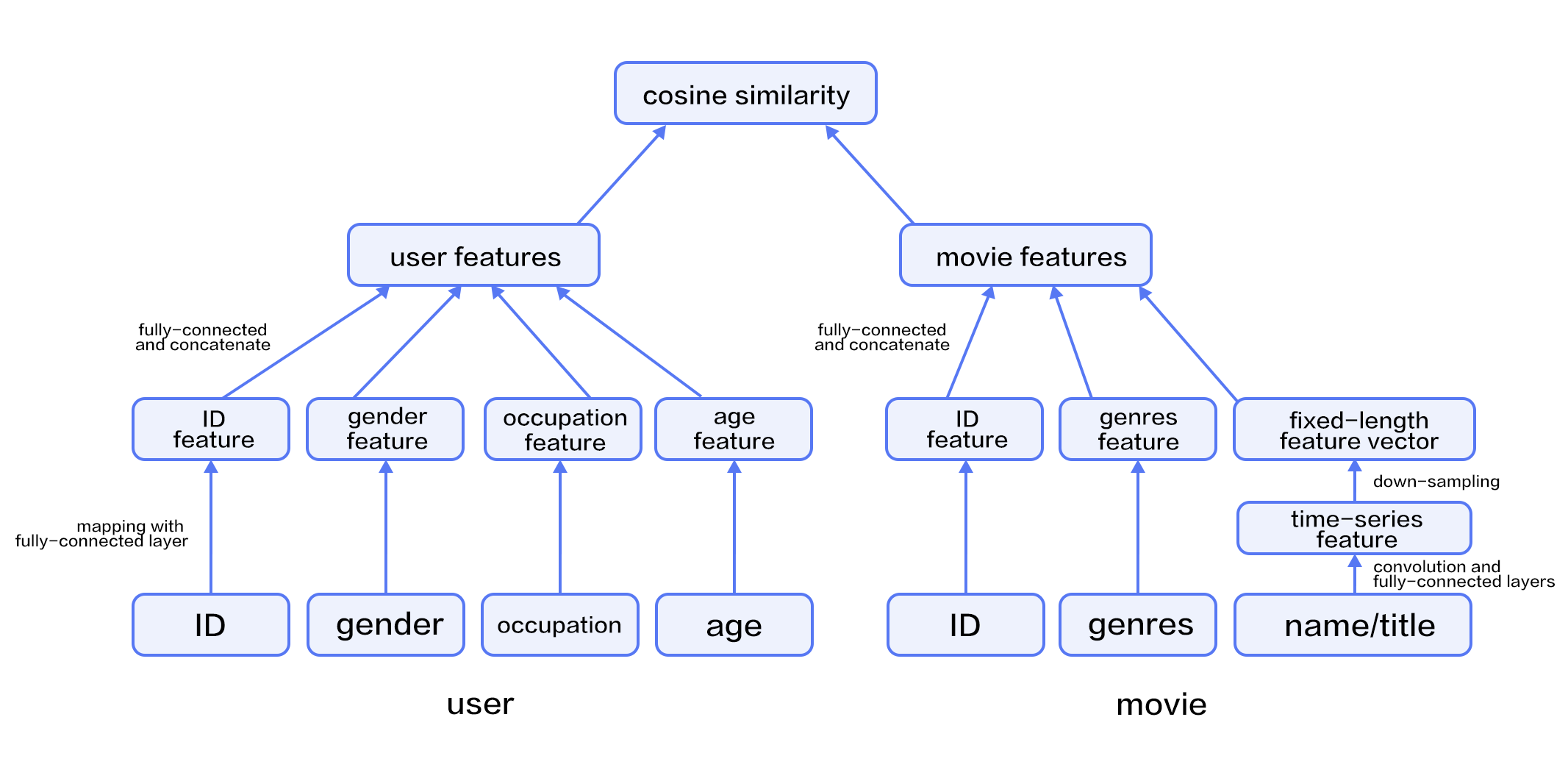
| W: | H:
{kind=link}
{kind=link}
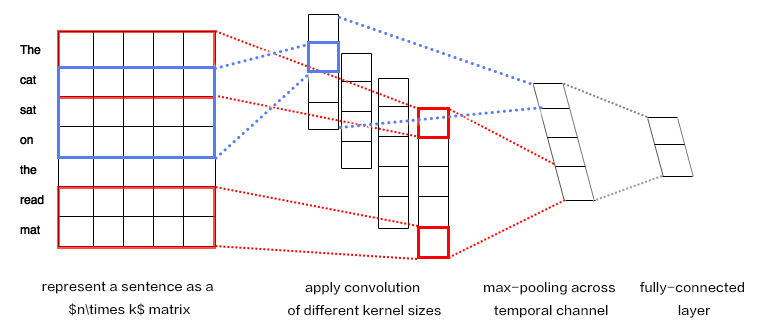
| W: | H:

| W: | H:
understand_sentiment/train.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。