update
Showing
.tmpl/github-markdown.css
0 → 100644
.tmpl/marked.js
0 → 100644
此差异已折叠。
build.sh
0 → 100755
fit_a_line/README.en.md
0 → 100644
{kind=link}
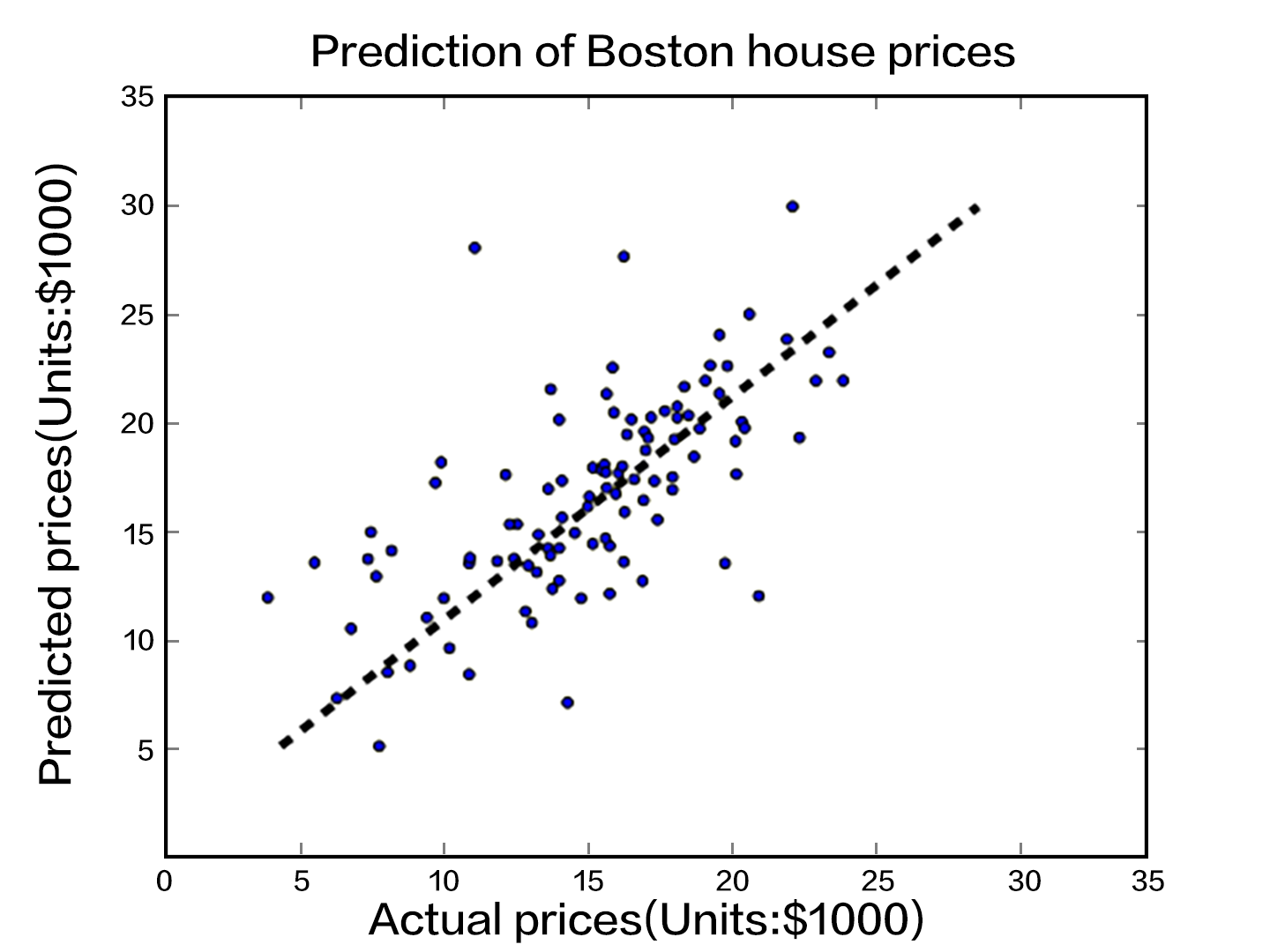
136.8 KB
fit_a_line/image/ranges_en.png
0 → 100644
{kind=link}
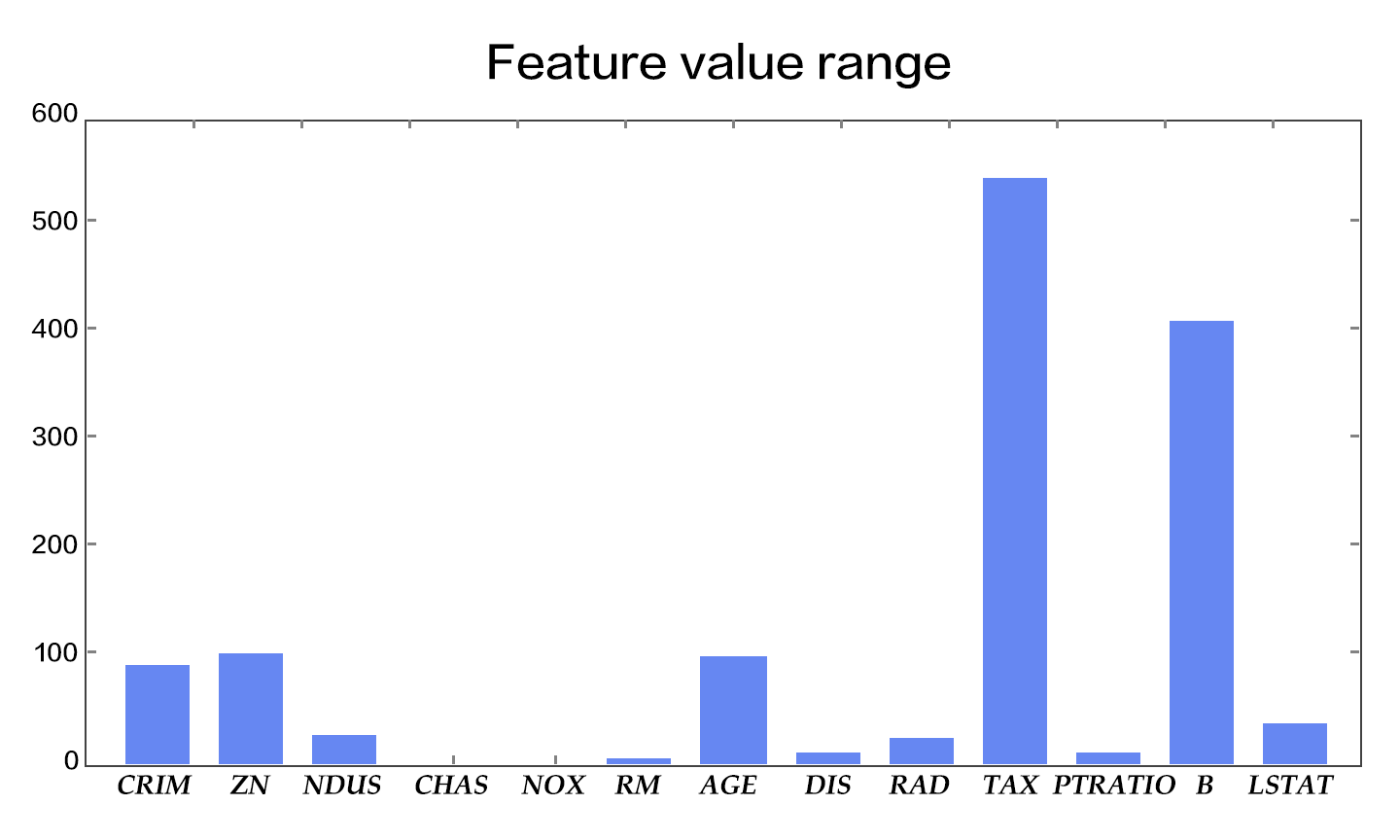
29.6 KB
fit_a_line/index.en.html
0 → 100644
fit_a_line/index.html
0 → 100644
gan/index.html
0 → 100644
image_caption/index.html
0 → 100644
image_classification/README.en.md
0 → 100644
此差异已折叠。
{kind=link}
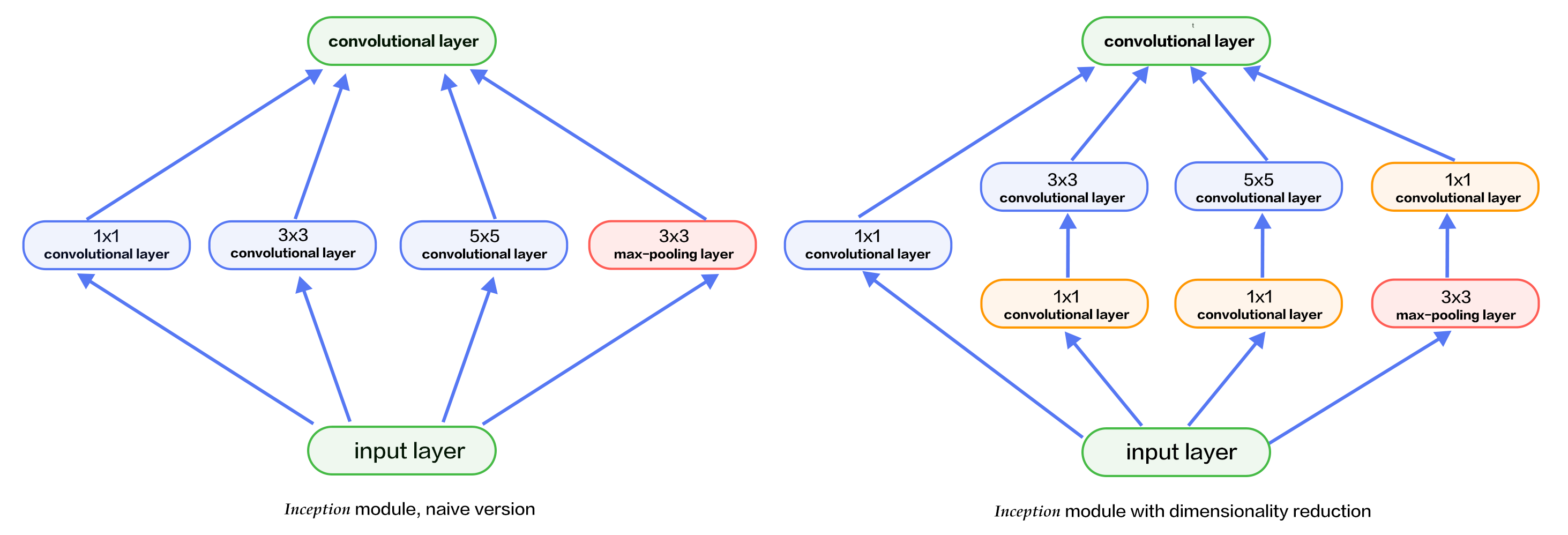
226.4 KB
{kind=link}
135.9 KB
{kind=link}
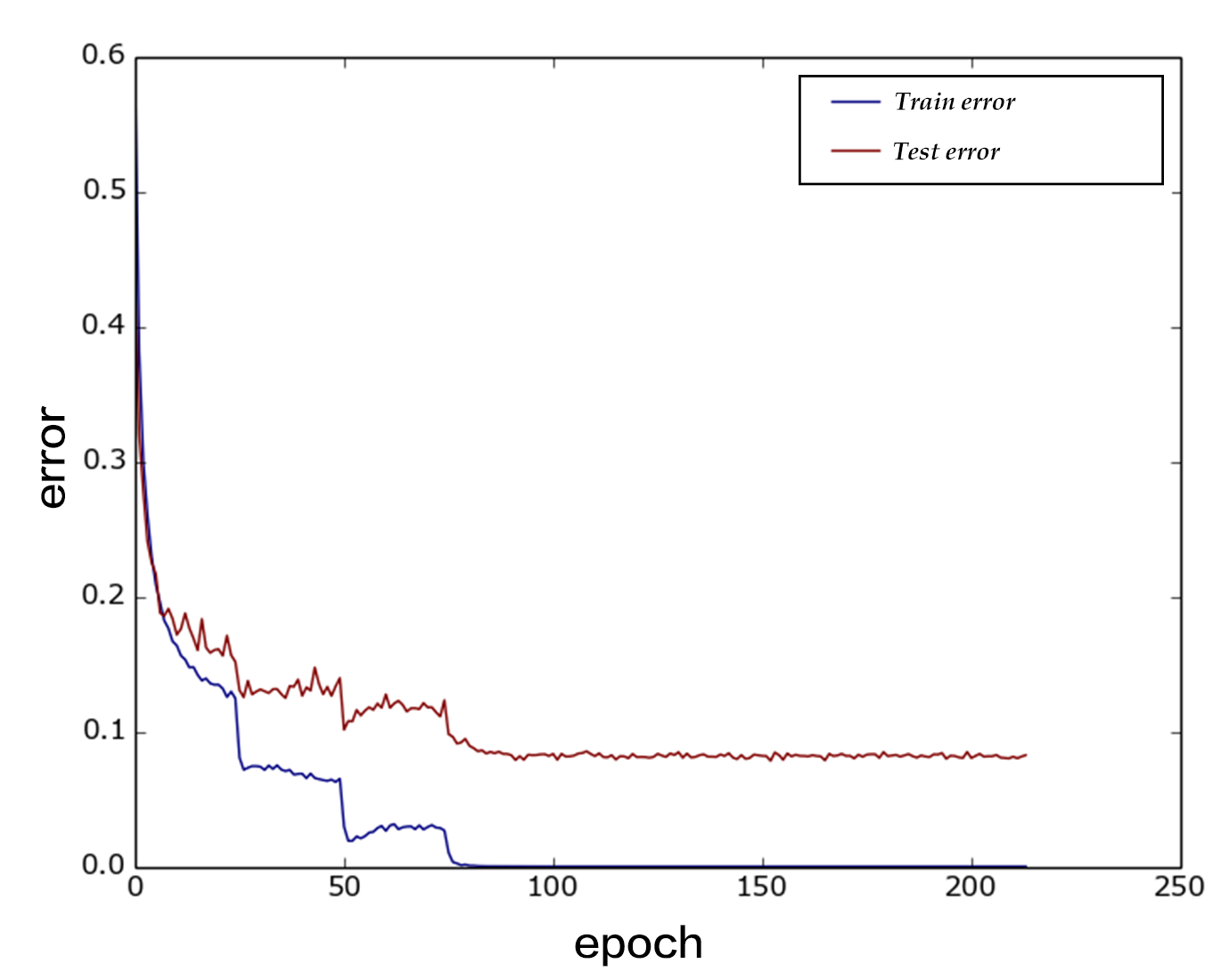
95.9 KB
{kind=link}
{kind=link}
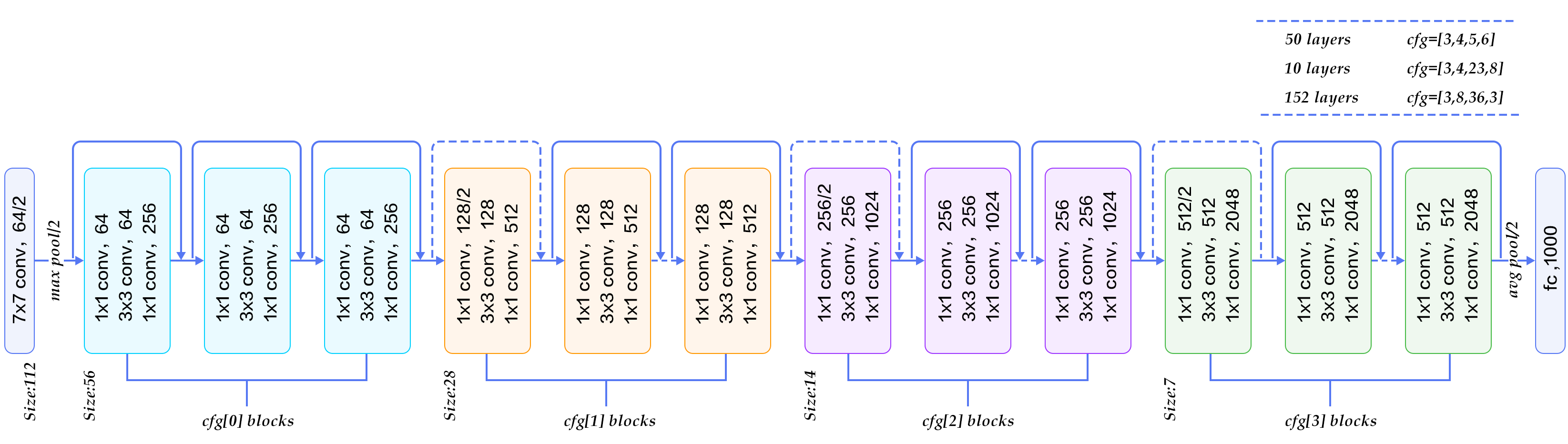
| W: | H:
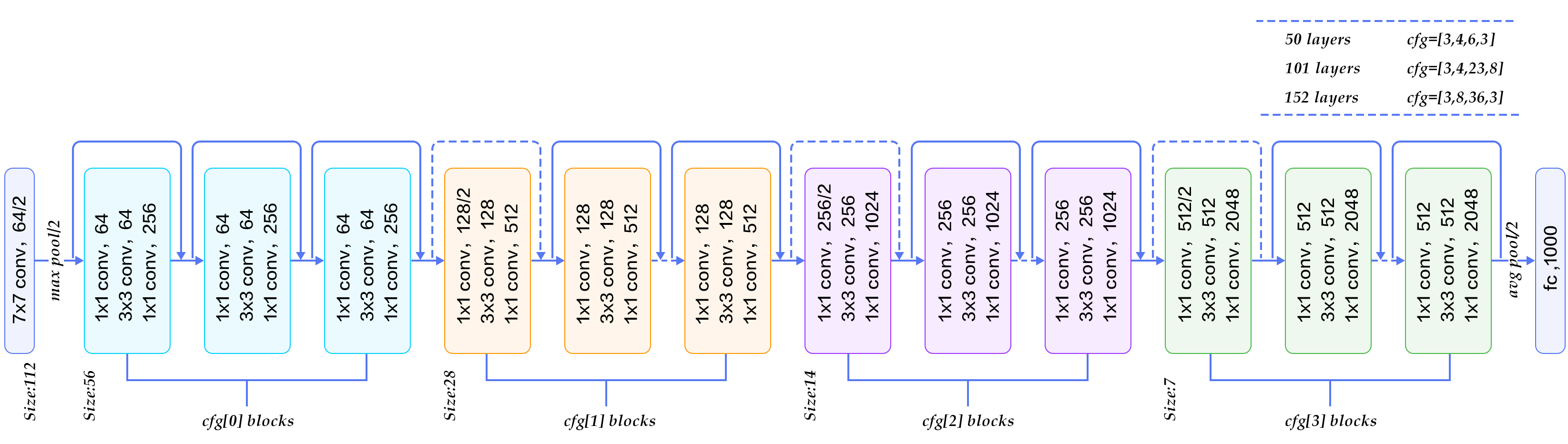
| W: | H:
{kind=link}

2.3 MB
此差异已折叠。
image_classification/index.html
0 → 100644
此差异已折叠。
image_detection/index.html
0 → 100644
image_qa/index.html
0 → 100644
index.html
0 → 100644
此差异已折叠。
label_semantic_roles/README.en.md
0 → 100644
此差异已折叠。
label_semantic_roles/api_train.py
0 → 100644
此差异已折叠。
{kind=link}
{kind=link}
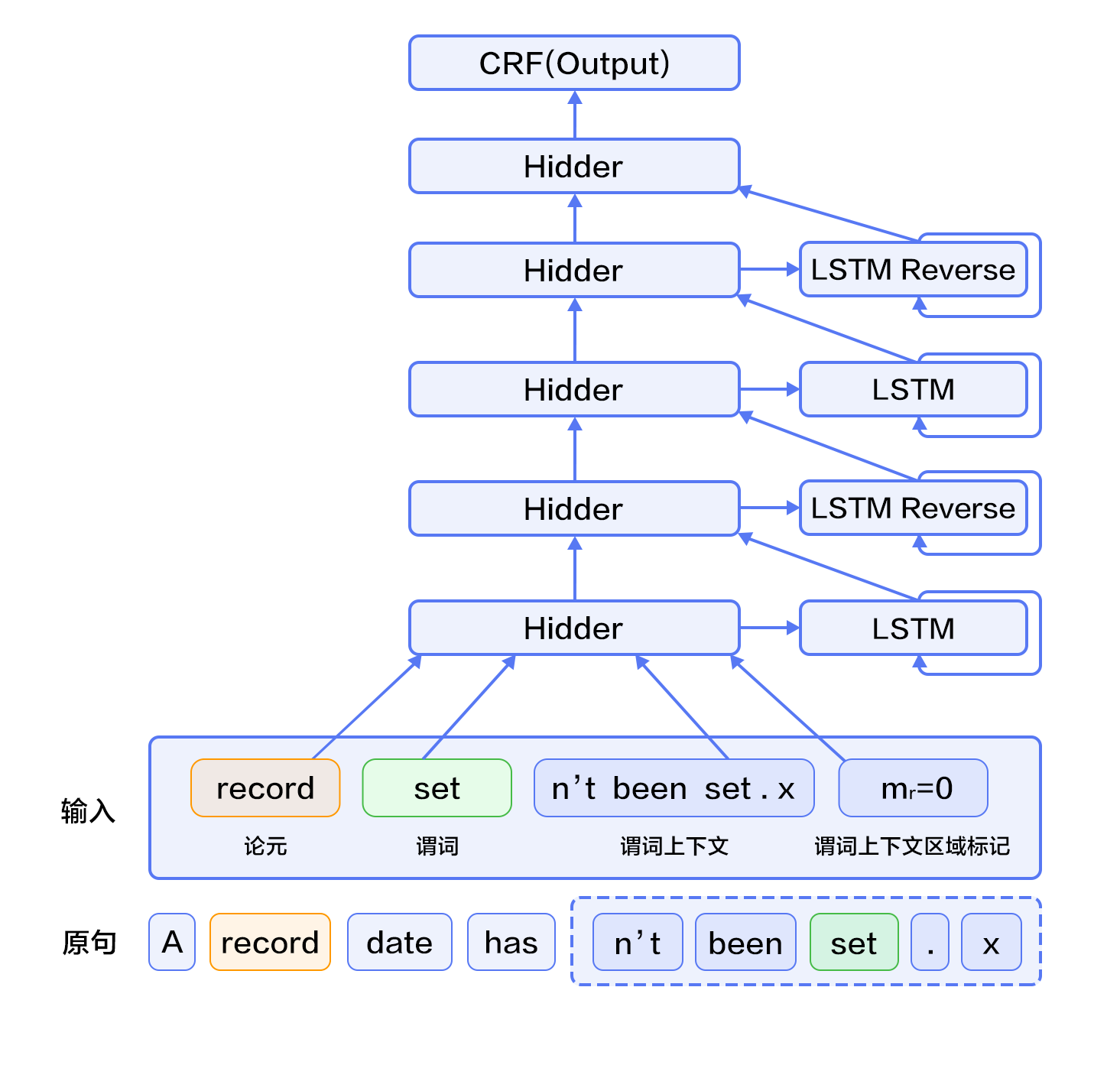
| W: | H:
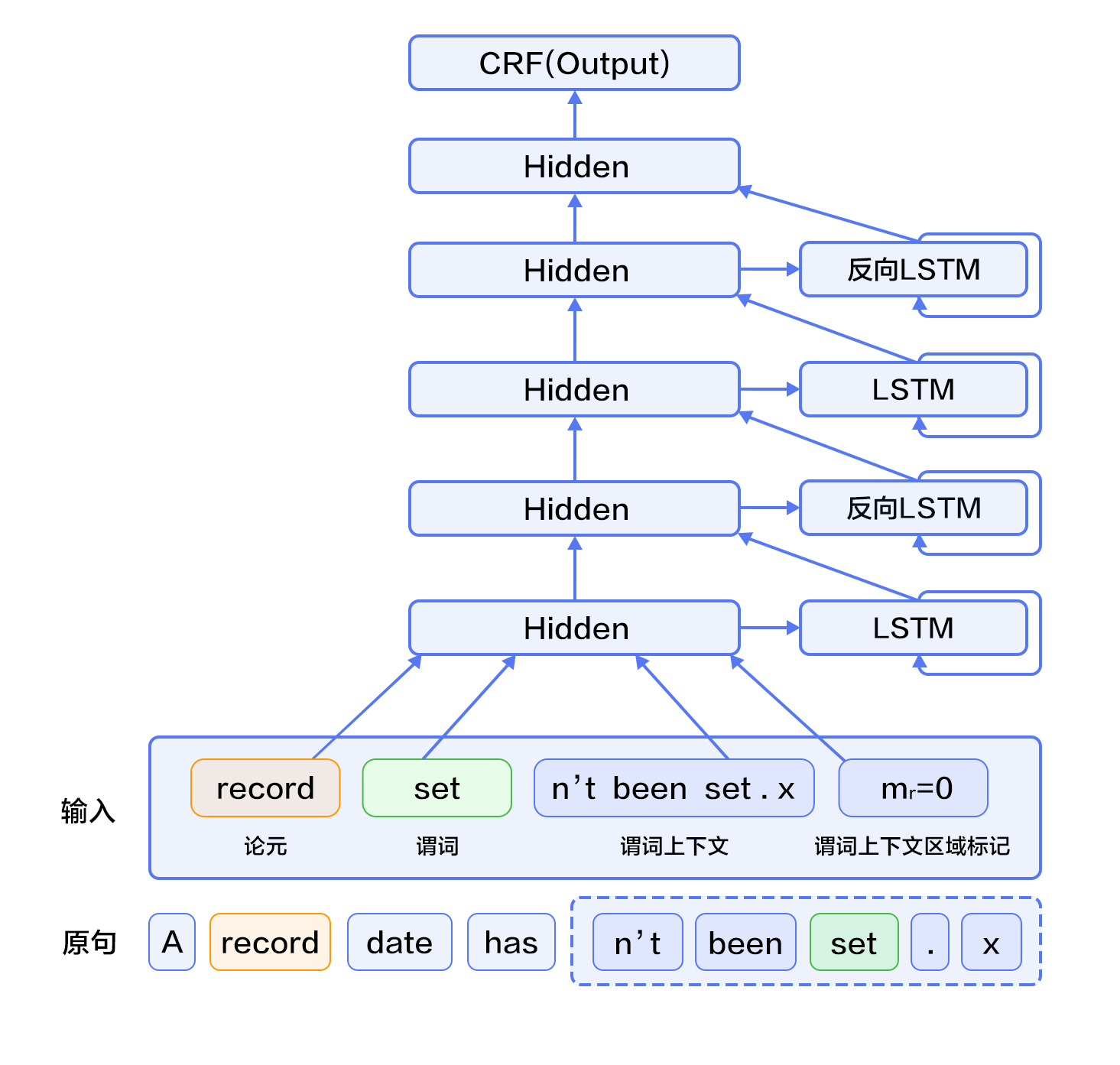
| W: | H:
{kind=link}
{kind=link}
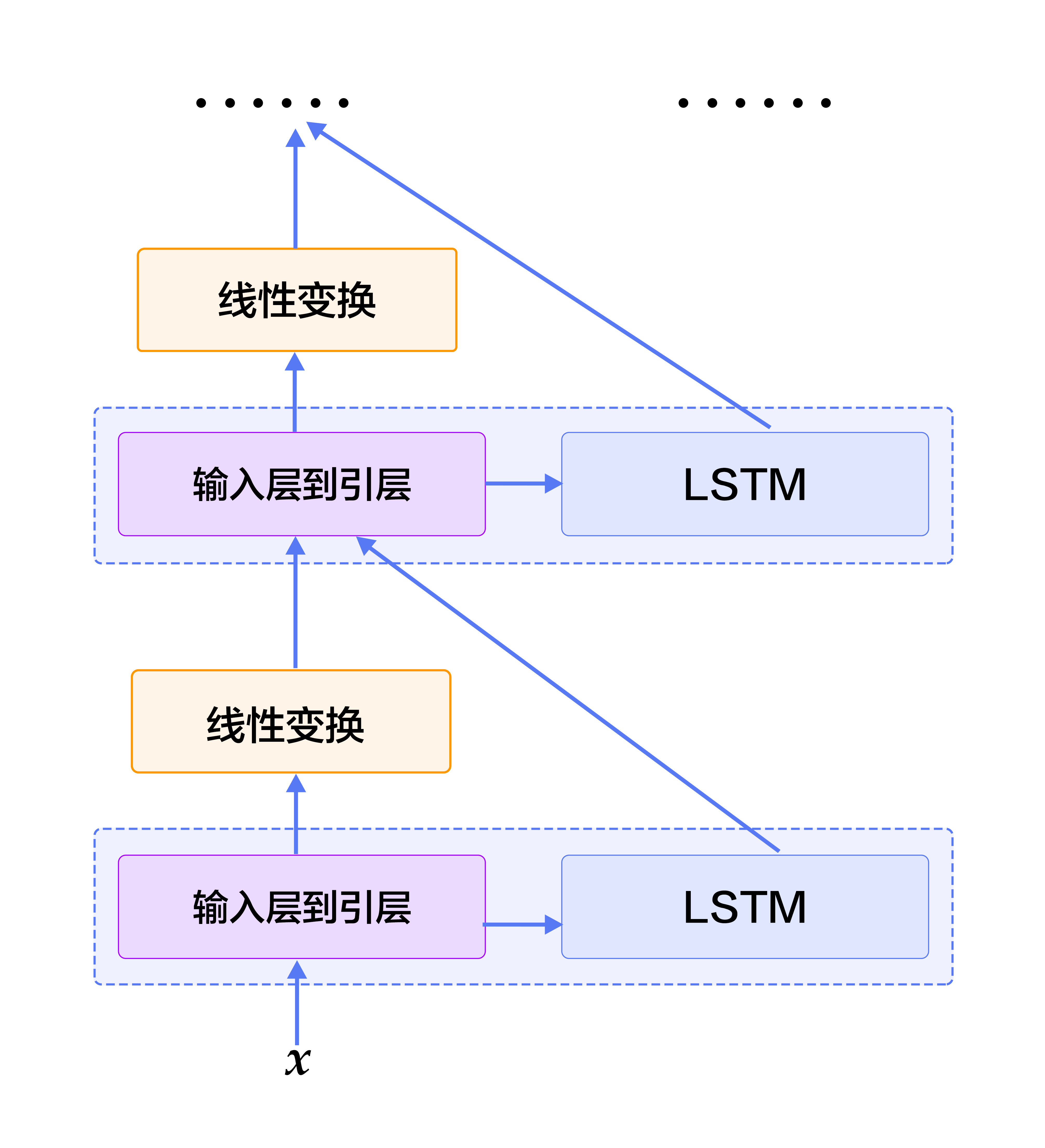
| W: | H:
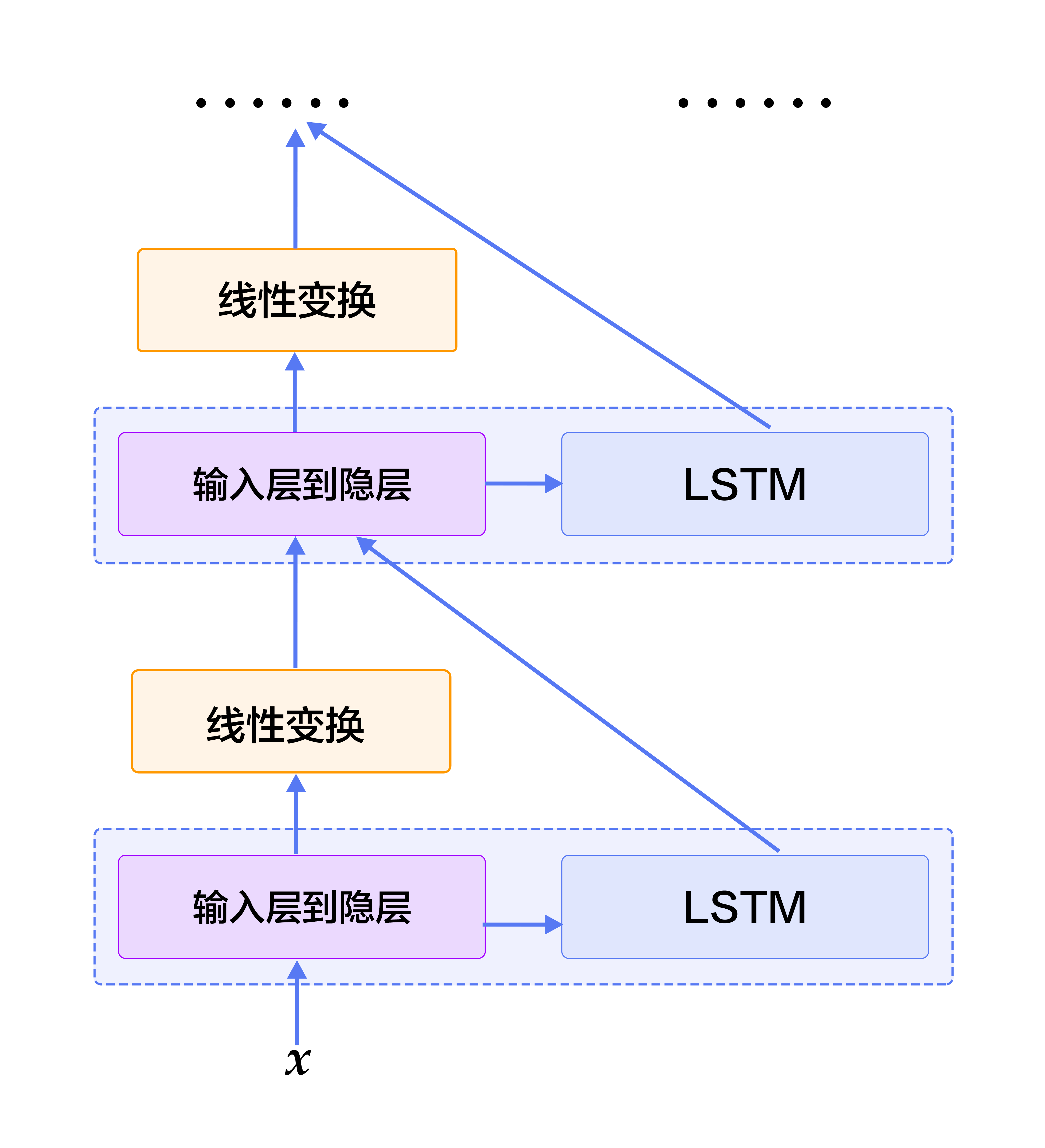
| W: | H:
此差异已折叠。
label_semantic_roles/index.html
0 → 100644
此差异已折叠。
machine_translation/README.en.md
0 → 100644
此差异已折叠。
{kind=link}
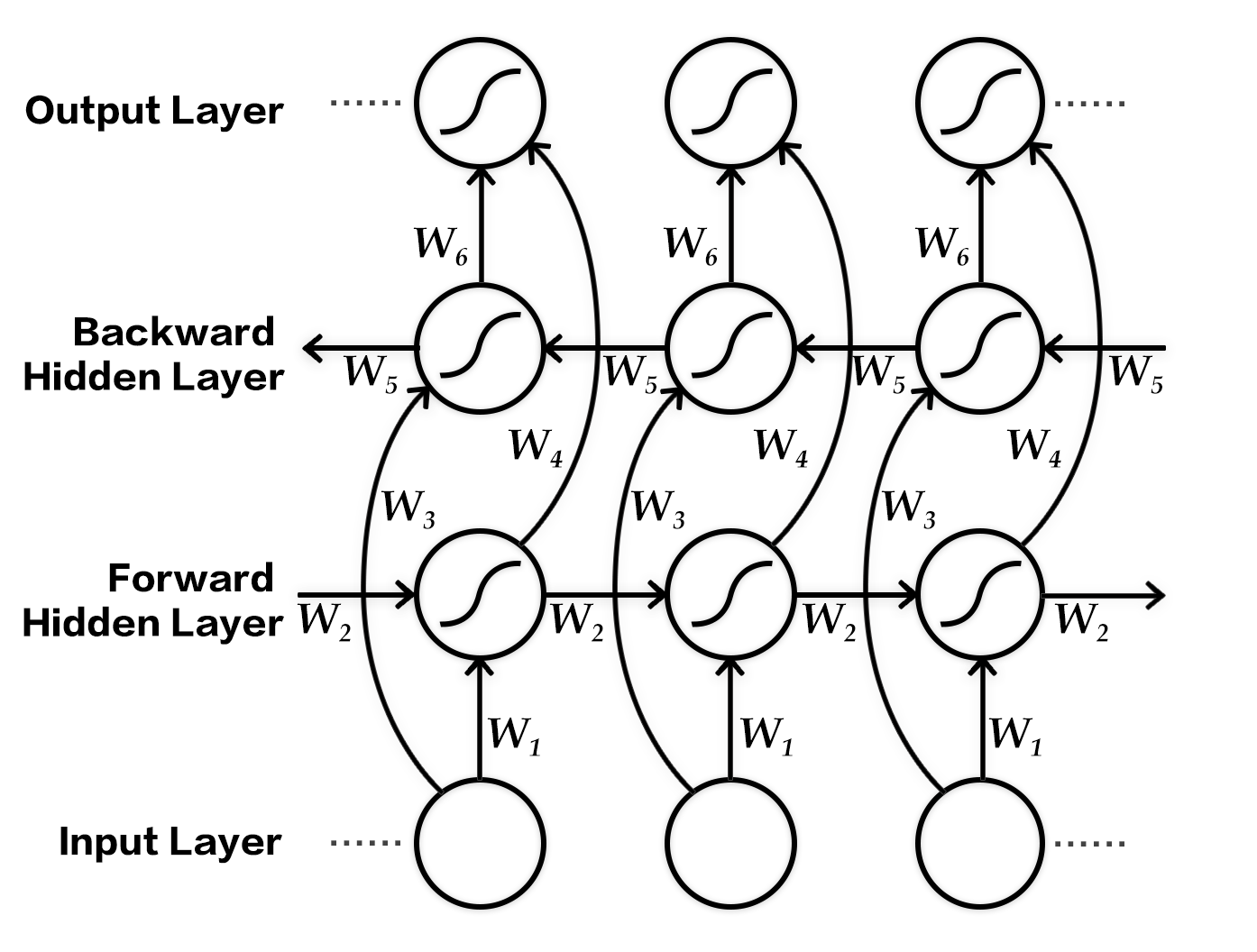
176.3 KB
{kind=link}
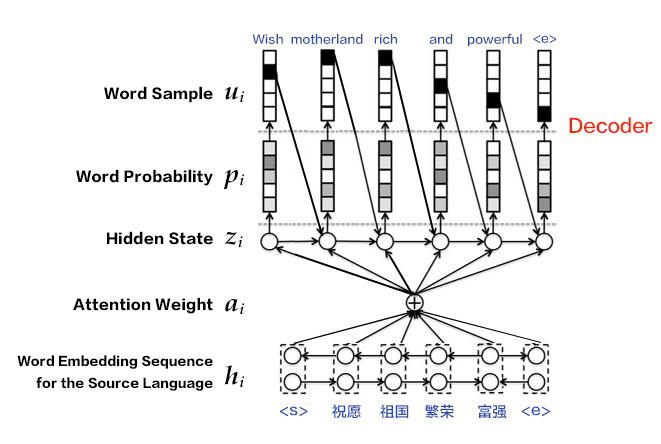
85.7 KB
{kind=link}
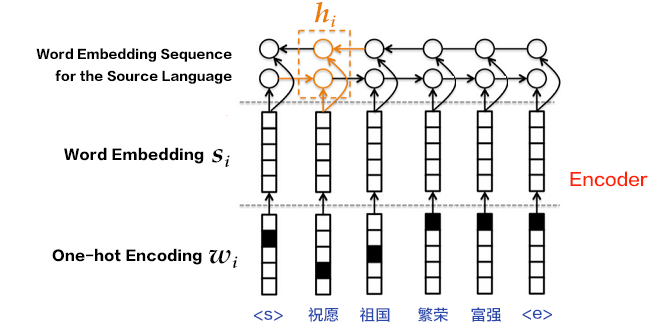
49.7 KB
{kind=link}
{kind=link}
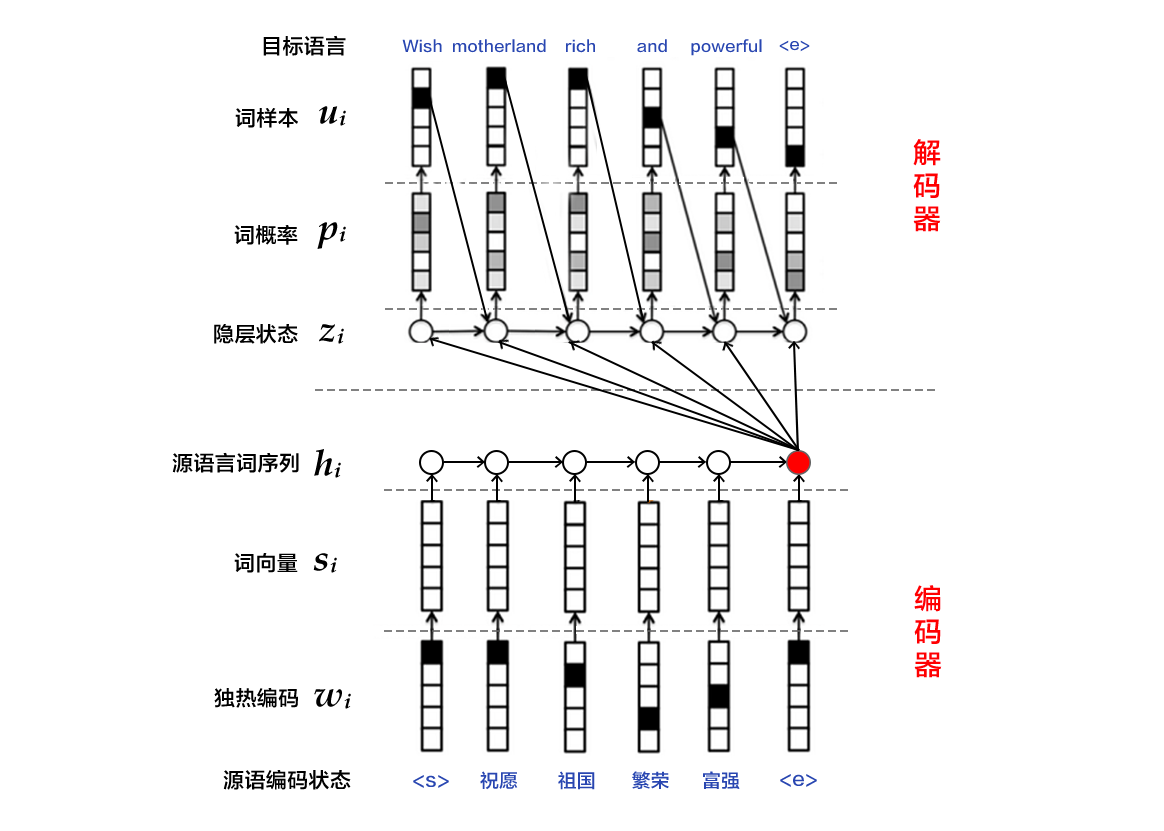
| W: | H:
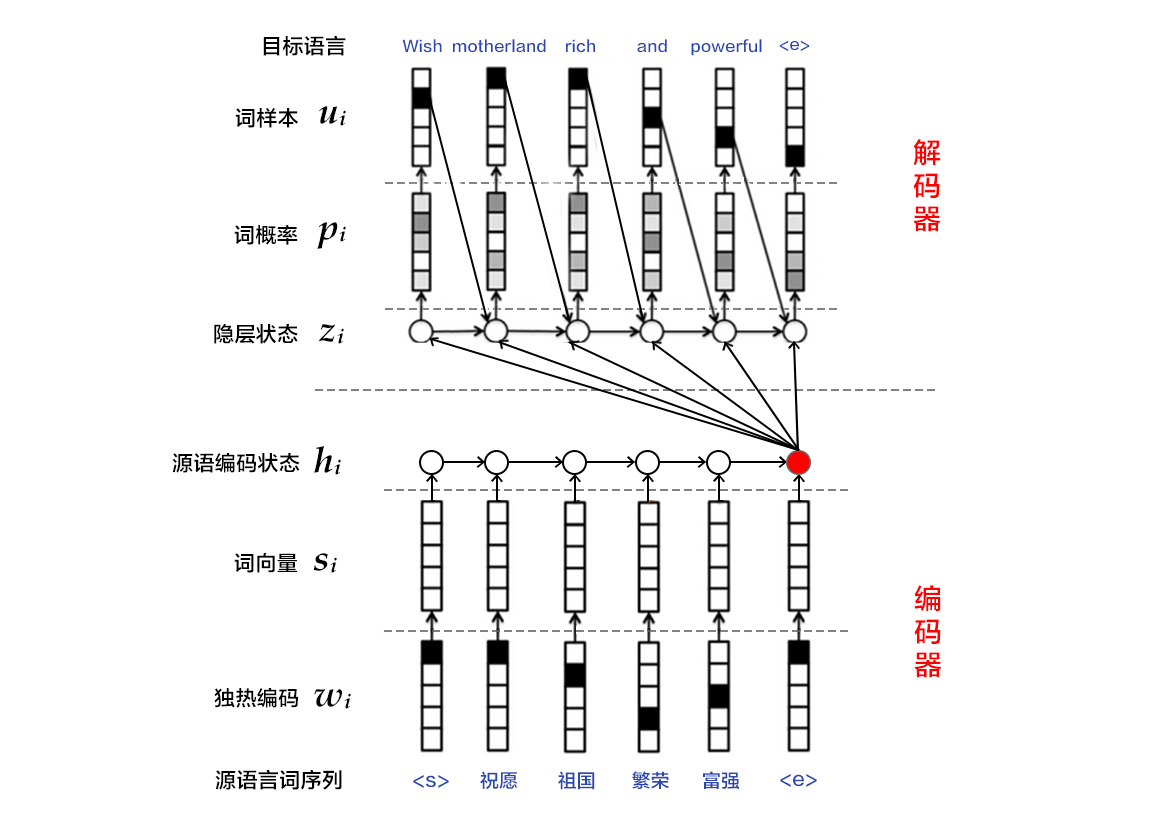
| W: | H:
{kind=link}
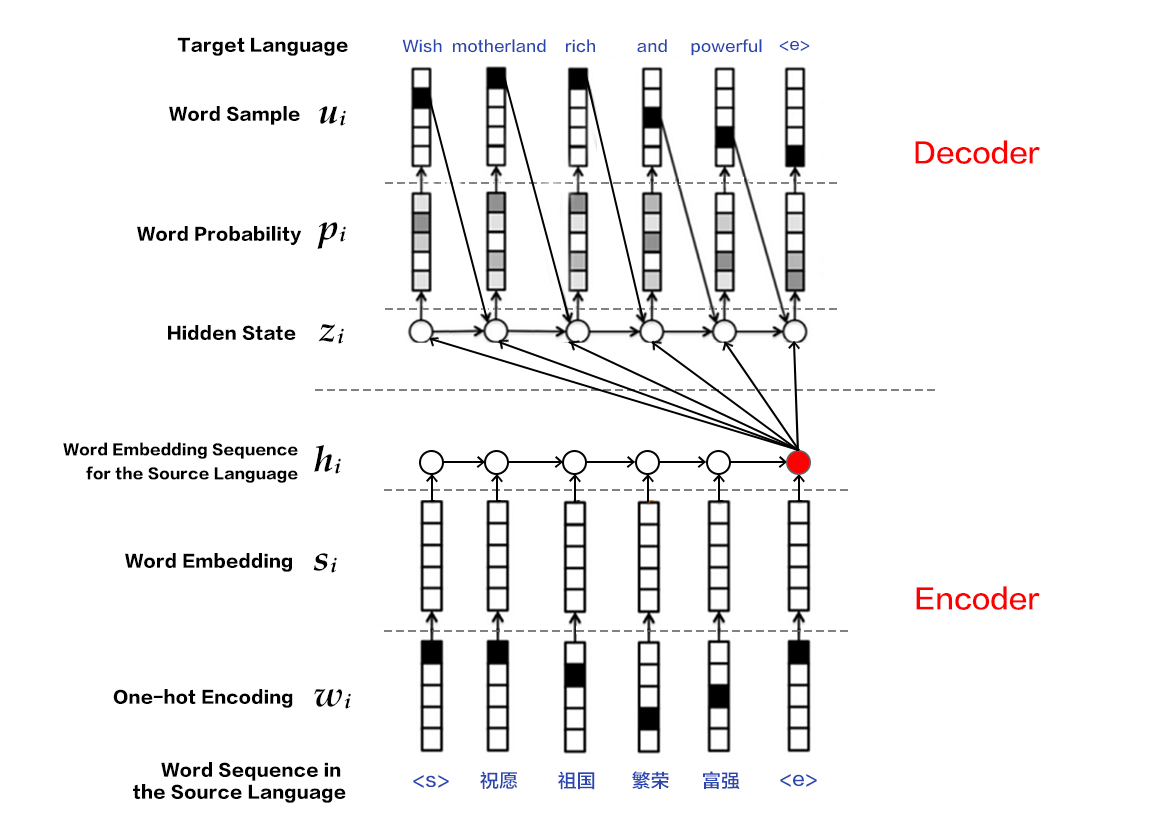
130.7 KB
{kind=link}
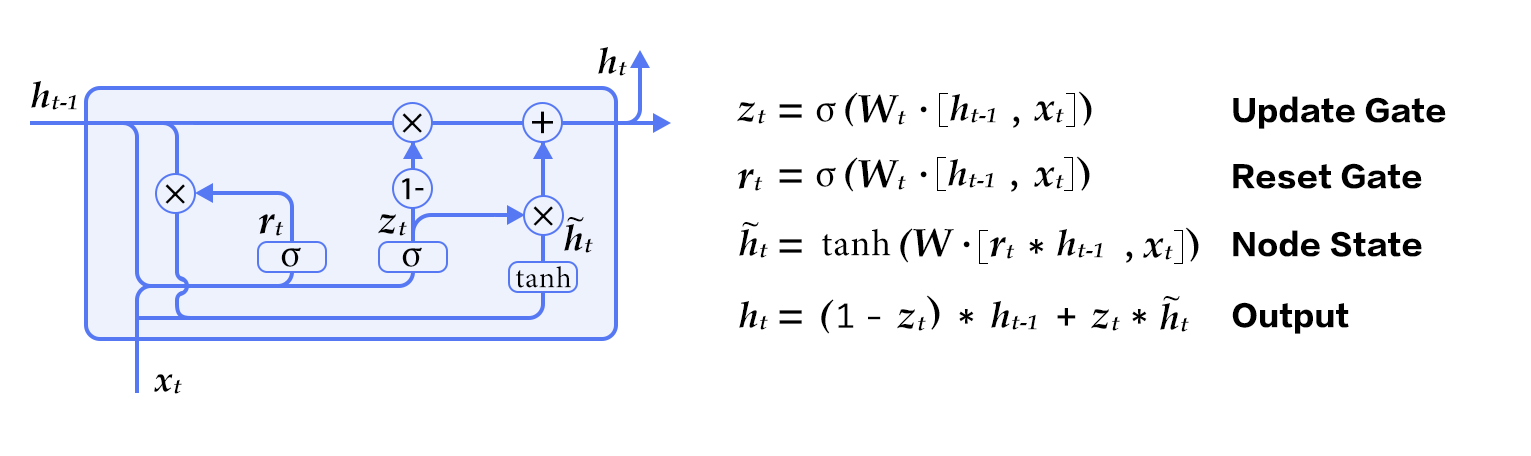
49.2 KB
{kind=link}
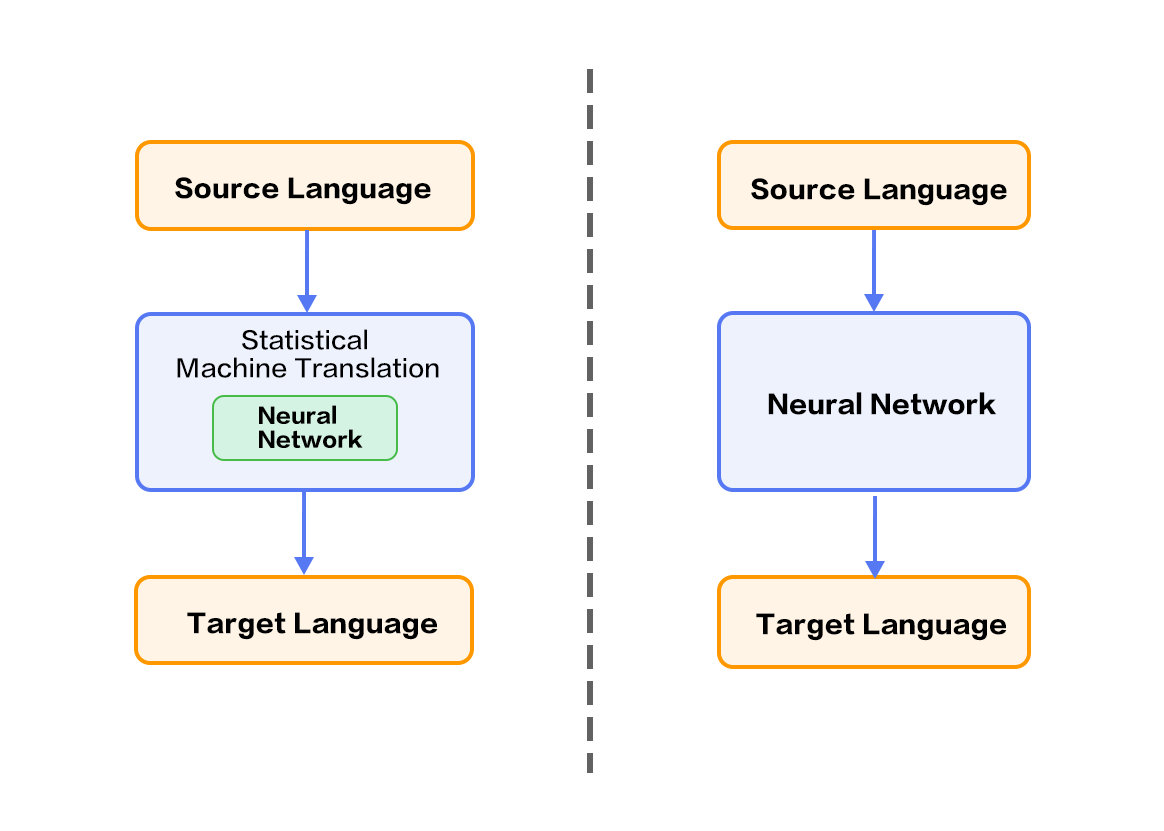
31.3 KB
machine_translation/index.en.html
0 → 100644
此差异已折叠。
machine_translation/index.html
0 → 100644
此差异已折叠。
query_relationship/index.html
0 → 100644
此差异已折叠。
recognize_digits/README.en.md
0 → 100644
此差异已折叠。
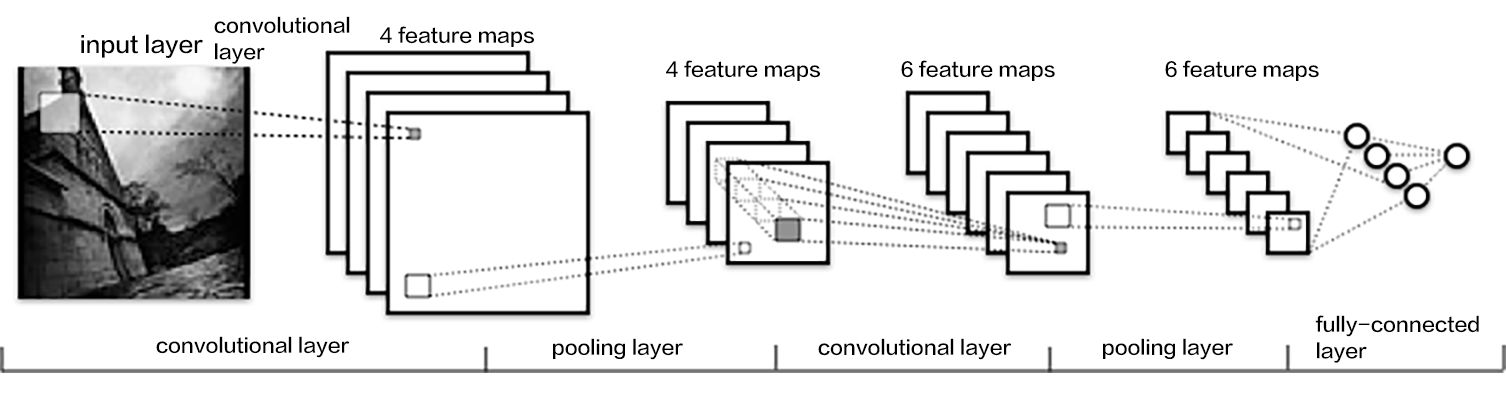
recognize_digits/image/cnn_en.png
0 → 100755
{kind=link}
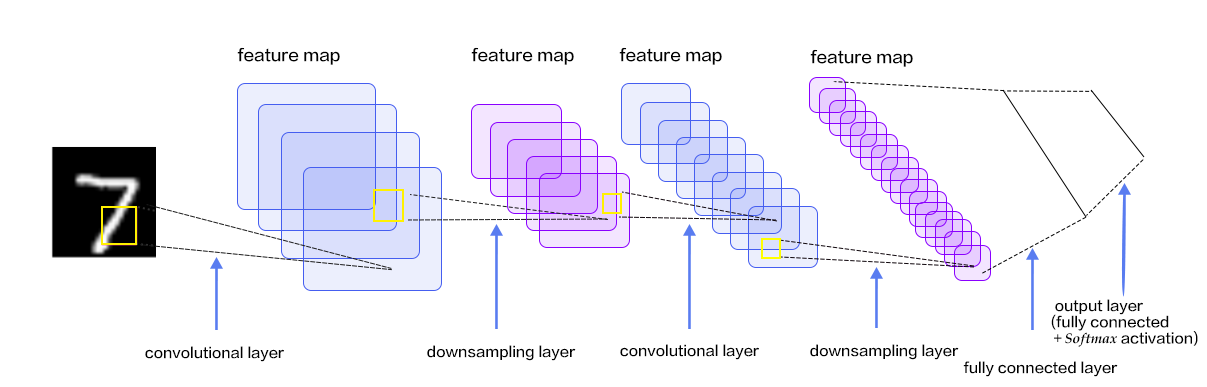
51.0 KB
{kind=link}
82.6 KB
{kind=link}

248.5 KB
{kind=link}

19.5 KB
{kind=link}
{kind=link}
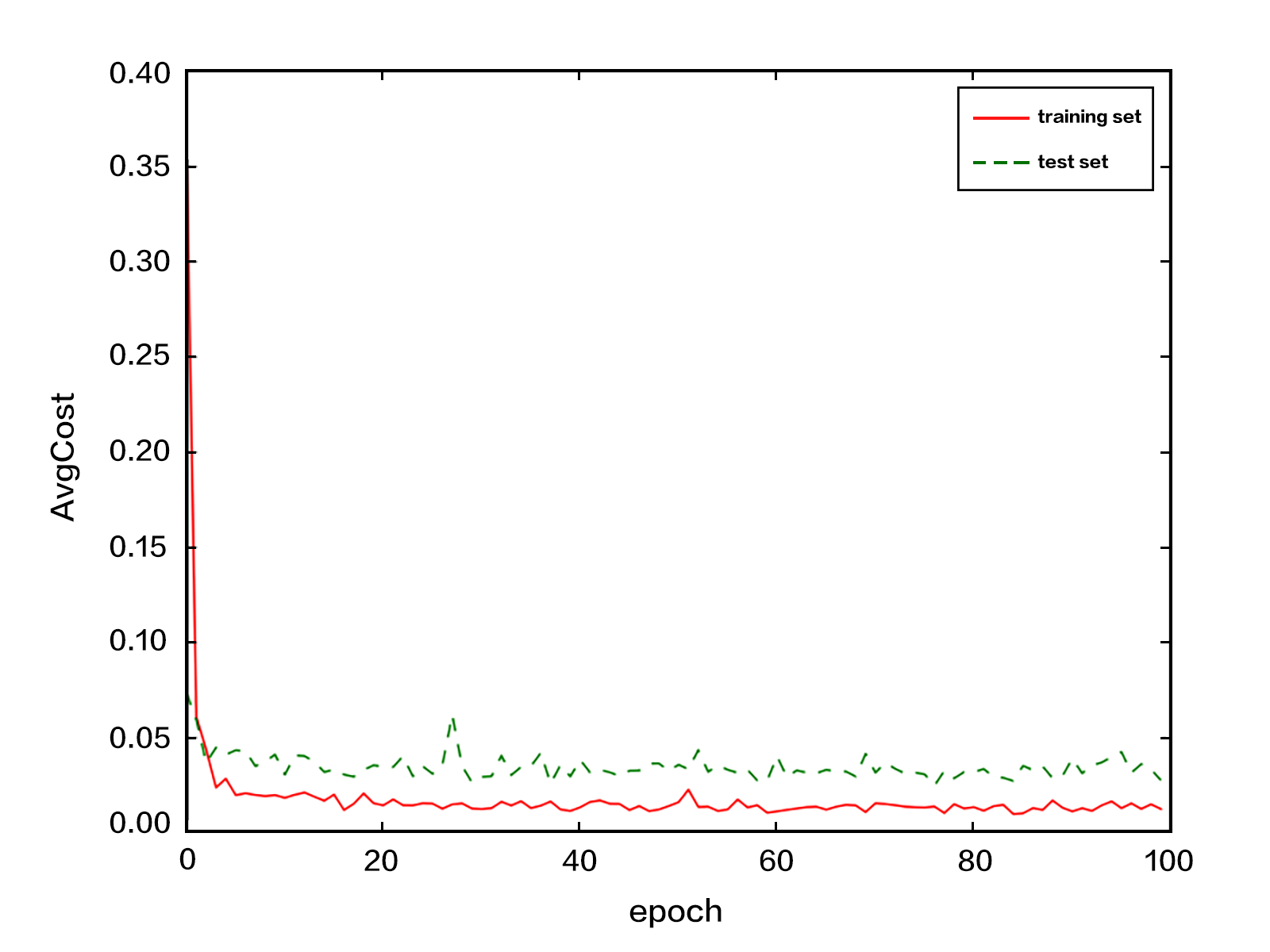
| W: | H:
| W: | H:
recognize_digits/image/mlp_en.png
0 → 100755
{kind=link}
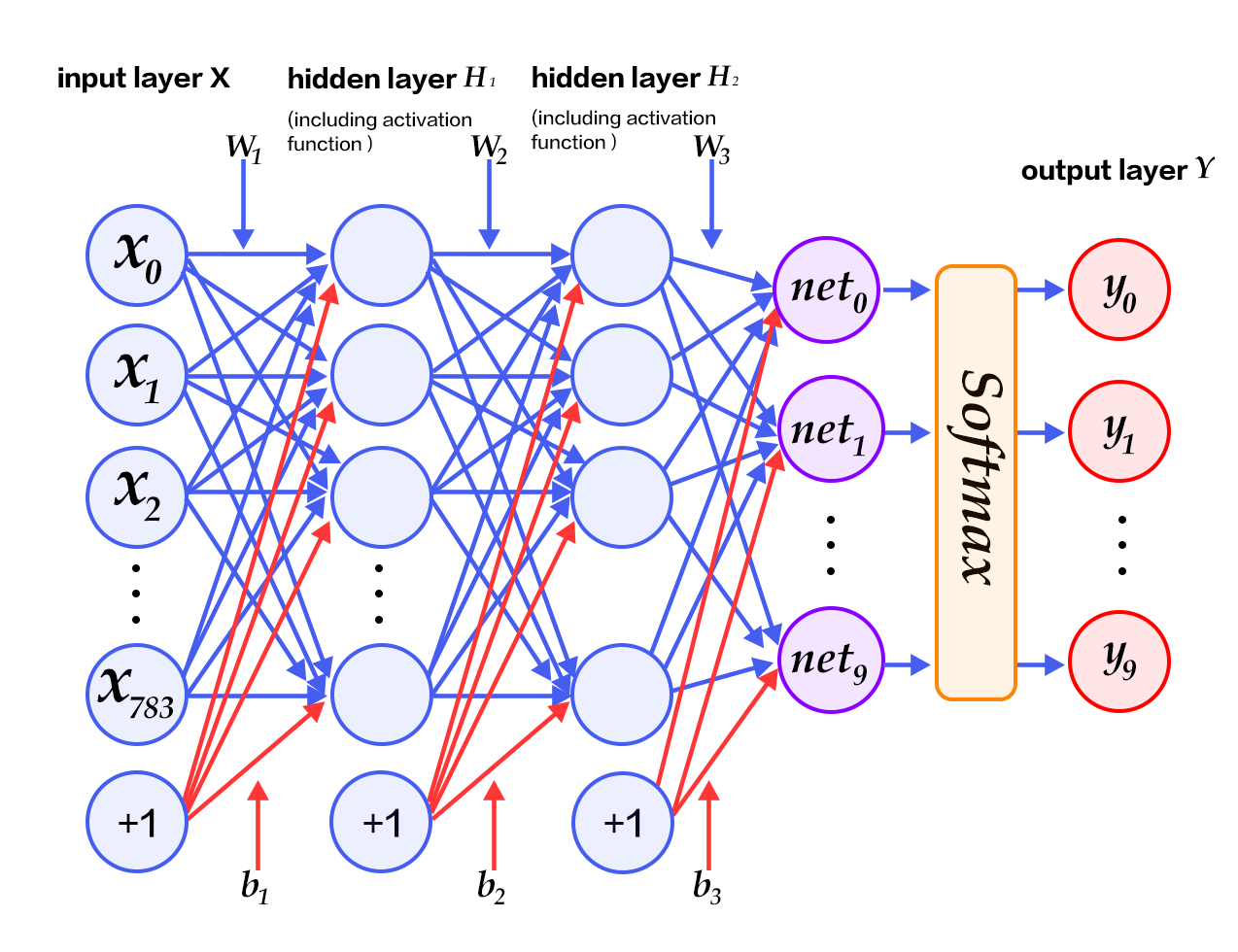
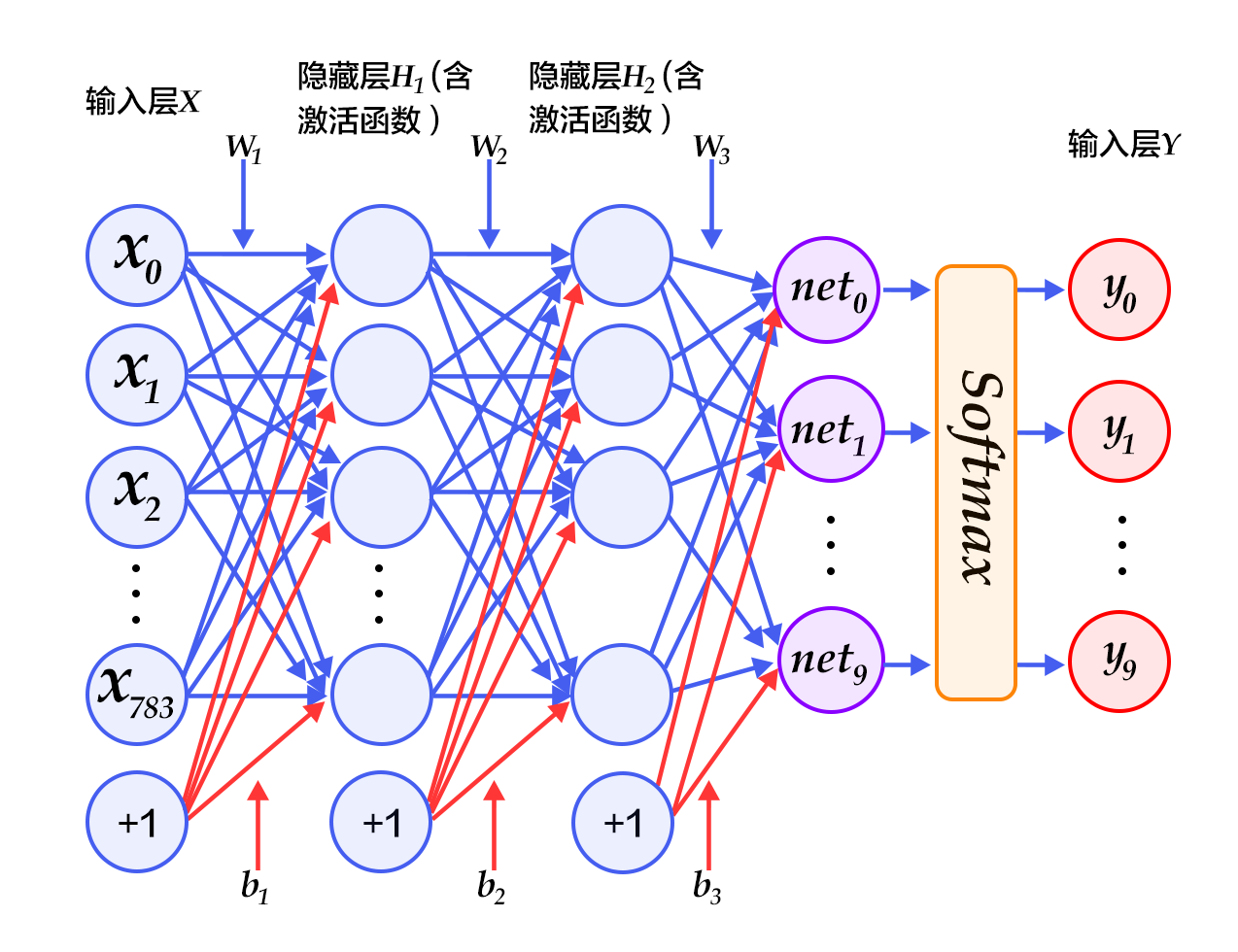
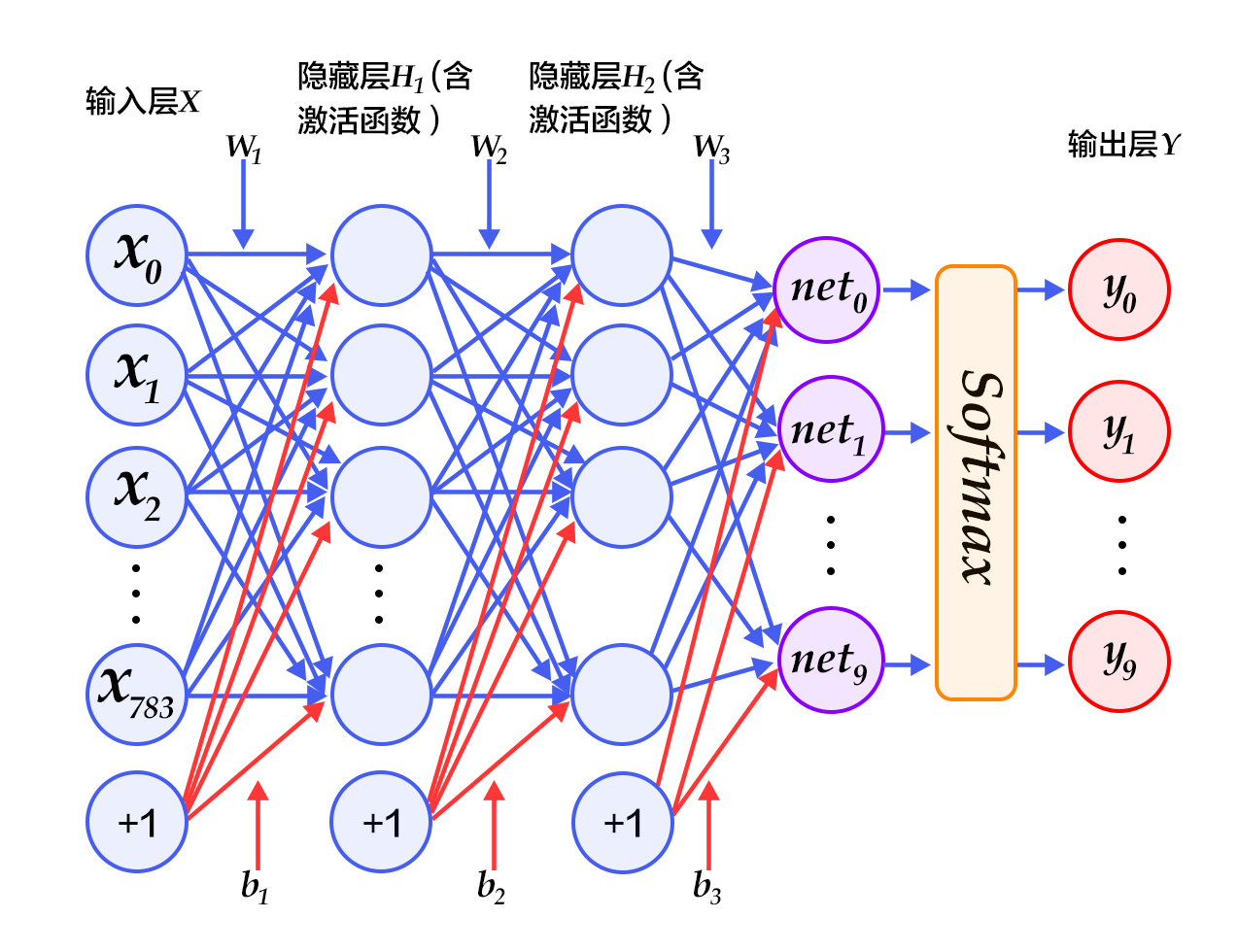
190.2 KB
{kind=link}
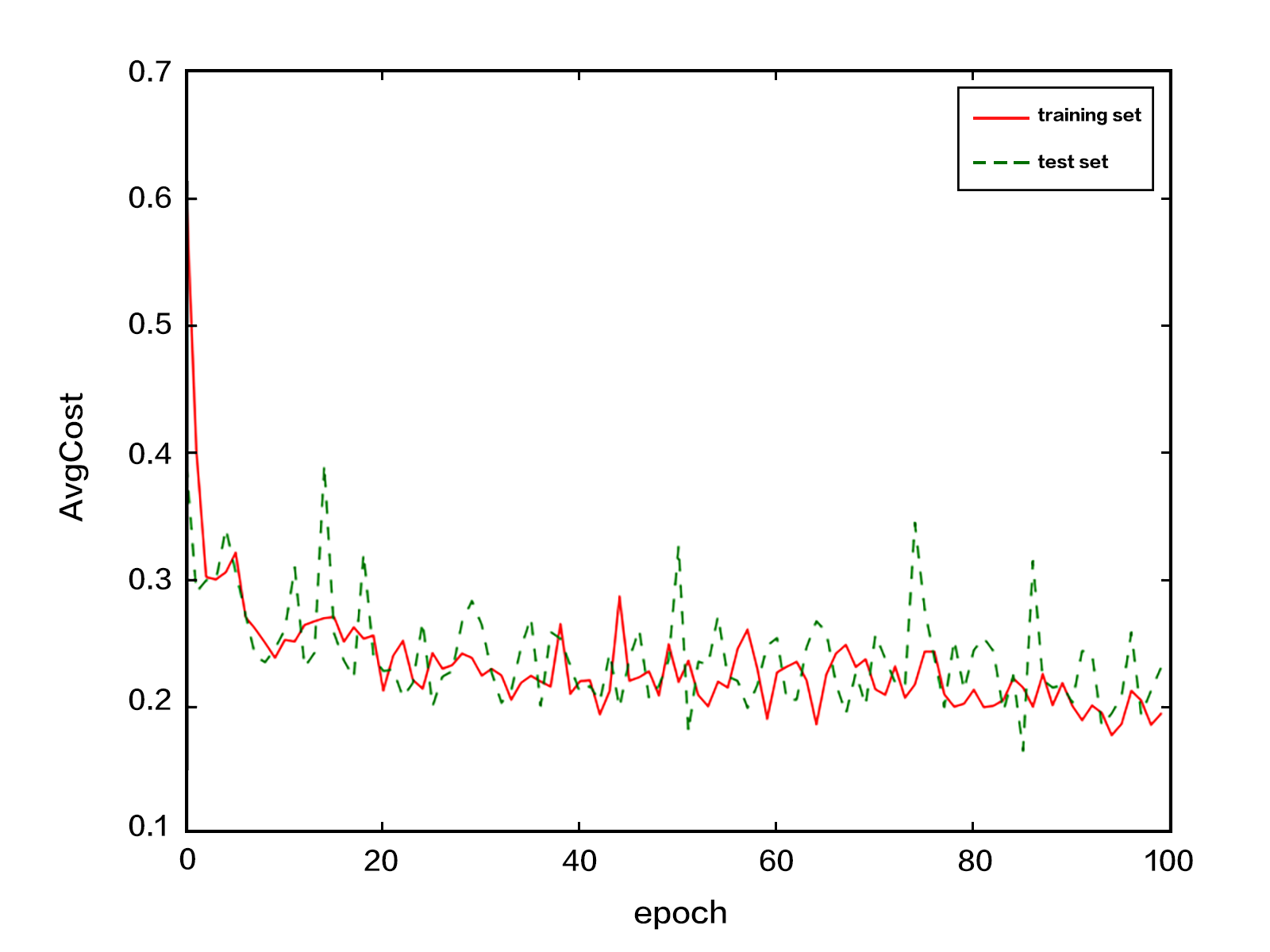
142.2 KB
{kind=link}
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
recognize_digits/index.en.html
0 → 100644
此差异已折叠。
recognize_digits/index.html
0 → 100644
此差异已折叠。
recommender_system/README.en.md
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
{kind=link}
此差异已折叠。
{kind=link}
{kind=link}
此差异已折叠。
recommender_system/index.en.html
0 → 100644
此差异已折叠。
recommender_system/index.html
0 → 100644
此差异已折叠。
skip_thought/index.html
0 → 100644
此差异已折叠。
speech_recognition/index.html
0 → 100644
此差异已折叠。
understand_sentiment/README.en.md
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
understand_sentiment/index.html
0 → 100644
此差异已折叠。
word2vec/README.en.md
0 → 100644
此差异已折叠。
此差异已折叠。
word2vec/data/getdata.sh
已删除
100755 → 0
此差异已折叠。
word2vec/dataprovider.py
已删除
100644 → 0
此差异已折叠。
word2vec/image/cbow_en.png
0 → 100755
{kind=link}
此差异已折叠。
word2vec/image/ngram.en.png
0 → 100755
{kind=link}
此差异已折叠。
word2vec/image/nnlm_en.png
0 → 100755
{kind=link}
此差异已折叠。
word2vec/image/skipgram_en.png
0 → 100755
{kind=link}
此差异已折叠。
word2vec/index.en.html
0 → 100644
此差异已折叠。
word2vec/index.html
0 → 100644
此差异已折叠。
word2vec/ngram.py
已删除
100644 → 0
此差异已折叠。
word2vec/train.py
0 → 100644
此差异已折叠。
word2vec/train.sh
已删除
100755 → 0
此差异已折叠。