update
Showing
01.fit_a_line/README.cn.md
0 → 100644
01.fit_a_line/README.en.md
已删除
100644 → 0
01.fit_a_line/index.cn.html
0 → 100644
01.fit_a_line/index.en.html
已删除
100644 → 0
此差异已折叠。
04.word2vec/README.cn.md
0 → 100644
此差异已折叠。
04.word2vec/README.en.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
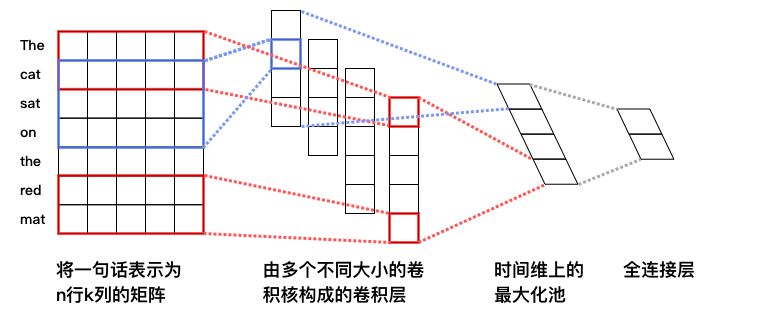
51.0 KB
{kind=link}
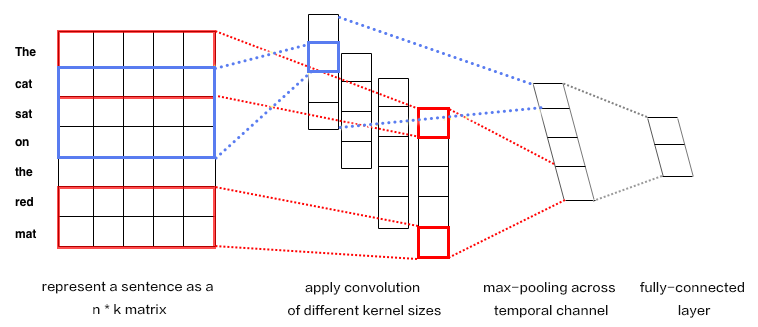
39.3 KB
{kind=link}
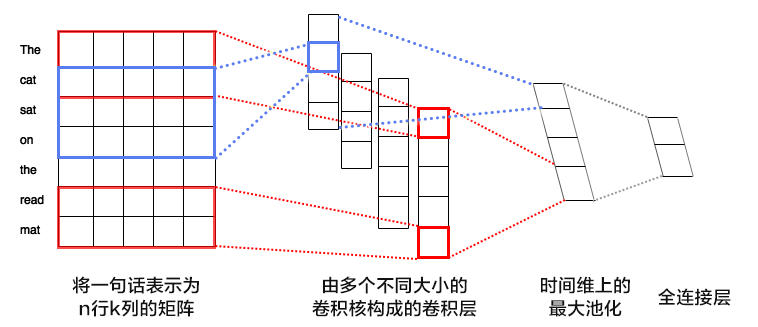
35.9 KB
{kind=link}
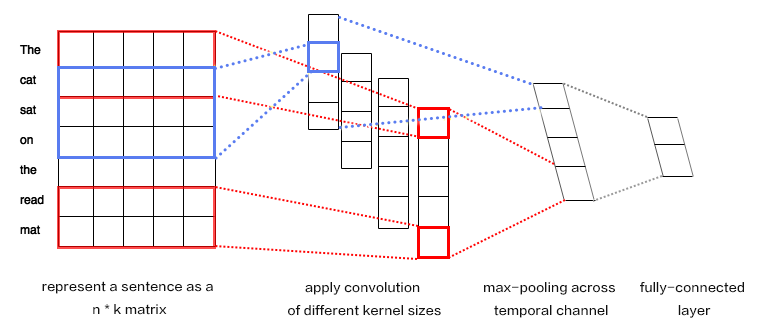
31.8 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
README.cn.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。