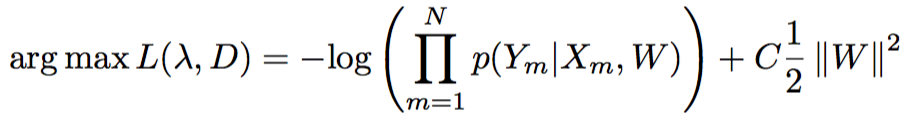语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
{kind=link}
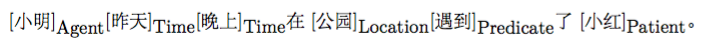
{kind=link}
{kind=link}
{kind=link}