Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
book
提交
8453aff4
B
book
项目概览
PaddlePaddle
/
book
通知
17
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
40
列表
看板
标记
里程碑
合并请求
37
Wiki
5
Wiki
分析
仓库
DevOps
项目成员
Pages
B
book
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
40
Issue
40
列表
看板
标记
里程碑
合并请求
37
合并请求
37
Pages
分析
分析
仓库分析
DevOps
Wiki
5
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
8453aff4
编写于
1月 08, 2017
作者:
D
dangqingqing
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update README.md
上级
aec1c2f0
变更
6
展开全部
隐藏空白更改
内联
并排
Showing
6 changed file
with
204 addition
and
169 deletion
+204
-169
image_classification/README.md
image_classification/README.md
+172
-140
image_classification/dataprovider.py
image_classification/dataprovider.py
+2
-0
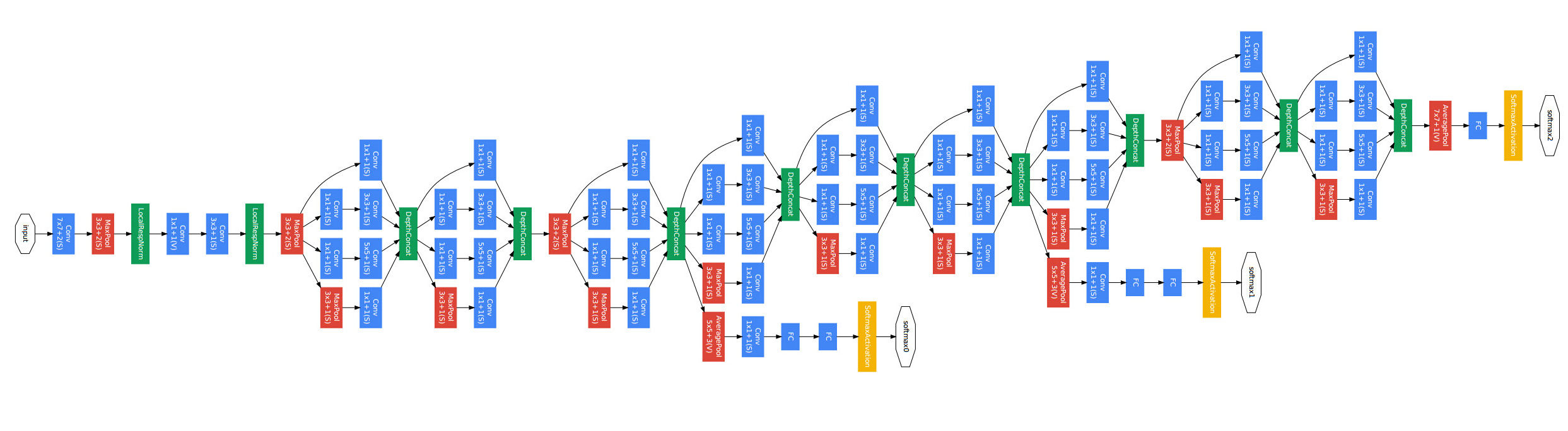
image_classification/image/googlenet.jpeg
image_classification/image/googlenet.jpeg
+0
-0
image_classification/models/resnet.py
image_classification/models/resnet.py
+18
-17
image_classification/models/vgg.py
image_classification/models/vgg.py
+11
-11
image_classification/train.sh
image_classification/train.sh
+1
-1
未找到文件。
image_classification/README.md
浏览文件 @
8453aff4
此差异已折叠。
点击以展开。
image_classification/dataprovider.py
浏览文件 @
8453aff4
...
@@ -37,5 +37,7 @@ def process(settings, file_list):
...
@@ -37,5 +37,7 @@ def process(settings, file_list):
images
=
batch
[
'data'
]
images
=
batch
[
'data'
]
labels
=
batch
[
'labels'
]
labels
=
batch
[
'labels'
]
for
im
,
lab
in
zip
(
images
,
labels
):
for
im
,
lab
in
zip
(
images
,
labels
):
if
settings
.
is_train
and
np
.
random
.
randint
(
2
):
im
=
im
[:,
:,
::
-
1
]
im
=
im
-
settings
.
mean
im
=
im
-
settings
.
mean
yield
{
'image'
:
im
.
astype
(
'float32'
),
'label'
:
int
(
lab
)}
yield
{
'image'
:
im
.
astype
(
'float32'
),
'label'
:
int
(
lab
)}
image_classification/image/googlenet.jpeg
0 → 100644
浏览文件 @
8453aff4
352.2 KB
image_classification/models/resnet.py
浏览文件 @
8453aff4
...
@@ -22,16 +22,16 @@ if not is_predict:
...
@@ -22,16 +22,16 @@ if not is_predict:
test_list
=
'data/test.list'
,
test_list
=
'data/test.list'
,
module
=
'dataprovider'
,
module
=
'dataprovider'
,
obj
=
'process'
,
obj
=
'process'
,
args
=
args
)
args
=
{
'mean_path'
:
'data/mean.meta'
}
)
settings
(
settings
(
batch_size
=
128
,
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
1
0
0
,
learning_rate_decay_b
=
50000
*
1
4
0
,
learning_rate_schedule
=
'discexp'
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.000
1
*
128
))
regularization
=
L2Regularization
(
0.000
2
*
128
))
def
conv_bn_layer
(
input
,
def
conv_bn_layer
(
input
,
...
@@ -55,6 +55,7 @@ def conv_bn_layer(input,
...
@@ -55,6 +55,7 @@ def conv_bn_layer(input,
def
shortcut
(
ipt
,
n_in
,
n_out
,
stride
):
def
shortcut
(
ipt
,
n_in
,
n_out
,
stride
):
if
n_in
!=
n_out
:
if
n_in
!=
n_out
:
print
(
"n_in != n_out"
)
return
conv_bn_layer
(
ipt
,
n_out
,
1
,
stride
,
0
,
LinearActivation
())
return
conv_bn_layer
(
ipt
,
n_out
,
1
,
stride
,
0
,
LinearActivation
())
else
:
else
:
return
ipt
return
ipt
...
@@ -65,7 +66,7 @@ def basicblock(ipt, ch_out, stride):
...
@@ -65,7 +66,7 @@ def basicblock(ipt, ch_out, stride):
tmp
=
conv_bn_layer
(
ipt
,
ch_out
,
3
,
stride
,
1
)
tmp
=
conv_bn_layer
(
ipt
,
ch_out
,
3
,
stride
,
1
)
tmp
=
conv_bn_layer
(
tmp
,
ch_out
,
3
,
1
,
1
,
LinearActivation
())
tmp
=
conv_bn_layer
(
tmp
,
ch_out
,
3
,
1
,
1
,
LinearActivation
())
short
=
shortcut
(
ipt
,
ch_in
,
ch_out
,
stride
)
short
=
shortcut
(
ipt
,
ch_in
,
ch_out
,
stride
)
return
addto_layer
(
input
=
[
ipt
,
short
],
act
=
ReluActivation
())
return
addto_layer
(
input
=
[
tmp
,
short
],
act
=
ReluActivation
())
def
bottleneck
(
ipt
,
ch_out
,
stride
):
def
bottleneck
(
ipt
,
ch_out
,
stride
):
...
@@ -73,8 +74,8 @@ def bottleneck(ipt, ch_out, stride):
...
@@ -73,8 +74,8 @@ def bottleneck(ipt, ch_out, stride):
tmp
=
conv_bn_layer
(
ipt
,
ch_out
,
1
,
stride
,
0
)
tmp
=
conv_bn_layer
(
ipt
,
ch_out
,
1
,
stride
,
0
)
tmp
=
conv_bn_layer
(
tmp
,
ch_out
,
3
,
1
,
1
)
tmp
=
conv_bn_layer
(
tmp
,
ch_out
,
3
,
1
,
1
)
tmp
=
conv_bn_layer
(
tmp
,
ch_out
*
4
,
1
,
1
,
0
,
LinearActivation
())
tmp
=
conv_bn_layer
(
tmp
,
ch_out
*
4
,
1
,
1
,
0
,
LinearActivation
())
short
=
shortcut
(
ipt
,
ch_in
,
ch_out
,
stride
)
short
=
shortcut
(
ipt
,
ch_in
,
ch_out
*
4
,
stride
)
return
addto_layer
(
input
=
[
ipt
,
short
],
act
=
ReluActivation
())
return
addto_layer
(
input
=
[
tmp
,
short
],
act
=
ReluActivation
())
def
layer_warp
(
block_func
,
ipt
,
features
,
count
,
stride
):
def
layer_warp
(
block_func
,
ipt
,
features
,
count
,
stride
):
...
@@ -107,25 +108,25 @@ def resnet_imagenet(ipt, depth=50):
...
@@ -107,25 +108,25 @@ def resnet_imagenet(ipt, depth=50):
return
tmp
return
tmp
def
resnet_cifar10
(
ipt
,
depth
=
56
):
def
resnet_cifar10
(
ipt
,
depth
=
32
):
assert
((
depth
-
2
)
%
6
==
0
,
#depth should be one of 20, 32, 44, 56, 110, 1202
'depth should be one of 20, 32, 44, 56, 110, 1202'
)
assert
(
depth
-
2
)
%
6
==
0
n
=
(
depth
-
2
)
/
6
n
=
(
depth
-
2
)
/
6
nStages
=
{
16
,
64
,
128
}
nStages
=
{
16
,
64
,
128
}
tmp
=
conv_bn_layer
(
conv1
=
conv_bn_layer
(
ipt
,
ch_in
=
3
,
ch_out
=
16
,
filter_size
=
3
,
stride
=
1
,
padding
=
1
)
ipt
,
ch_in
=
3
,
ch_out
=
16
,
filter_size
=
3
,
stride
=
1
,
padding
=
1
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
16
,
n
,
1
)
res1
=
layer_warp
(
basicblock
,
conv1
,
16
,
n
,
1
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
32
,
n
,
2
)
res2
=
layer_warp
(
basicblock
,
res1
,
32
,
n
,
2
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
64
,
n
,
2
)
res3
=
layer_warp
(
basicblock
,
res2
,
64
,
n
,
2
)
tmp
=
img_pool_layer
(
pool
=
img_pool_layer
(
input
=
tmp
,
pool_size
=
8
,
stride
=
1
,
pool_type
=
AvgPooling
())
input
=
res3
,
pool_size
=
8
,
stride
=
1
,
pool_type
=
AvgPooling
())
return
tmp
return
pool
datadim
=
3
*
32
*
32
datadim
=
3
*
32
*
32
classdim
=
10
classdim
=
10
data
=
data_layer
(
name
=
'image'
,
size
=
datadim
)
data
=
data_layer
(
name
=
'image'
,
size
=
datadim
)
net
=
resnet_cifar10
(
data
,
depth
=
56
)
net
=
resnet_cifar10
(
data
,
depth
=
32
)
out
=
fc_layer
(
input
=
net
,
size
=
10
,
act
=
SoftmaxActivation
())
out
=
fc_layer
(
input
=
net
,
size
=
10
,
act
=
SoftmaxActivation
())
if
not
is_predict
:
if
not
is_predict
:
lbl
=
data_layer
(
name
=
"label"
,
size
=
classdim
)
lbl
=
data_layer
(
name
=
"label"
,
size
=
classdim
)
...
...
image_classification/models/vgg.py
浏览文件 @
8453aff4
...
@@ -47,18 +47,18 @@ def vgg_bn_drop(input):
...
@@ -47,18 +47,18 @@ def vgg_bn_drop(input):
conv_batchnorm_drop_rate
=
dropouts
,
conv_batchnorm_drop_rate
=
dropouts
,
pool_type
=
MaxPooling
())
pool_type
=
MaxPooling
())
tmp
=
conv_block
(
input
,
64
,
2
,
[
0.3
,
0
],
3
)
conv1
=
conv_block
(
input
,
64
,
2
,
[
0.3
,
0
],
3
)
tmp
=
conv_block
(
tmp
,
128
,
2
,
[
0.4
,
0
])
conv2
=
conv_block
(
conv1
,
128
,
2
,
[
0.4
,
0
])
tmp
=
conv_block
(
tmp
,
256
,
3
,
[
0.4
,
0.4
,
0
])
conv3
=
conv_block
(
conv2
,
256
,
3
,
[
0.4
,
0.4
,
0
])
tmp
=
conv_block
(
tmp
,
512
,
3
,
[
0.4
,
0.4
,
0
])
conv4
=
conv_block
(
conv3
,
512
,
3
,
[
0.4
,
0.4
,
0
])
tmp
=
conv_block
(
tmp
,
512
,
3
,
[
0.4
,
0.4
,
0
])
conv5
=
conv_block
(
conv4
,
512
,
3
,
[
0.4
,
0.4
,
0
])
tmp
=
dropout_layer
(
input
=
tmp
,
dropout_rate
=
0.5
)
drop
=
dropout_layer
(
input
=
conv5
,
dropout_rate
=
0.5
)
tmp
=
fc_layer
(
input
=
tm
p
,
size
=
512
,
act
=
LinearActivation
())
fc1
=
fc_layer
(
input
=
dro
p
,
size
=
512
,
act
=
LinearActivation
())
tmp
=
batch_norm_layer
(
bn
=
batch_norm_layer
(
input
=
tmp
,
act
=
ReluActivation
(),
layer_attr
=
ExtraAttr
(
drop_rate
=
0.5
))
input
=
fc1
,
act
=
ReluActivation
(),
layer_attr
=
ExtraAttr
(
drop_rate
=
0.5
))
tmp
=
fc_layer
(
input
=
tmp
,
size
=
512
,
act
=
LinearActivation
())
fc2
=
fc_layer
(
input
=
bn
,
size
=
512
,
act
=
LinearActivation
())
return
tmp
return
fc2
datadim
=
3
*
32
*
32
datadim
=
3
*
32
*
32
...
...
image_classification/train.sh
浏览文件 @
8453aff4
...
@@ -25,5 +25,5 @@ paddle train \
...
@@ -25,5 +25,5 @@ paddle train \
--trainer_count
=
4
\
--trainer_count
=
4
\
--log_period
=
100
\
--log_period
=
100
\
--num_passes
=
300
\
--num_passes
=
300
\
--save_dir
=
$output
--save_dir
=
$output
\
2>&1 |
tee
$log
2>&1 |
tee
$log
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}