Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
book
提交
65b20788
B
book
项目概览
PaddlePaddle
/
book
通知
17
Star
4
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
40
列表
看板
标记
里程碑
合并请求
37
Wiki
5
Wiki
分析
仓库
DevOps
项目成员
Pages
B
book
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
40
Issue
40
列表
看板
标记
里程碑
合并请求
37
合并请求
37
Pages
分析
分析
仓库分析
DevOps
Wiki
5
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
65b20788
编写于
1月 02, 2017
作者:
D
dangqingqing
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
finish README.md and update code
上级
3088707a
变更
13
展开全部
显示空白变更内容
内联
并排
Showing
13 changed file
with
572 addition
and
135 deletion
+572
-135
image_classification/README.md
image_classification/README.md
+261
-63
image_classification/classify.py
image_classification/classify.py
+223
-0
image_classification/dataprovider.py
image_classification/dataprovider.py
+0
-1
image_classification/extract.sh
image_classification/extract.sh
+17
-0
image_classification/image/dog.png
image_classification/image/dog.png
+0
-0
image_classification/image/dog_cat.png
image_classification/image/dog_cat.png
+0
-0
image_classification/image/fea_conv0.png
image_classification/image/fea_conv0.png
+0
-0
image_classification/image/inception.png
image_classification/image/inception.png
+0
-0
image_classification/image/resnet.png
image_classification/image/resnet.png
+0
-0
image_classification/models/resnet.py
image_classification/models/resnet.py
+35
-34
image_classification/models/vgg.py
image_classification/models/vgg.py
+31
-29
image_classification/predict.sh
image_classification/predict.sh
+1
-4
image_classification/train.sh
image_classification/train.sh
+4
-4
未找到文件。
image_classification/README.md
浏览文件 @
65b20788
此差异已折叠。
点击以展开。
image_classification/
prediction
.py
→
image_classification/
classify
.py
100755 → 100644
浏览文件 @
65b20788
# Copyright (c) 2016
PaddlePaddle Authors
. All Rights Reserved
# Copyright (c) 2016
Baidu, Inc
. All Rights Reserved
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
...
...
@@ -12,44 +12,54 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import
os
,
sys
import
os
,
sys
import
cPickle
import
numpy
as
np
import
logging
from
PIL
import
Image
from
optparse
import
OptionParser
import
paddle.utils.image_util
as
image_util
from
py_paddle
import
swig_paddle
,
DataProviderConverter
from
paddle.trainer.PyDataProvider2
import
dense_vector
from
paddle.trainer.config_parser
import
parse_config
logging
.
basicConfig
(
format
=
'[%(levelname)s %(asctime)s %(filename)s:%(lineno)s] %(message)s'
)
import
logging
logging
.
basicConfig
(
format
=
'[%(levelname)s %(asctime)s %(filename)s:%(lineno)s] %(message)s'
)
logging
.
getLogger
().
setLevel
(
logging
.
INFO
)
def
vis_square
(
data
,
fname
):
import
matplotlib
matplotlib
.
use
(
'Agg'
)
import
matplotlib.pyplot
as
plt
"""Take an array of shape (n, height, width) or (n, height, width, 3)
and visualize each (height, width) thing in a grid of size approx. sqrt(n) by sqrt(n)"""
# normalize data for display
data
=
(
data
-
data
.
min
())
/
(
data
.
max
()
-
data
.
min
())
# force the number of filters to be square
n
=
int
(
np
.
ceil
(
np
.
sqrt
(
data
.
shape
[
0
])))
padding
=
(((
0
,
n
**
2
-
data
.
shape
[
0
]),
(
0
,
1
),
(
0
,
1
))
# add some space between filters
+
((
0
,
0
),)
*
(
data
.
ndim
-
3
))
# don't pad the last dimension (if there is one)
data
=
np
.
pad
(
data
,
padding
,
mode
=
'constant'
,
constant_values
=
1
)
# pad with ones (white)
# tile the filters into an image
data
=
data
.
reshape
((
n
,
n
)
+
data
.
shape
[
1
:]).
transpose
((
0
,
2
,
1
,
3
)
+
tuple
(
range
(
4
,
data
.
ndim
+
1
)))
data
=
data
.
reshape
((
n
*
data
.
shape
[
1
],
n
*
data
.
shape
[
3
])
+
data
.
shape
[
4
:])
plt
.
imshow
(
data
,
cmap
=
'gray'
)
plt
.
savefig
(
fname
)
plt
.
axis
(
'off'
)
class
ImageClassifier
():
def
__init__
(
self
,
train_conf
,
use_gpu
=
True
,
resize_dim
,
crop_dim
,
model_dir
=
None
,
resize_dim
=
None
,
crop_dim
=
None
,
use_gpu
=
True
,
mean_file
=
None
,
oversample
=
False
,
is_color
=
True
):
"""
train_conf: network configure.
model_dir: string, directory of model.
resize_dim: int, resized image size.
crop_dim: int, crop size.
mean_file: string, image mean file.
oversample: bool, oversample means multiple crops, namely five
patches (the four corner patches and the center
patch) as well as their horizontal reflections,
ten crops in all.
"""
self
.
train_conf
=
train_conf
self
.
model_dir
=
model_dir
if
model_dir
is
None
:
...
...
@@ -60,47 +70,56 @@ class ImageClassifier():
self
.
oversample
=
oversample
self
.
is_color
=
is_color
self
.
transformer
=
image_util
.
ImageTransformer
(
is_color
=
is_color
)
self
.
transformer
.
set_transpose
((
2
,
0
,
1
))
self
.
transformer
=
image_util
.
ImageTransformer
(
is_color
=
is_color
)
self
.
transformer
.
set_transpose
((
2
,
0
,
1
))
self
.
transformer
.
set_channel_swap
((
2
,
1
,
0
))
self
.
mean_file
=
mean_file
mean
=
np
.
load
(
self
.
mean_file
)[
'data_mean'
]
if
self
.
mean_file
is
not
None
:
mean
=
np
.
load
(
self
.
mean_file
)[
'mean'
]
mean
=
mean
.
reshape
(
3
,
self
.
crop_dims
[
0
],
self
.
crop_dims
[
1
])
self
.
transformer
.
set_mean
(
mean
)
# mean pixel
gpu
=
1
if
use_gpu
else
0
conf_args
=
"is_test=1,use_gpu=%d,is_predict=1"
%
(
gpu
)
else
:
# if you use three mean value, set like:
# this three mean value is calculated from ImageNet.
self
.
transformer
.
set_mean
(
np
.
array
([
103.939
,
116.779
,
123.68
]))
conf_args
=
"use_gpu=%d,is_predict=1"
%
(
int
(
use_gpu
))
conf
=
parse_config
(
train_conf
,
conf_args
)
swig_paddle
.
initPaddle
(
"--use_gpu=%d"
%
(
gpu
))
self
.
network
=
swig_paddle
.
GradientMachine
.
createFromConfigProto
(
conf
.
model_config
)
swig_paddle
.
initPaddle
(
"--use_gpu=%d"
%
(
int
(
use_gpu
)))
self
.
network
=
swig_paddle
.
GradientMachine
.
createFromConfigProto
(
conf
.
model_config
)
assert
isinstance
(
self
.
network
,
swig_paddle
.
GradientMachine
)
self
.
network
.
loadParameters
(
self
.
model_dir
)
d
ata_size
=
3
*
self
.
crop_dims
[
0
]
*
self
.
crop_dims
[
1
]
slots
=
[
dense_vector
(
d
ata_size
)]
d
im
=
3
*
self
.
crop_dims
[
0
]
*
self
.
crop_dims
[
1
]
slots
=
[
dense_vector
(
d
im
)]
self
.
converter
=
DataProviderConverter
(
slots
)
def
get_data
(
self
,
img_path
):
"""
1. load image from img_path.
2. resize or oversampling.
3. transformer data: transpose, sub mean.
3. transformer data: transpose,
channel swap,
sub mean.
return K x H x W ndarray.
img_path: image path.
"""
image
=
image_util
.
load_image
(
img_path
,
self
.
is_color
)
# Another way to extract oversampled features is that
# cropping and averaging from large feature map which is
# calculated by large size of image.
# This way reduces the computation.
if
self
.
oversample
:
# image_util.resize_image: short side is self.resize_dim
image
=
image_util
.
resize_image
(
image
,
self
.
resize_dim
)
image
=
np
.
array
(
image
)
input
=
np
.
zeros
(
(
1
,
image
.
shape
[
0
],
image
.
shape
[
1
],
3
),
dtype
=
np
.
float32
)
input
=
np
.
zeros
(
(
1
,
image
.
shape
[
0
],
image
.
shape
[
1
],
3
),
dtype
=
np
.
float32
)
input
[
0
]
=
image
.
astype
(
np
.
float32
)
input
=
image_util
.
oversample
(
input
,
self
.
crop_dims
)
else
:
image
=
image
.
resize
(
self
.
crop_dims
,
Image
.
ANTIALIAS
)
input
=
np
.
zeros
(
(
1
,
self
.
crop_dims
[
0
],
self
.
crop_dims
[
1
],
3
),
dtype
=
np
.
float32
)
input
=
np
.
zeros
(
(
1
,
self
.
crop_dims
[
0
],
self
.
crop_dims
[
1
],
3
),
dtype
=
np
.
float32
)
input
[
0
]
=
np
.
array
(
image
).
astype
(
np
.
float32
)
data_in
=
[]
...
...
@@ -114,46 +133,91 @@ class ImageClassifier():
return
self
.
network
.
forwardTest
(
in_arg
)
def
forward
(
self
,
data
,
output_layer
):
"""
input_data: py_paddle input data.
output_layer: specify the name of probability, namely the layer with
softmax activation.
return: the predicting probability of each label.
"""
input
=
self
.
converter
(
data
)
self
.
network
.
forwardTest
(
input
)
output
=
self
.
network
.
getLayerOutputs
(
output_layer
)
res
=
{}
if
isinstance
(
output_layer
,
basestring
):
output_layer
=
[
output_layer
]
for
name
in
output_layer
:
# For oversampling, average predictions across crops.
# If not, the shape of output[name]: (1, class_number),
# the mean is also applicable.
return
output
[
output_layer
].
mean
(
0
)
def
predict
(
self
,
image
=
None
,
output_layer
=
None
):
assert
isinstance
(
image
,
basestring
)
assert
isinstance
(
output_layer
,
basestring
)
data
=
self
.
get_data
(
image
)
prob
=
self
.
forward
(
data
,
output_layer
)
lab
=
np
.
argsort
(
-
prob
)
logging
.
info
(
"Label of %s is: %d"
,
image
,
lab
[
0
])
res
[
name
]
=
output
[
name
].
mean
(
0
)
return
res
def
option_parser
():
usage
=
"%prog -c config -i data_list -w model_dir [options]"
parser
=
OptionParser
(
usage
=
"usage: %s"
%
usage
)
parser
.
add_option
(
"--job"
,
action
=
"store"
,
dest
=
"job_type"
,
choices
=
[
'predict'
,
'extract'
,],
default
=
'predict'
,
help
=
"The job type.
\
predict: predicting,
\
extract: extract features"
)
parser
.
add_option
(
"--conf"
,
action
=
"store"
,
dest
=
"train_conf"
,
default
=
'models/vgg.py'
,
help
=
"network config"
)
parser
.
add_option
(
"--data"
,
action
=
"store"
,
dest
=
"data_file"
,
default
=
'image/dog.png'
,
help
=
"image list"
)
parser
.
add_option
(
"--model"
,
action
=
"store"
,
dest
=
"model_path"
,
default
=
None
,
help
=
"model path"
)
parser
.
add_option
(
"-c"
,
dest
=
"cpu_gpu"
,
action
=
"store_false"
,
help
=
"Use cpu mode."
)
parser
.
add_option
(
"-g"
,
dest
=
"cpu_gpu"
,
default
=
True
,
action
=
"store_true"
,
help
=
"Use gpu mode."
)
parser
.
add_option
(
"--mean"
,
action
=
"store"
,
dest
=
"mean"
,
default
=
'data/mean.meta'
,
help
=
"The mean file."
)
parser
.
add_option
(
"--multi_crop"
,
action
=
"store_true"
,
dest
=
"multi_crop"
,
default
=
False
,
help
=
"Wether to use multiple crops on image."
)
return
parser
.
parse_args
()
def
main
():
options
,
args
=
option_parser
()
mean
=
'data/mean.meta'
if
not
options
.
mean
else
options
.
mean
conf
=
'models/vgg.py'
if
not
options
.
train_conf
else
options
.
train_conf
obj
=
ImageClassifier
(
conf
,
32
,
32
,
options
.
model_path
,
use_gpu
=
options
.
cpu_gpu
,
mean_file
=
mean
,
oversample
=
options
.
multi_crop
)
image_path
=
options
.
data_file
if
options
.
job_type
==
'predict'
:
output_layer
=
'__fc_layer_2__'
data
=
obj
.
get_data
(
image_path
)
prob
=
obj
.
forward
(
data
,
output_layer
)
lab
=
np
.
argsort
(
-
prob
[
output_layer
])
logging
.
info
(
"Label of %s is: %d"
,
image_path
,
lab
[
0
])
elif
options
.
job_type
==
"extract"
:
output_layer
=
'__conv_0__'
data
=
obj
.
get_data
(
options
.
data_file
)
features
=
obj
.
forward
(
data
,
output_layer
)
dshape
=
(
64
,
32
,
32
)
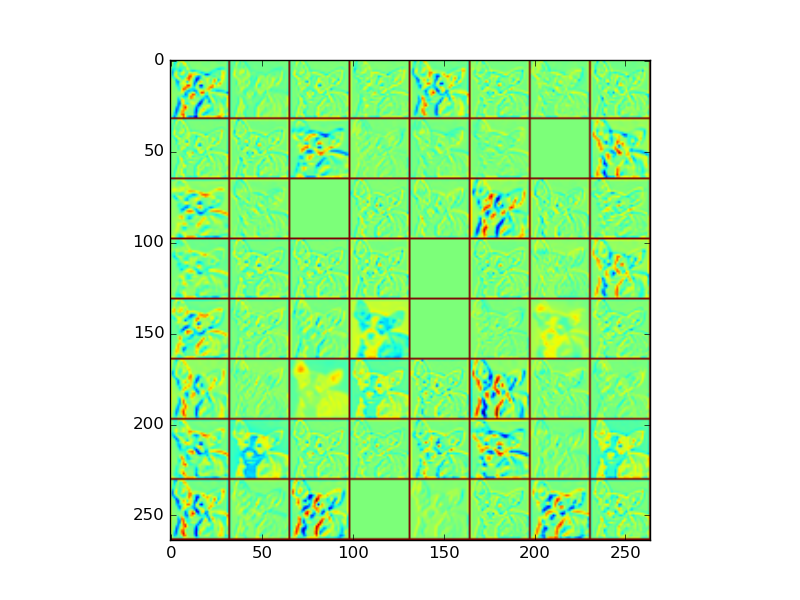
fea
=
features
[
output_layer
].
reshape
(
dshape
)
vis_square
(
fea
,
'fea_conv0.png'
)
if
__name__
==
'__main__'
:
image_size
=
32
crop_size
=
32
multi_crop
=
True
config
=
"vgg_16_cifar.py"
output_layer
=
"__fc_layer_1__"
mean_path
=
"data/batches.meta"
model_path
=
sys
.
argv
[
1
]
image
=
sys
.
argv
[
2
]
use_gpu
=
bool
(
int
(
sys
.
argv
[
3
]))
obj
=
ImageClassifier
(
train_conf
=
config
,
model_dir
=
model_path
,
resize_dim
=
image_size
,
crop_dim
=
crop_size
,
mean_file
=
mean_path
,
use_gpu
=
use_gpu
,
oversample
=
multi_crop
)
obj
.
predict
(
image
,
output_layer
)
main
()
image_classification/dataprovider.py
浏览文件 @
65b20788
...
...
@@ -14,7 +14,6 @@
import
numpy
as
np
import
cPickle
from
paddle.trainer.PyDataProvider2
import
*
def
initializer
(
settings
,
mean_path
,
is_train
,
**
kwargs
):
...
...
image_classification/extract.sh
0 → 100755
浏览文件 @
65b20788
#!/bin/bash
# Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
set
-e
python classify.py
--job
=
extract
--model
=
output/pass-00299
--data
=
image/dog.png
# -c
image_classification/image/dog.png
0 → 100644
浏览文件 @
65b20788
2.7 KB
image_classification/image/
image_classification
.png
→
image_classification/image/
dog_cat
.png
浏览文件 @
65b20788
文件已移动
image_classification/image/fea_conv0.png
0 → 100644
浏览文件 @
65b20788
369.0 KB
image_classification/image/inception.png
0 → 100644
浏览文件 @
65b20788
130.0 KB
image_classification/image/resnet.png
查看替换文件 @
3088707a
浏览文件 @
65b20788
343.4 KB
|
W:
|
H:
346.4 KB
|
W:
|
H:
2-up
Swipe
Onion skin
image_classification/models/resnet.py
浏览文件 @
65b20788
...
...
@@ -14,13 +14,33 @@
from
paddle.trainer_config_helpers
import
*
is_predict
=
get_config_arg
(
"is_predict"
,
bool
,
False
)
if
not
is_predict
:
args
=
{
'meta'
:
'data/mean.meta'
}
define_py_data_sources2
(
train_list
=
'data/train.list'
,
test_list
=
'data/test.list'
,
module
=
'dataprovider'
,
obj
=
'process'
,
args
=
args
)
settings
(
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
100
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.0001
*
128
))
def
conv_bn_layer
(
input
,
ch_out
,
filter_size
,
stride
,
padding
,
ch_in
=
None
,
active_type
=
ReluActivation
()
):
active_type
=
ReluActivation
()
,
ch_in
=
None
):
tmp
=
img_conv_layer
(
input
=
input
,
filter_size
=
filter_size
,
...
...
@@ -35,16 +55,16 @@ def conv_bn_layer(input,
def
shortcut
(
ipt
,
n_in
,
n_out
,
stride
):
if
n_in
!=
n_out
:
return
conv_bn_layer
(
ipt
,
n_out
,
1
,
stride
=
stride
,
LinearActivation
())
return
conv_bn_layer
(
ipt
,
n_out
,
1
,
stride
,
0
,
LinearActivation
())
else
:
return
ipt
def
basicblock
(
ipt
,
ch_out
,
stride
):
ch_in
=
ipt
.
num_filter
ch_in
=
ipt
.
num_filter
s
tmp
=
conv_bn_layer
(
ipt
,
ch_out
,
3
,
stride
,
1
)
tmp
=
conv_bn_layer
(
tmp
,
ch_out
,
3
,
1
,
1
,
LinearActivation
())
short
=
shortcut
(
ipt
,
ch_in
,
ch_out
,
stride
)
return
addto_layer
(
input
=
[
i
npu
t
,
short
],
act
=
ReluActivation
())
return
addto_layer
(
input
=
[
i
p
t
,
short
],
act
=
ReluActivation
())
def
bottleneck
(
ipt
,
ch_out
,
stride
):
ch_in
=
ipt
.
num_filter
...
...
@@ -52,10 +72,10 @@ def bottleneck(ipt, ch_out, stride):
tmp
=
conv_bn_layer
(
tmp
,
ch_out
,
3
,
1
,
1
)
tmp
=
conv_bn_layer
(
tmp
,
ch_out
*
4
,
1
,
1
,
0
,
LinearActivation
())
short
=
shortcut
(
ipt
,
ch_in
,
ch_out
,
stride
)
return
addto_layer
(
input
=
[
i
npu
t
,
short
],
act
=
ReluActivation
())
return
addto_layer
(
input
=
[
i
p
t
,
short
],
act
=
ReluActivation
())
def
layer_warp
(
block_func
,
ipt
,
features
,
count
,
stride
):
tmp
=
block_func
(
tmp
,
features
,
stride
)
tmp
=
block_func
(
ipt
,
features
,
stride
)
for
i
in
range
(
1
,
count
):
tmp
=
block_func
(
tmp
,
features
,
1
)
return
tmp
...
...
@@ -96,42 +116,23 @@ def resnet_cifar10(ipt, depth=56):
filter_size
=
3
,
stride
=
1
,
padding
=
1
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
16
,
n
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
16
,
n
,
1
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
32
,
n
,
2
)
tmp
=
layer_warp
(
basicblock
,
tmp
,
64
,
n
,
2
)
tmp
=
img_pool_layer
(
input
=
tmp
,
pool_size
=
8
,
stride
=
1
,
pool_type
=
AvgPooling
())
tmp
=
fc_layer
(
input
=
tmp
,
size
=
10
,
act
=
SoftmaxActivation
())
return
tmp
is_predict
=
get_config_arg
(
"is_predict"
,
bool
,
False
)
if
not
is_predict
:
args
=
{
'meta'
:
'data/mean.meta'
}
define_py_data_sources2
(
train_list
=
'data/train.list'
,
test_list
=
'data/test.list'
,
module
=
'dataprovider'
,
obj
=
'process'
,
args
=
args
)
settings
(
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
100
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.0005
*
128
))
data_size
=
3
*
32
*
32
class_num
=
10
data
=
data_layer
(
name
=
'image'
,
size
=
data_size
)
out
=
resnet_cifar10
(
data
,
depth
=
50
)
datadim
=
3
*
32
*
32
classdim
=
10
data
=
data_layer
(
name
=
'image'
,
size
=
datadim
)
net
=
resnet_cifar10
(
data
,
depth
=
56
)
out
=
fc_layer
(
input
=
net
,
size
=
10
,
act
=
SoftmaxActivation
())
if
not
is_predict
:
lbl
=
data_layer
(
name
=
"label"
,
size
=
class
_nu
m
)
lbl
=
data_layer
(
name
=
"label"
,
size
=
class
di
m
)
outputs
(
classification_cost
(
input
=
out
,
label
=
lbl
))
else
:
outputs
(
out
)
image_classification/models/vgg.py
浏览文件 @
65b20788
...
...
@@ -14,11 +14,30 @@
from
paddle.trainer_config_helpers
import
*
def
vgg_bn_drop
(
input
,
num_channels
):
def
conv_block
(
ipt
,
num_filter
,
groups
,
dropouts
,
num_channels_
=
None
):
is_predict
=
get_config_arg
(
"is_predict"
,
bool
,
False
)
if
not
is_predict
:
define_py_data_sources2
(
train_list
=
'data/train.list'
,
test_list
=
'data/test.list'
,
module
=
'dataprovider'
,
obj
=
'process'
,
args
=
{
'mean_path'
:
'data/mean.meta'
})
settings
(
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
100
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.0005
*
128
),)
def
vgg_bn_drop
(
input
):
def
conv_block
(
ipt
,
num_filter
,
groups
,
dropouts
,
num_channels
=
None
):
return
img_conv_group
(
input
=
ipt
,
num_channels
=
num_channels
_
,
num_channels
=
num_channels
,
pool_size
=
2
,
pool_stride
=
2
,
conv_num_filter
=
[
num_filter
]
*
groups
,
...
...
@@ -28,7 +47,7 @@ def vgg_bn_drop(input, num_channels):
conv_batchnorm_drop_rate
=
dropouts
,
pool_type
=
MaxPooling
())
tmp
=
conv_block
(
input
,
64
,
2
,
[
0.3
,
0
],
num_channels
)
tmp
=
conv_block
(
input
,
64
,
2
,
[
0.3
,
0
],
3
)
tmp
=
conv_block
(
tmp
,
128
,
2
,
[
0.4
,
0
])
tmp
=
conv_block
(
tmp
,
256
,
3
,
[
0.4
,
0.4
,
0
])
tmp
=
conv_block
(
tmp
,
512
,
3
,
[
0.4
,
0.4
,
0
])
...
...
@@ -46,33 +65,16 @@ def vgg_bn_drop(input, num_channels):
input
=
tmp
,
size
=
512
,
act
=
LinearActivation
())
tmp
=
fc_layer
(
input
=
tmp
,
size
=
10
,
act
=
SoftmaxActivation
())
return
tmp
is_predict
=
get_config_arg
(
"is_predict"
,
bool
,
False
)
if
not
is_predict
:
define_py_data_sources2
(
train_list
=
'data/train.list'
,
test_list
=
'data/test.list'
,
module
=
'dataprovider'
,
obj
=
'process'
,
args
=
{
'mean_path'
:
'data/mean.meta'
})
settings
(
batch_size
=
128
,
learning_rate
=
0.1
/
128.0
,
learning_rate_decay_a
=
0.1
,
learning_rate_decay_b
=
50000
*
100
,
learning_rate_schedule
=
'discexp'
,
learning_method
=
MomentumOptimizer
(
0.9
),
regularization
=
L2Regularization
(
0.0005
*
128
),)
data_size
=
3
*
32
*
32
class_num
=
10
data
=
data_layer
(
name
=
'image'
,
size
=
data_size
)
out
=
vgg_bn_drop
(
data
,
3
)
datadim
=
3
*
32
*
32
classdim
=
10
data
=
data_layer
(
name
=
'image'
,
size
=
datadim
)
net
=
vgg_bn_drop
(
data
)
out
=
fc_layer
(
input
=
net
,
size
=
classdim
,
act
=
SoftmaxActivation
())
if
not
is_predict
:
lbl
=
data_layer
(
name
=
"label"
,
size
=
class_num
)
outputs
(
classification_cost
(
input
=
out
,
label
=
lbl
))
lbl
=
data_layer
(
name
=
"label"
,
size
=
classdim
)
cost
=
classification_cost
(
input
=
out
,
label
=
lbl
)
outputs
(
cost
)
else
:
outputs
(
out
)
image_classification/predict.sh
浏览文件 @
65b20788
...
...
@@ -14,7 +14,4 @@
# limitations under the License.
set
-e
model
=
output/pass-00299/
image
=
data/cifar-out/test/airplane/seaplane_s_000978.png
use_gpu
=
1
python prediction.py
$model
$image
$use_gpu
python classify.py
--job
=
predict
--model
=
output/pass-00299
--data
=
image/dog.png
# -c
image_classification/train.sh
浏览文件 @
65b20788
...
...
@@ -14,9 +14,9 @@
# limitations under the License.
set
-e
#
config=models/resnet.py
config
=
models/vgg.py
output
=
./
output
config
=
models/resnet.py
#
config=models/vgg.py
output
=
output
log
=
train.log
paddle train
\
...
...
@@ -26,4 +26,4 @@ paddle train \
--log_period
=
100
\
--num_passes
=
300
\
--save_dir
=
$output
2>&1 |
tee
$log
#
2>&1 | tee $log
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}