Merge branch 'develop' of https://github.com/PaddlePaddle/book into feature/remove_lambda
Showing
.dockerignore
0 → 100644
.gitmodules
0 → 100644
.tools/build_docker.sh
0 → 100755
.tools/cache_dataset.py
0 → 100755
.tools/notedown.sh
0 → 100644
.tools/templates/index.html.json
0 → 100644
.tools/templates/index.html.tmpl
0 → 100644
.tools/theme/PP_w.png
0 → 100644
{kind=link}

3.1 KB
01.fit_a_line/README.md
0 → 100644
01.fit_a_line/fit_a_line.tar
0 → 100644
文件已添加
{kind=link}
{kind=link}
01.fit_a_line/image/ranges.png
0 → 100644
{kind=link}
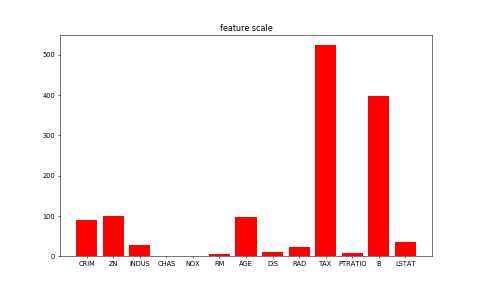
6.5 KB
{kind=link}
{kind=link}
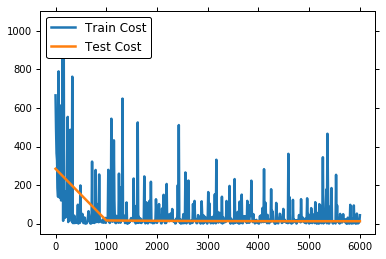
17.5 KB
01.fit_a_line/index.html
0 → 100644
01.fit_a_line/infer.py
0 → 100644
01.fit_a_line/train.py
0 → 100644
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
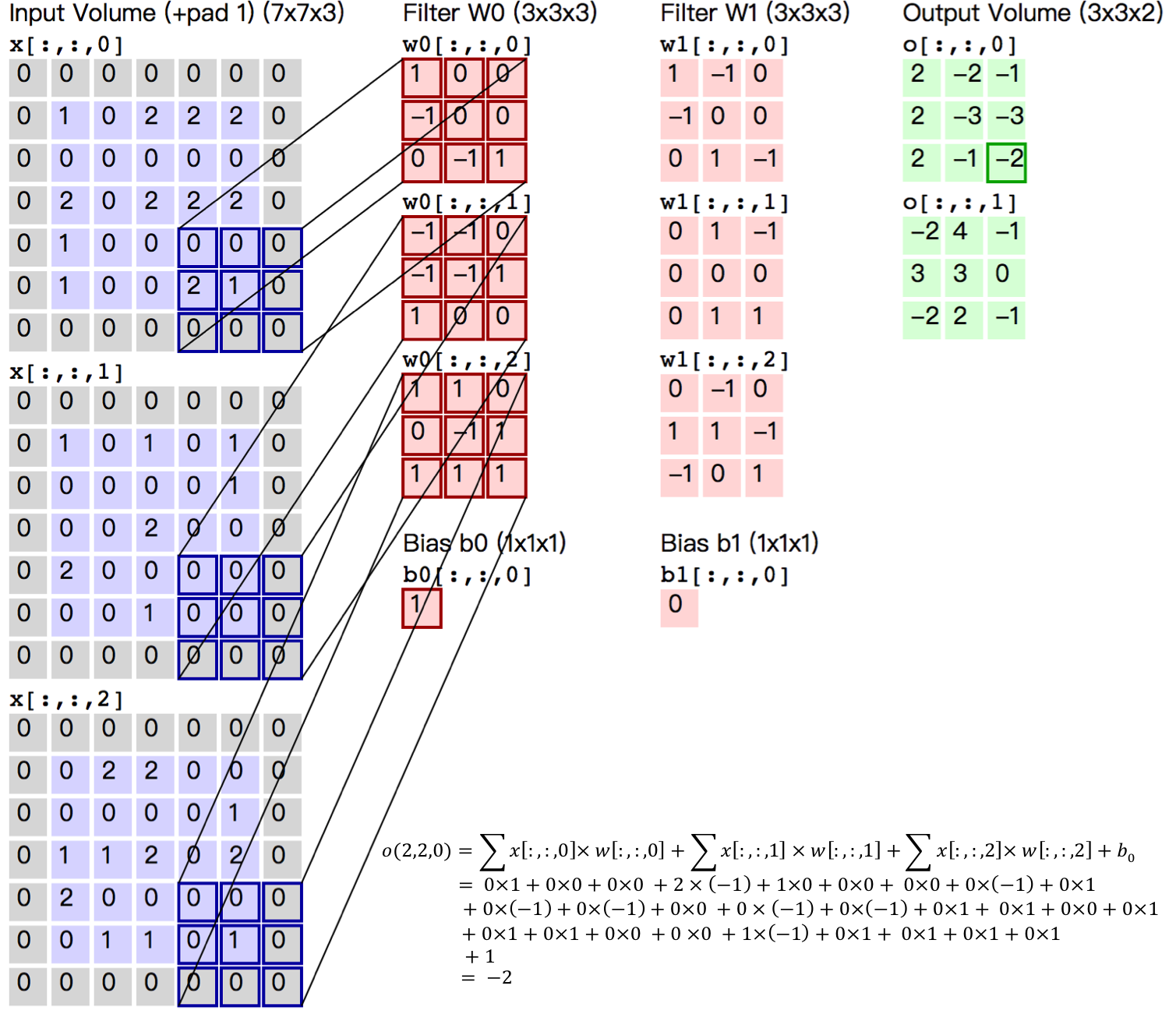
571.4 KB
{kind=link}

7.2 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
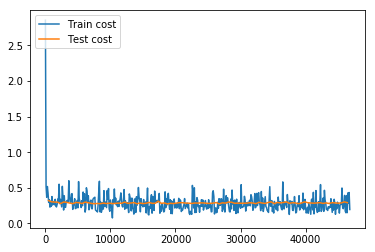
17.5 KB
02.recognize_digits/train.py
0 → 100644
03.image_classification/README.md
0 → 100644
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
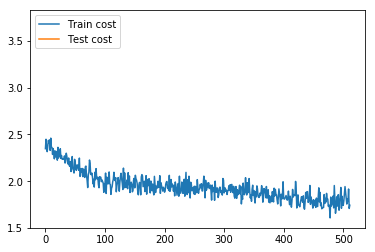
14.7 KB
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
05.recommender_system/.gitignore
0 → 100644
此差异已折叠。
05.recommender_system/README.md
0 → 100644
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
05.recommender_system/train.py
0 → 100644
此差异已折叠。
06.understand_sentiment/README.md
0 → 100644
此差异已折叠。
{kind=link}
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
07.label_semantic_roles/README.md
0 → 100644
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
{kind=link}
{kind=link}
文件已移动
08.machine_translation/train.py
0 → 100644
此差异已折叠。
README.cn.md
0 → 100644
此差异已折叠。
此差异已折叠。
build.sh
已删除
100755 → 0
此差异已折叠。
fit_a_line/README.en.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
fit_a_line/dataprovider.py
已删除
100644 → 0
此差异已折叠。
fit_a_line/image/ranges.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
fit_a_line/index.en.html
已删除
100644 → 0
此差异已折叠。
fit_a_line/predict.py
已删除
100644 → 0
此差异已折叠。
fit_a_line/train.sh
已删除
100755 → 0
此差异已折叠。
fit_a_line/trainer_config.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
index.cn.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
label_semantic_roles/test.sh
已删除
100755 → 0
此差异已折叠。
label_semantic_roles/train.sh
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
machine_translation/gen.sh
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
machine_translation/train.sh
已删除
100755 → 0
此差异已折叠。
mnist-client/.eslintrc
0 → 100644
此差异已折叠。
mnist-client/.gitignore
0 → 100644
此差异已折叠。
mnist-client/Dockerfile
0 → 100644
此差异已折叠。
mnist-client/Procfile
0 → 100644
此差异已折叠。
mnist-client/README.md
0 → 100644
此差异已折叠。
mnist-client/app.json
0 → 100644
此差异已折叠。
mnist-client/gulpfile.js
0 → 100644
此差异已折叠。
mnist-client/main.py
0 → 100644
此差异已折叠。
mnist-client/package.json
0 → 100644
此差异已折叠。
mnist-client/requirements.txt
0 → 100644
此差异已折叠。
mnist-client/runtime.txt
0 → 100644
此差异已折叠。
mnist-client/src/js/main.js
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
mnist-client/templates/index.html
0 → 100644
此差异已折叠。
pending/skip_thought/index.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
recognize_digits/evaluate.py
已删除
100755 → 0
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
recognize_digits/load_data.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
recognize_digits/plot_cost.py
已删除
100644 → 0
此差异已折叠。
recognize_digits/predict.py
已删除
100644 → 0
此差异已折叠。
recognize_digits/train.py
已删除
100644 → 0
此差异已折叠。
recognize_digits/train.sh
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
recommender_system/train.sh
已删除
100755 → 0
此差异已折叠。
此差异已折叠。
serve/.gitignore
0 → 100644
此差异已折叠。
serve/Dockerfile
0 → 100644
此差异已折叠。
serve/Dockerfile.gpu
0 → 100644
此差异已折叠。
serve/README.md
0 → 100644
此差异已折叠。
serve/main.py
0 → 100644
此差异已折叠。
serve/requirements.txt
0 → 100644
此差异已折叠。
skip_thought/index.html
已删除
100644 → 0
此差异已折叠。
speech_recognition/index.html
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
understand_sentiment/test.sh
已删除
100755 → 0
此差异已折叠。
understand_sentiment/train.sh
已删除
100755 → 0
此差异已折叠。
此差异已折叠。