word2vec_initial
Showing
word2vec/Ngram.py
0 → 100644
word2vec/caldis.py
0 → 100644
word2vec/data/getdata.sh
0 → 100644
word2vec/dataprovider.py
0 → 100644
word2vec/image/2d_similarity.png
0 → 100644
{kind=link}
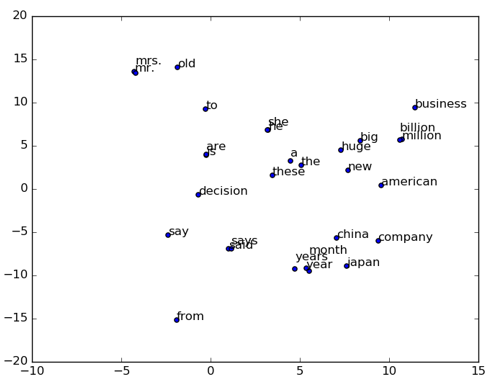
23.6 KB
word2vec/image/ngram.png
0 → 100644
{kind=link}
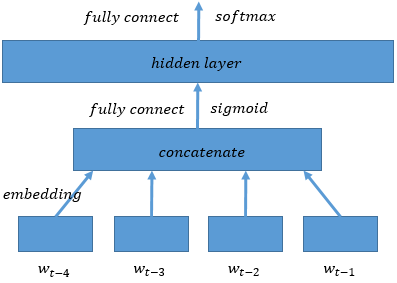
9.1 KB
word2vec/paraconvert.py
0 → 100755
word2vec/train.sh
0 → 100644