词向量模型可以是概率模型、共生矩阵(co-occurrence matrix)模型或神经元网络模型。在用神经网络求词向量之前,传统做法是统计一个词语的共生矩阵$X$。$X$是一个`|V|*|V|`大小的矩阵,$X_{ij}$表示在所有语料中,词汇表`V`(vocabulary)中第i个词和第j个词同时出现的词数,`|V|`为词汇表的大小。对$X$做矩阵分解(如奇异值分解,Singular Value Decomposition \[[5](#参考文献)\]),得到的$U$即视为所有词的词向量:
词向量模型可以是概率模型、共生矩阵(co-occurrence matrix)模型或神经元网络模型。在用神经网络求词向量之前,传统做法是统计一个词语的共生矩阵$X$。$X$是一个$|V| \times |V|$ 大小的矩阵,$X_{ij}$表示在所有语料中,词汇表`V`(vocabulary)中第i个词和第j个词同时出现的词数,$|V|$为词汇表的大小。对$X$做矩阵分解(如奇异值分解,Singular Value Decomposition \[[5](#参考文献)\]),得到的$U$即视为所有词的词向量:
这样的模型可以应用于很多领域,如机器翻译、语音识别、信息检索、词性标注、手写识别等,它们都希望能得到一个连续序列的概率。 以信息检索为例,当你在搜索“how long is a football bame”时(bame是一个医学名词),搜索引擎会提示你是否希望搜索"how long is a football game", 这是因为根据语言模型计算出“how long is a football bame”的概率很低,而与bame近似的,可能引起错误的词中,game会使该句生成的概率最大。
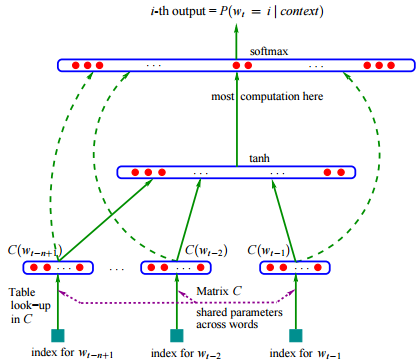
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models \[[1](#参考文献)\] 中介绍如何学习一个神经元网络表示的词向量模型。文中的神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。
近年来最有名的神经元网络 word embedding model 恐怕是 Tomas Mikolov 在Google 研发的 wordvec\[[3](#参考文献)\]。其中介绍了两个模型,Continuous Bag-of-Words model和Skip-Gram model,这两个网络很浅很简单,但训练效果非常好。和N-gram neural model 类似,这两个模型同样利用了上下文信息。 CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
{kind=link}