|剧情四星。但是圆镜视角加上婺源的风景整个非常有中国写意山水画的感觉,看得实在太舒服了。。难怪作为今年TIFF special presentation的开幕电影。范爷美爆,再往上加一星。|正面|
<palign="center">表格 1 电影评论情感分析</p>
<br/>  实际上,在自然语言处理中,情感分析属于典型的**文本分类**问题,即,把需要进行情感分析的文本划分为其所属类别。文本分类问题可以分解为两个子问题:文本表示和分类。在深度学习的方法出现之前,主流的文本表示方法为BOW(bag of words),分类方法有SVM,LR,Boosting等等。BOW忽略了词的顺序信息,而且是高维度的稀疏向量表示,这种表示浮于表面,并未充分表示文本的语义信息。例如,句子`这部电影糟糕透了`和`一个乏味,空洞,没有内涵的作品`在情感分析中具有很高的语义相似度,但是它们的BOW表示的相似度为0。又如,句子`小明很喜欢小芳,但是小芳不喜欢小明`和`小芳很喜欢小明,但是小明不喜欢小芳`的BOW相似度为1,但实际上它们的意思很不一样。本章我们所要介绍的深度学习模型克服了BOW表示的上述缺陷,它在考虑词的顺序的基础上把文本映射到低维度的语义空间,并且以端对端(end to end)的方式进行文本表示及分类,其性能相对于传统方法有显著的提升。
<br/>  实际上,在自然语言处理中,情感分析属于典型的**文本分类**问题,即,把需要进行情感分析的文本划分为其所属类别。文本分类问题可以分解为两个子问题:文本表示和分类。在深度学习的方法出现之前,主流的文本表示方法为BOW(bag of words),分类方法有SVM,LR,Boosting等等。BOW忽略了词的顺序信息,而且是高维度的稀疏向量表示,这种表示浮于表面,并未充分表示文本的语义信息。例如,句子`这部电影糟糕透了`和`一个乏味,空洞,没有内涵的作品`在情感分析中具有很高的语义相似度,但是它们的BOW表示的相似度为0。又如,句子`一个空洞,没有内涵的作品`和`一个不空洞而且有内涵的作品`的BOW相似度很高,但实际上它们的意思很不一样。本章我们所要介绍的深度学习模型克服了BOW表示的上述缺陷,它在考虑词的顺序的基础上把文本映射到低维度的语义空间,并且以端对端(end to end)的方式进行文本表示及分类,其性能相对于传统方法有显著的提升。
<br/>  对于一般的短文本分类问题,上文所述的简单的文本卷积网络即可达到很高的正确率\[[1](#参考文献)\]。若想得到更抽象更高级的文本特征表示,可以参考N. Kalchbrenner, et al.(2014)\[[2](#参考文献)\]或 Yann N. Dauphin, et al.(2016)\[[3](#参考文献)\]的构建深层文本卷积神经网络的方法。
### 循环神经网络
#### 简单的循环神经网络
<br/>  循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的(Siegelmann, H. T. and Sontag, E. D., 1995)。
<br/>  自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory\[[5](#参考文献)\]等)在自然语言处理的多个领域取得了丰硕的成果,如在语言模型,句法解析,语义角色标注(或一般的序列标注),语义表示,图文生成,对话,机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
<br/>  其中$W_{xh}$是输入到隐层的矩阵参数,$W_{hh}$是隐层到隐层的矩阵参数,$b_h$为隐层的偏置向量(bias)参数,$\sigma$为elementwise的sigmoid函数。在处理自然语言时,一般会先将词(one-hot表示)映射为其embedding表示,然后再作为循环神经网络每一时刻的输入$x_t$。可以根据实际需要的不同在循环神经网络的隐层上连接其它层。如,可以把一个循环神经网络的隐层输出连接至下一个循环神经网络的输入构建深层(deep or stacked)循环神经网络,或者提取最后一个时刻的隐层状态作为句子表示进而使用分类模型等等。
<br/>  可以看出,隐状态的输入来源于当前输入和前一时刻隐状态的值,这会导致很久以前的输入容易被覆盖掉。实际上,人们发现当序列很长时,循环神经网络就会表现很差(远距离依赖问题),训练过程中会出现梯度消失或爆炸现象(Bengio Y, Simard P, Frasconi P., 1994)。为了解决这一问题,Hochreiter S, Schmidhuber J. (1997)提出了lstm模型。
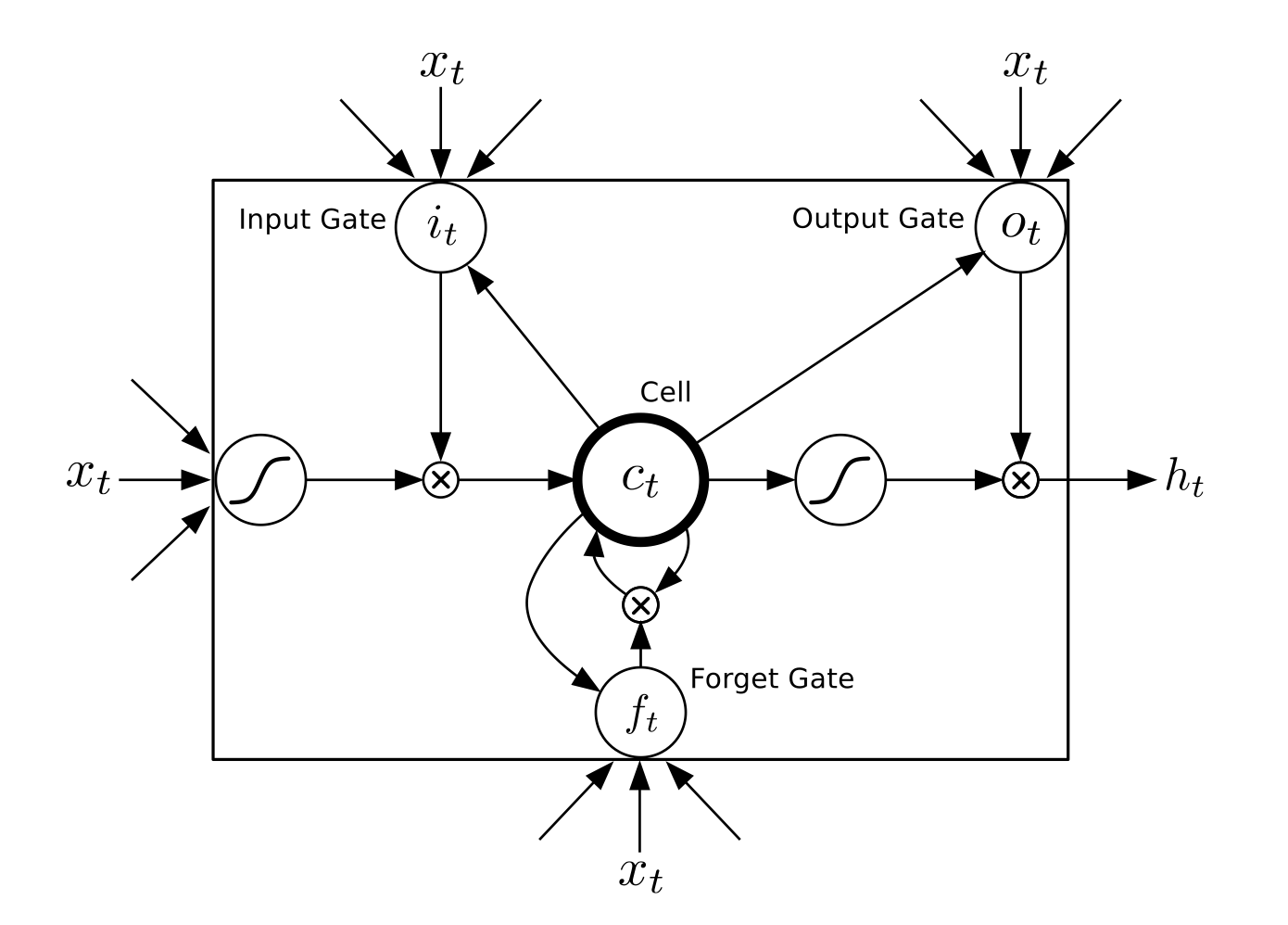
<br/>  可以看出,隐状态的输入来源于当前输入和前一时刻隐状态的值,这会导致很久以前的输入容易被覆盖掉。实际上,人们发现当序列很长时,循环神经网络就会表现很差(远距离依赖问题),训练过程中会出现梯度消失或爆炸现象\[[6](#参考文献)\]。为了解决这一问题,Hochreiter S, Schmidhuber J. (1997)\[[5](#参考文献)\]提出了lstm(long short term memory)模型。
<br/>  其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元(记忆单元一般对外不可见,$h_t$对外部可见)及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为elementwise的双曲正切函数,$\odot$表示elementwise的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数。这三种门各自以不同的方式控制着记忆单元$c$。实际上,lstm的思想正是通过给简单的循环神经网络增加记忆及控制门的方式增强了其处理远距离依赖问题的能力。类似原理的对于简单循环神经网络的改进还有Gated Recurrent Unit (GRU)( Cho K, Van Merriënboer B, Gulcehre C, et al. 2014),其设计更为简洁一些。**这些改进虽然各有不同,但是对他们的宏观描述却与简单的循环神经网络一样,如图1所示,隐状态依据当前输入及前一时刻的隐状态来改变,不断的循环这一过程直至输入处理完毕:**
<br/>  实际上,lstm的思想正是通过给简单的循环神经网络增加记忆及控制门的方式增强了其处理远距离依赖问题的能力。类似原理的对于简单循环神经网络的改进还有Gated Recurrent Unit (GRU)\[[8](#参考文献)\],其设计更为简洁一些。**这些改进虽然各有不同,但是对他们的宏观描述却与简单的循环神经网络一样,如图2所示,隐状态依据当前输入及前一时刻的隐状态来改变,不断的循环这一过程直至输入处理完毕:**
<br/>  一个简单的做法是分别使用正向lstm-rnn和反向lstm-rnn处理文本,取最后一个时刻的隐层值拼接起来做为文本的定长向量表示,将其连接至softmax得到文本分类模型。但是这样的文本分类模型是一个浅层模型。考虑到深层神经网络往往能得到更抽象和高级的特征表示,我们构建stacked lstm-rnn。如图3所示(以三层为例),奇数层lstm正向,偶数层lstm反向,高一层的lstm使用低一层lstm及之前所有层的信息作为输入,对最高层lstm序列使用max pooling over time得到文本定长向量表示。**这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象。**最后我们将文本表示连接至softmax构建分类模型。
<br/>  一个简单的做法是分别使用正向lstm-rnn和反向lstm-rnn处理文本,取最后一个时刻的隐层值拼接起来做为文本的定长向量表示,将其连接至softmax得到文本分类模型。但是这样的文本分类模型是一个浅层模型。考虑到深层神经网络往往能得到更抽象和高级的特征表示,我们构建stacked lstm-rnn\[[9](#参考文献)\]。如图4所示(以三层为例),奇数层lstm正向,偶数层lstm反向,高一层的lstm使用低一层lstm及之前所有层的信息作为输入,对最高层lstm序列使用max pooling over time得到文本定长向量表示。**这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象。**最后我们将文本表示连接至softmax构建分类模型。
<palign="center">
<imgsrc="image/stacked_lstm.jpg"><br/>
图 3 stacked lstm-rnn for text classification
图 4 stacked lstm-rnn for text classification
</p>
## 数据准备
### 数据介绍与下载
...
...
@@ -481,5 +498,14 @@ Loading parameters from model_output/pass-00002/
1. Kim Y. [Convolutional neural networks for sentence classification](http://arxiv.org/pdf/1408.5882)[J]. arXiv preprint arXiv:1408.5882, 2014.
2. Kalchbrenner N, Grefenstette E, Blunsom P. [A convolutional neural network for modelling sentences](http://arxiv.org/pdf/1404.2188.pdf?utm_medium=App.net&utm_source=PourOver)[J]. arXiv preprint arXiv:1404.2188, 2014.
3. Yann N. Dauphin, et al. [Language Modeling with Gated Convolutional Networks](https://arxiv.org/pdf/1612.08083v1.pdf)[J] arXiv preprint arXiv:1612.08083, 2016.
4. Siegelmann H T, Sontag E D. [On the computational power of neural nets](http://research.cs.queensu.ca/home/akl/cisc879/papers/SELECTED_PAPERS_FROM_VARIOUS_SOURCES/05070215382317071.pdf)[C]//Proceedings of the fifth annual workshop on Computational learning theory. ACM, 1992: 440-449.
6. Bengio Y, Simard P, Frasconi P. [Learning long-term dependencies with gradient descent is difficult](http://www-dsi.ing.unifi.it/~paolo/ps/tnn-94-gradient.pdf)[J]. IEEE transactions on neural networks, 1994, 5(2): 157-166.
7. Graves A. [Generating sequences with recurrent neural networks](http://arxiv.org/pdf/1308.0850)[J]. arXiv preprint arXiv:1308.0850, 2013.
8. Cho K, Van Merriënboer B, Gulcehre C, et al. [Learning phrase representations using RNN encoder-decoder for statistical machine translation](http://arxiv.org/pdf/1406.1078)[J]. arXiv preprint arXiv:1406.1078, 2014.
9. Zhou J, Xu W. [End-to-end learning of semantic role labeling using recurrent neural networks](http://www.aclweb.org/anthology/P/P15/P15-1109.pdf)[C]//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2015.
{kind=link}