Add Chinese docs for visualdl 2.0 (#619)
Showing
demo/components/image_test.py
0 → 100644
demo/components/scalar_test.py
0 → 100644
docs/README.md
0 → 100644
docs/components/README.md
0 → 100644
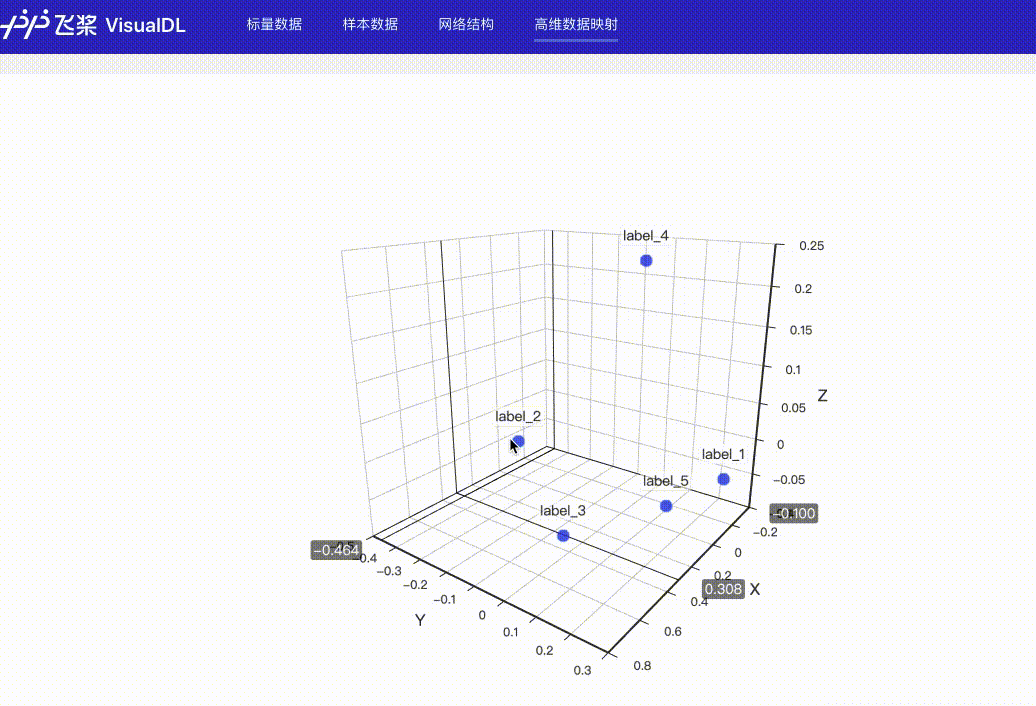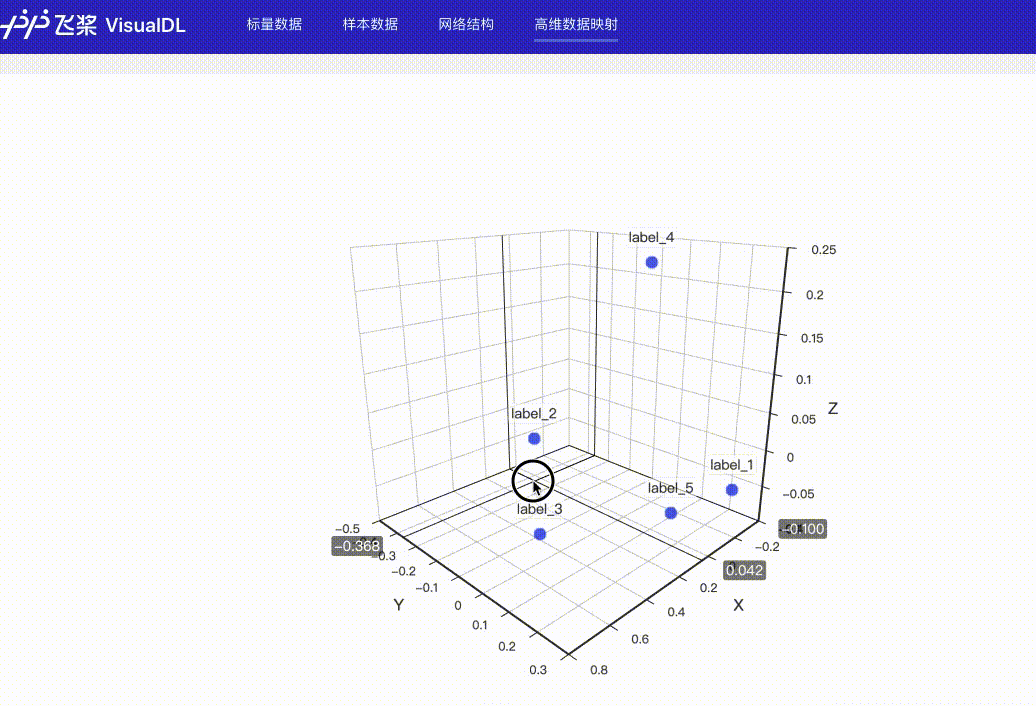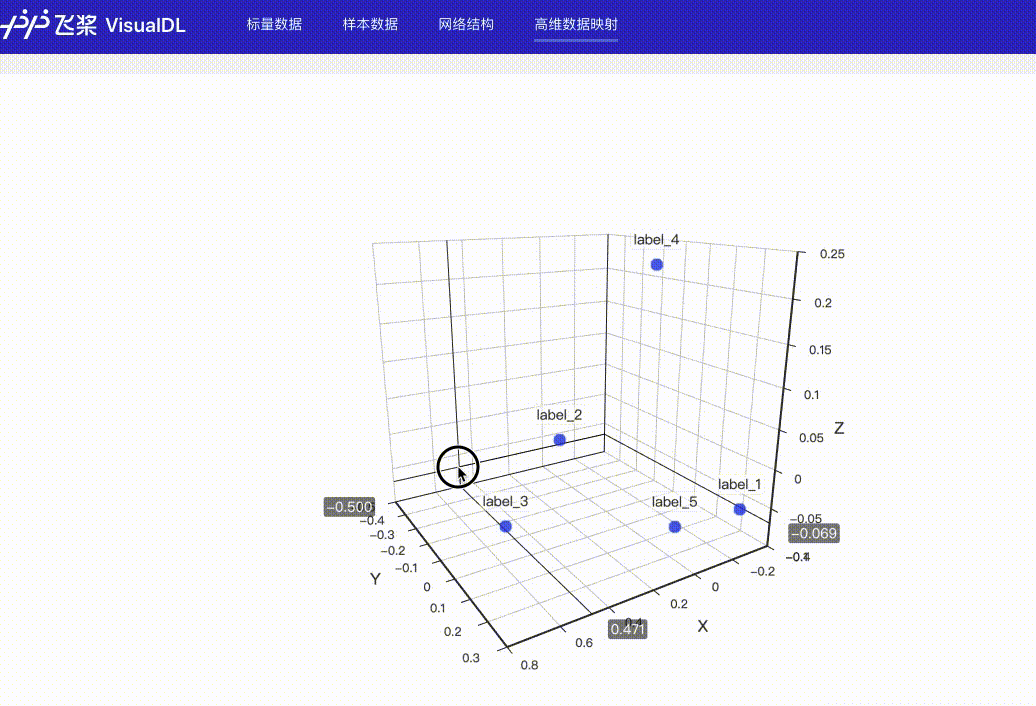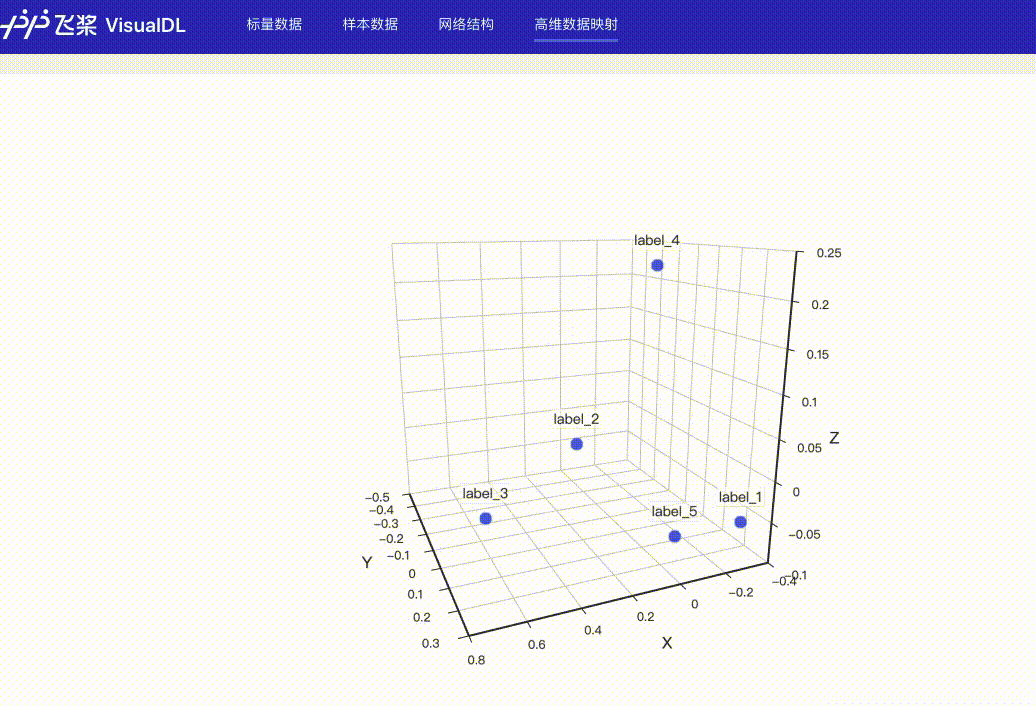
docs/images/3points_demo.png
0 → 100644
{kind=link}
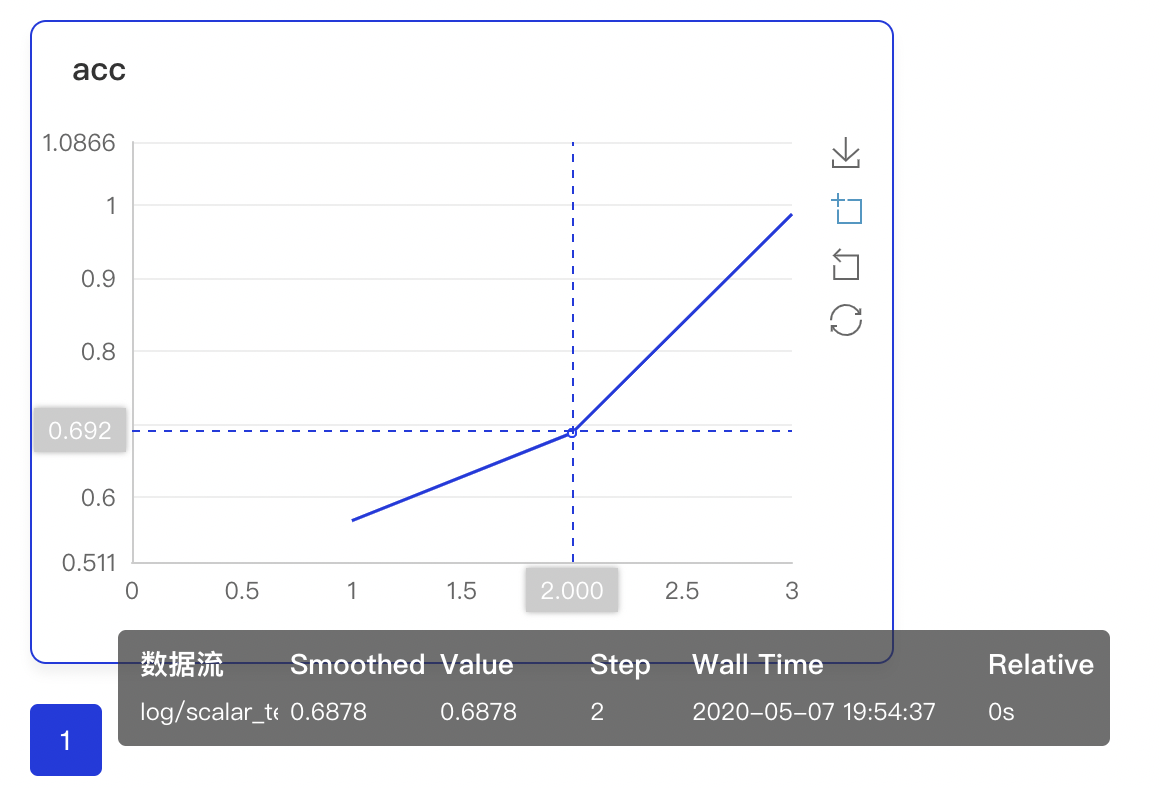
249.4 KB
{kind=link}
docs/images/dynamic_display.gif
0 → 100644
{kind=link}
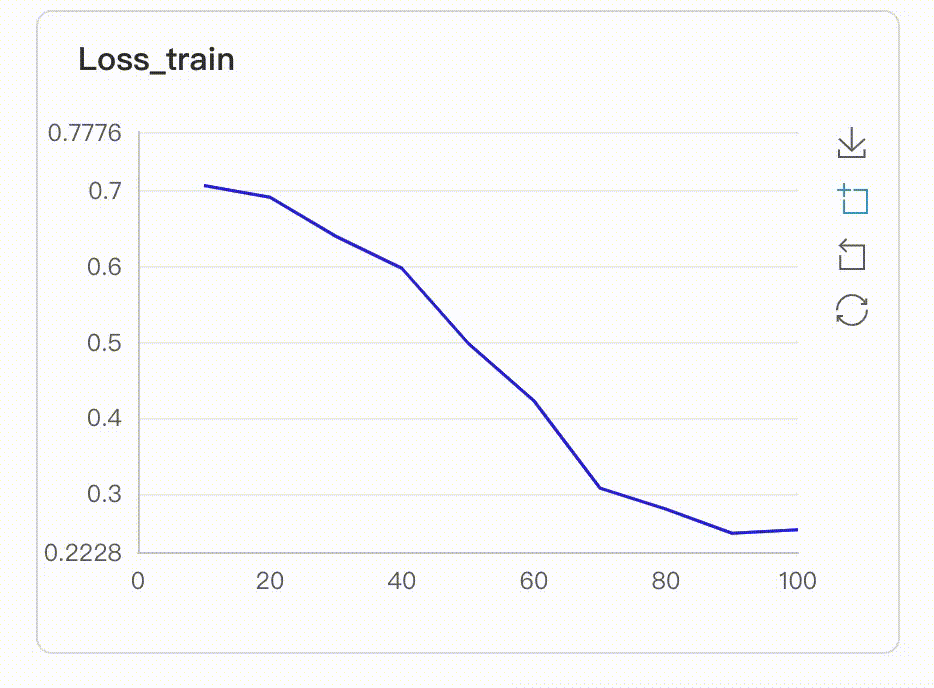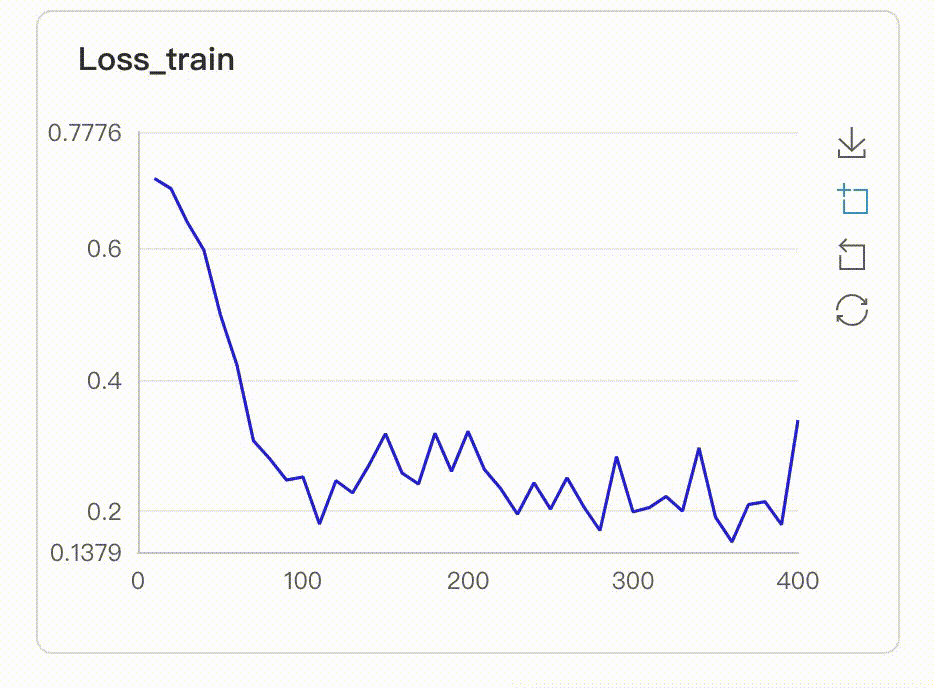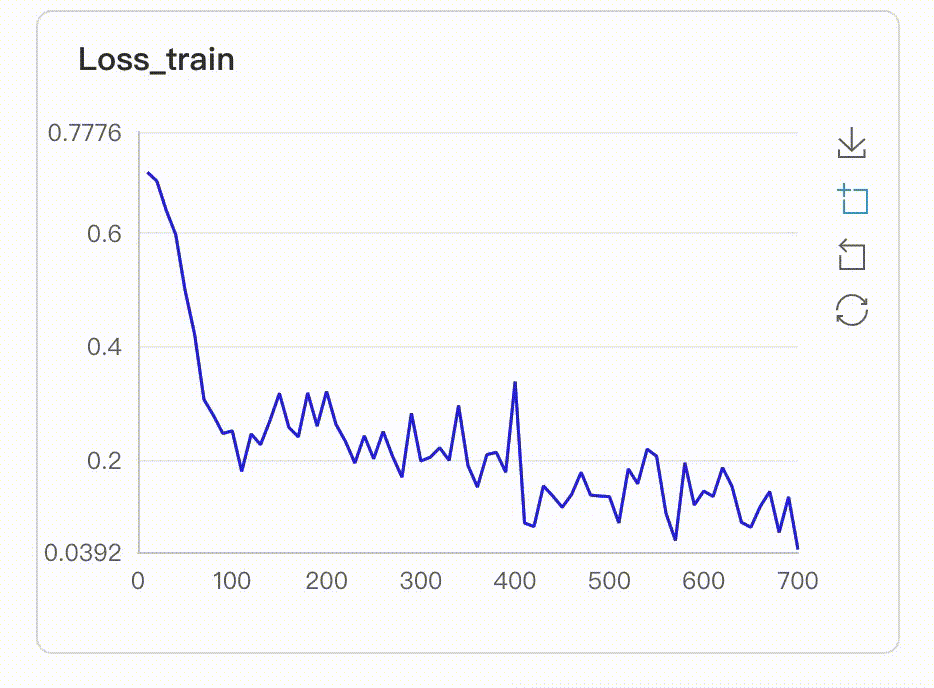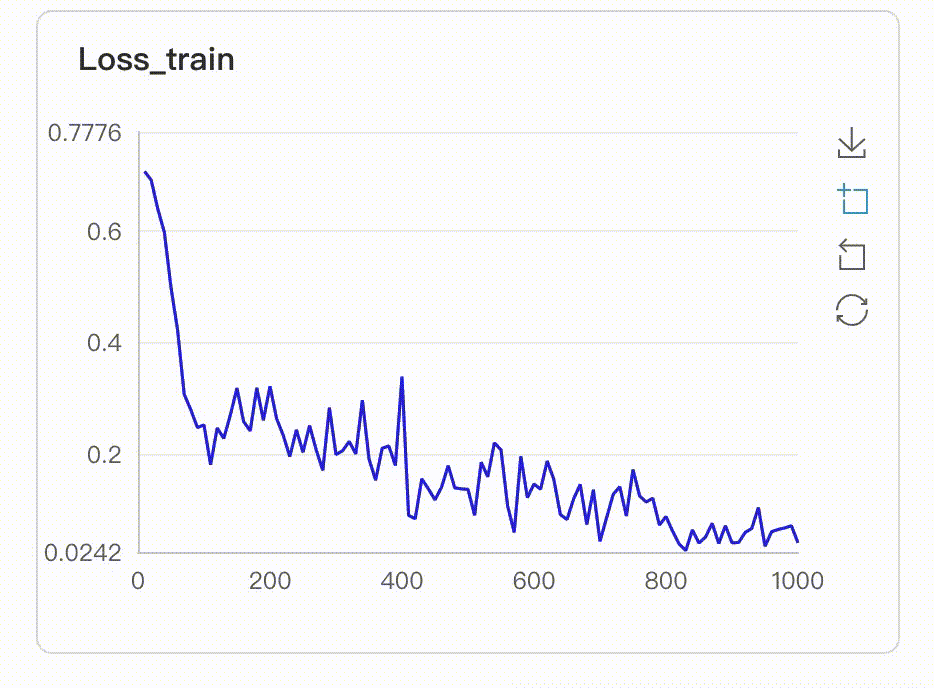
174.7 KB
{kind=link}
1.2 MB
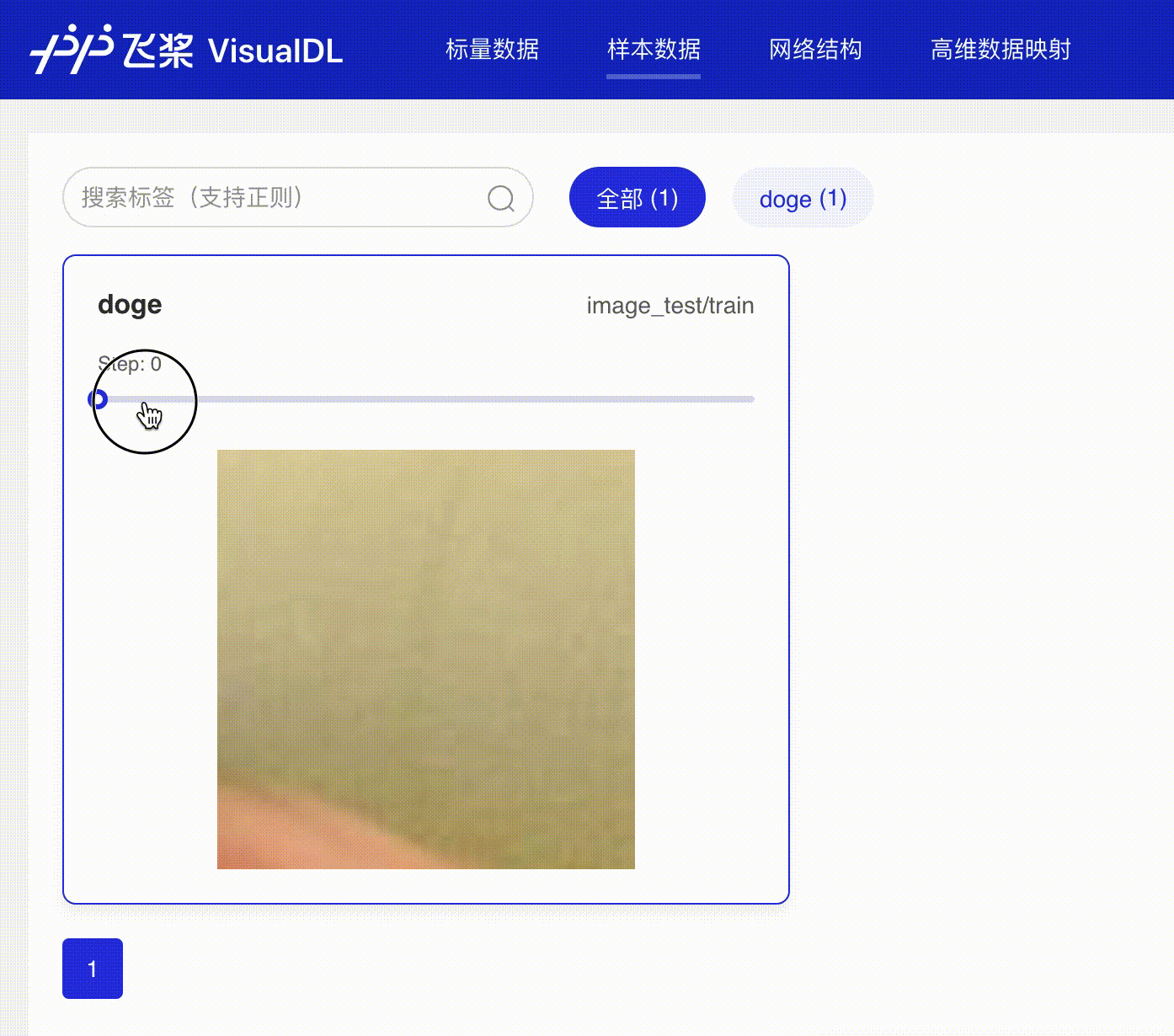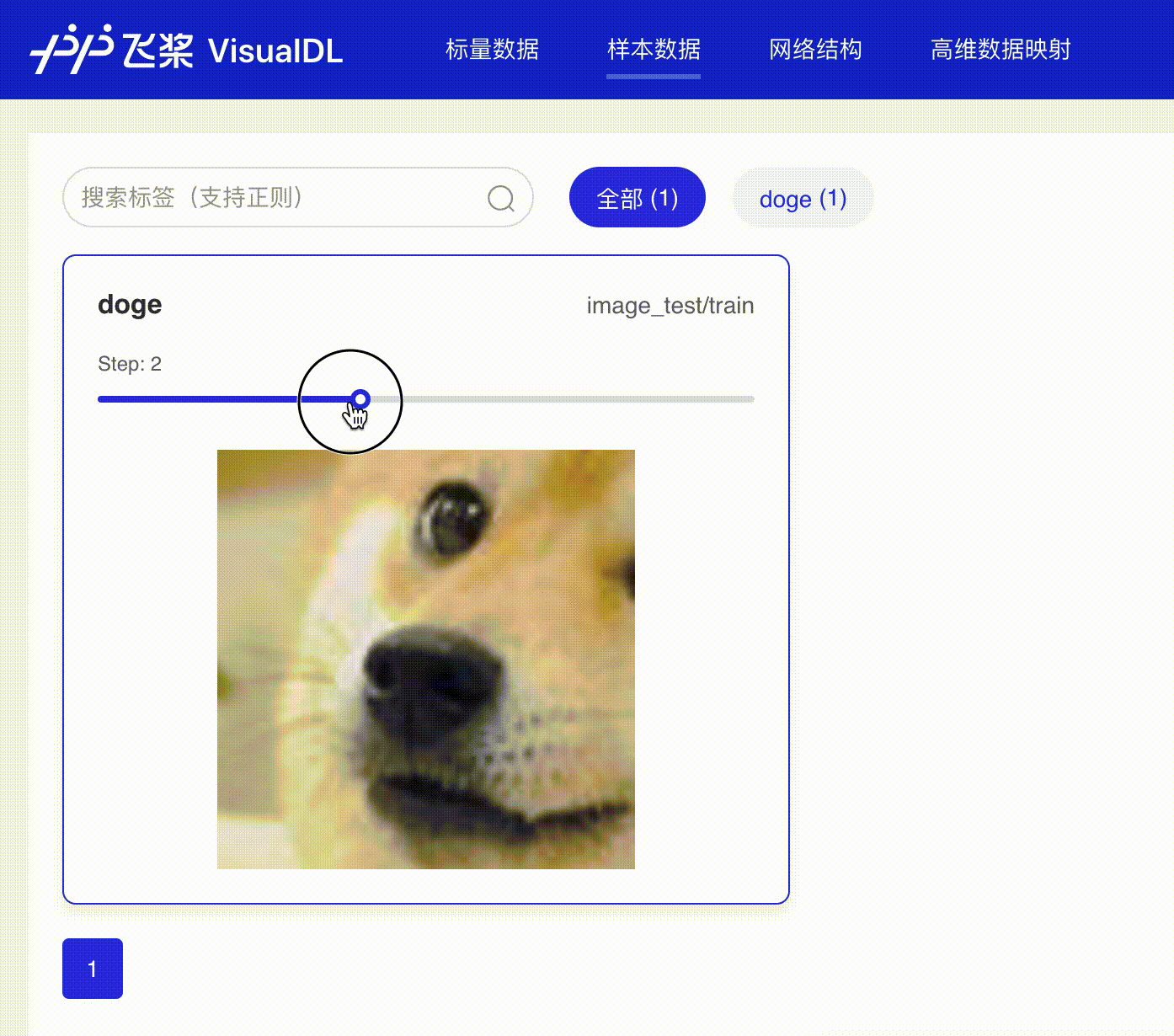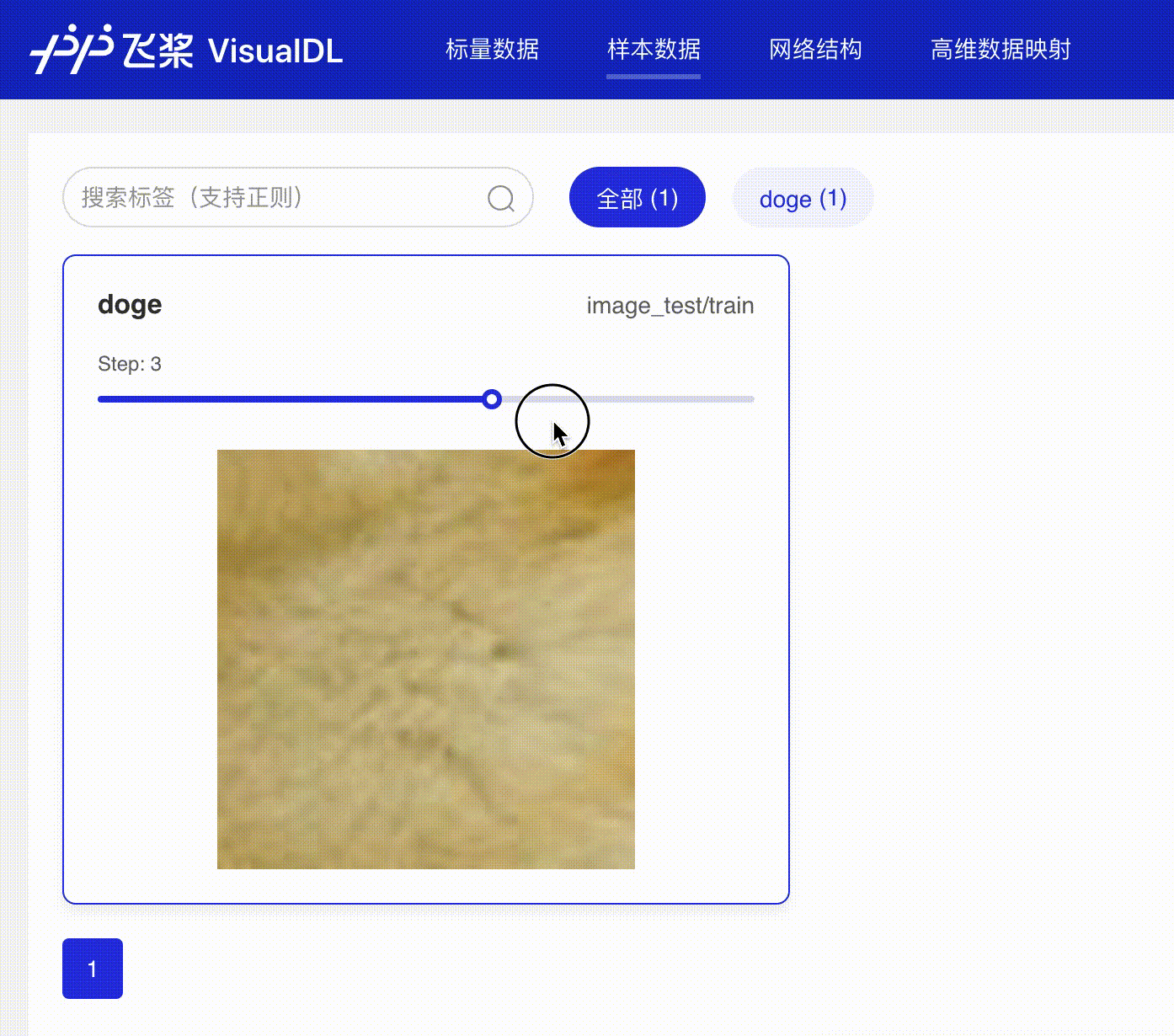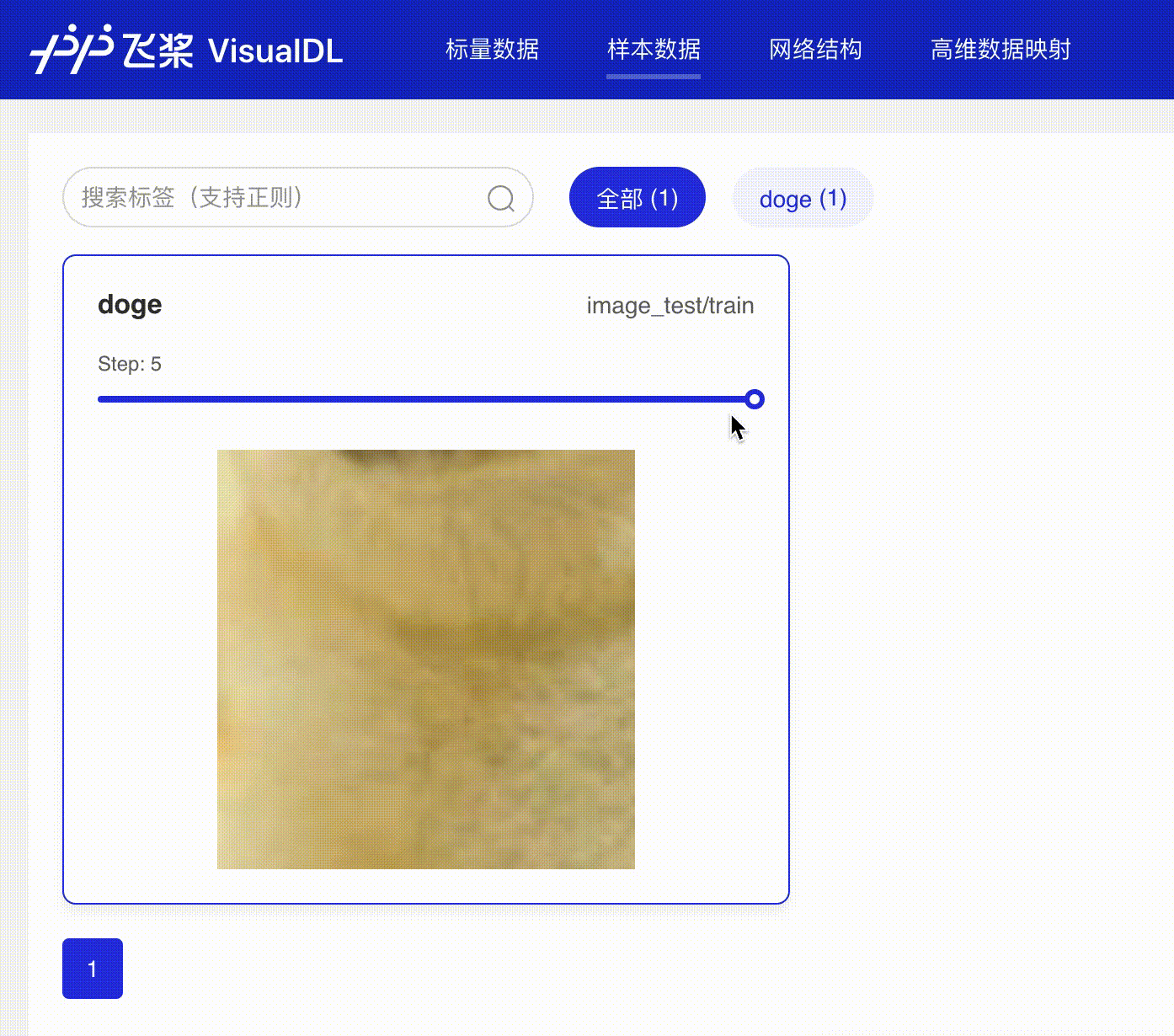
docs/images/dynamic_image.gif
0 → 100644
{kind=link}
649.0 KB
{kind=link}
882.9 KB
docs/images/image_test.png
0 → 100644
{kind=link}
1009.6 KB
docs/images/multi_experiments.gif
0 → 100644
{kind=link}
285.4 KB
docs/images/scalar_test.png
0 → 100644
{kind=link}
758.9 KB