Merge pull request #16 from Superjom/design/backend_overall_design
Design/backend overall design
Showing
docs/Plan.md
已删除
100644 → 0
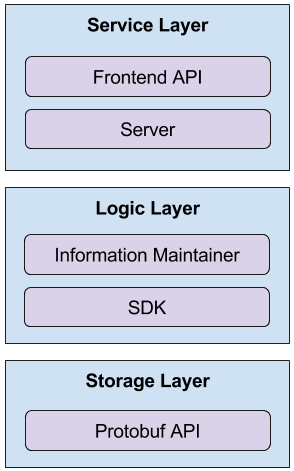
docs/backend_architecture.md
0 → 100644
{kind=link}
12.9 KB
Design/backend overall design
12.9 KB