Created by: barrierye
Auto-batching (fix #765 (closed))
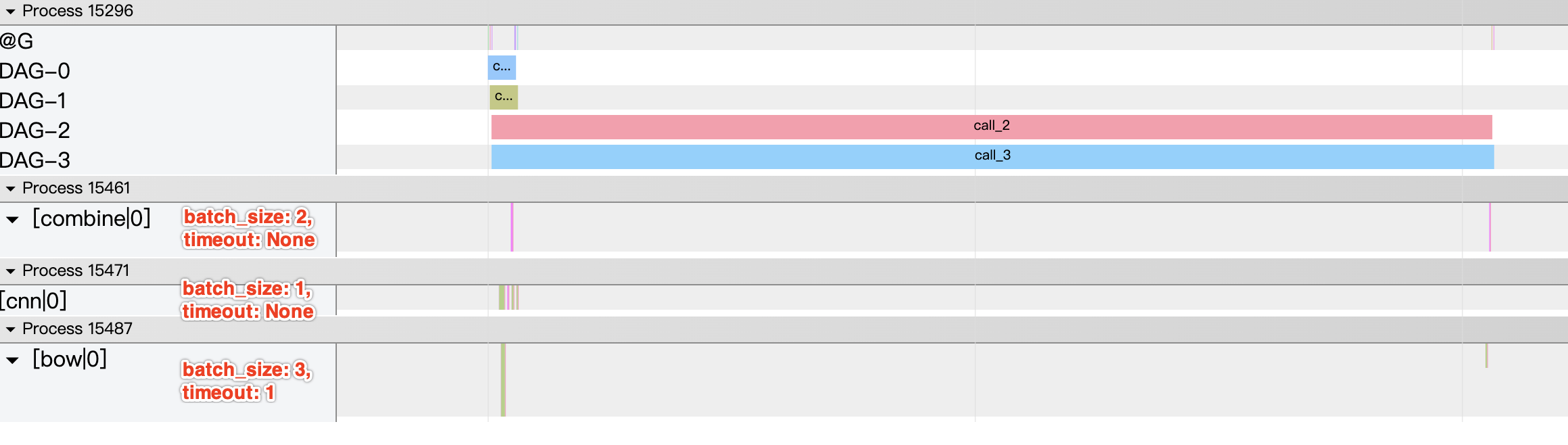
用户在定义Op的时候可以设定 batch_size(default=1) 和 auto_batching_timeout(default=None,单位ms) 两个参数,Op每次以 auto_batching_timeout 的耗时取 batch_size 大小的数据(timeout结束,取到了数据,但没取到batch_size大小,那么根据实际的batch_size继续运行)。 下图是 imdb model ensemble 的例子,其中:
- cnn Op: batch_size = 1,auto_batching_timeout = None
- bow Op: batch_size = 3, auto_batching_timeout = 1000 ms
- combine Op: batch_size = 2, auto_batching_timeout = None
Client一共发送 4 个异步的请求,bow Op获取前三个请求数据(batch)后将处理结果填入后面的channel,剩下的请求数据(第四个)无法在限定时间内构成batch,故bow第二次实际batch size=1
相关用户接口变动
- Op构造函数添加两个参数
def __init__(name=None,
input_ops=[],
server_endpoints=[],
fetch_list=[],
client_config=None,
concurrency=1,
timeout=-1,
retry=1,
+ batch_size=1,
+ auto_batching_timeout=None)- Op process函数参数意义改变(从 sample 变为 batch),类型从 dict 变为 list of dict
Update Log (fix #724 (closed))
- 日志分开,info的日志将写入pipeline.log,warning、error和critical的日志将写入pipeline.log.wf,监控日志将写入pipeline.tracer
PipelineServingLogs
|-- pipeline.log
|-- pipeline.log.wf
`-- pipeline.tracer- 框架生成的request id(data id)将作为 logid,如下:
ERROR 2020-08-04 06:31:26,559 [operator.py:379] (logid=155) [cnn|0] Failed to predict, please check if PaddleServingService is working properly.
ERROR 2020-08-04 06:31:30,564 [operator.py:379] (logid=156) [bow|0] Failed to predict, please check if PaddleServingService is working properly.- 会开启一个额外的监控进程(或线程,因为线程版中Channel不能跨进程访问),每隔一段时间输出一些指标(可通过yaml文件控制是否开启以及间隔时间),如下:
2020-08-04 06:45:20,910 ==================== TRACER ======================
2020-08-04 06:45:20,955 Op(cnn):
2020-08-04 06:45:20,956 in[500.53685 ms]
2020-08-04 06:45:20,956 prep[0.07595 ms]
2020-08-04 06:45:20,956 midp[1.23825 ms]
2020-08-04 06:45:20,956 postp[0.0884 ms]
2020-08-04 06:45:20,956 out[0.8262 ms]
2020-08-04 06:45:20,956 idle[0.997210231049]
2020-08-04 06:45:20,956 Op(combine):
2020-08-04 06:45:20,956 in[0.9873 ms]
2020-08-04 06:45:20,956 prep[1003.2115 ms]
2020-08-04 06:45:20,956 midp[0.092 ms]
2020-08-04 06:45:20,956 postp[0.1235 ms]
2020-08-04 06:45:20,956 out[1.5274 ms]
2020-08-04 06:45:20,956 idle[0.00249984666109]
2020-08-04 06:45:20,957 Op(bow):
2020-08-04 06:45:20,957 in[1002.4247 ms]
2020-08-04 06:45:20,957 prep[0.0884 ms]
2020-08-04 06:45:20,957 midp[1.4132 ms]
2020-08-04 06:45:20,957 postp[0.1109 ms]
2020-08-04 06:45:20,957 out[2.1565 ms]
2020-08-04 06:45:20,957 idle[0.998397425863]
2020-08-04 06:45:20,957 DAG:
2020-08-04 06:45:20,957 query count[20]
2020-08-04 06:45:20,957 qps[2.0 q/s]
2020-08-04 06:45:20,957 succ[1.0]
2020-08-04 06:45:20,957 latency:
2020-08-04 06:45:20,957 ave[50305.94565 ms]
2020-08-04 06:45:20,957 .50[50306.053 ms]
2020-08-04 06:45:20,957 .60[50306.59 ms]
2020-08-04 06:45:20,957 .70[50308.512 ms]
2020-08-04 06:45:20,958 .80[50309.009 ms]
2020-08-04 06:45:20,958 .90[51310.729 ms]
2020-08-04 06:45:20,958 .95[51312.773 ms]
2020-08-04 06:45:20,958 .99[51312.773 ms]
2020-08-04 06:45:20,958 Channel (server worker num[100]):
2020-08-04 06:45:20,958 chl0(producers: ['@DAGExecutor'], consumers: ['cnn', 'bow']) size[0/0]
2020-08-04 06:45:20,958 chl1(producers: ['bow', 'cnn'], consumers: ['combine']) size[97/0]
2020-08-04 06:45:20,958 chl2(producers: ['combine'], consumers: ['@DAGExecutor']) size[0/0]相关用户接口变动
- Op process函数添加 logid 参数,以用来穿透给 ServingService。
关于 logid (#783 (closed))
Serving目前还未对 logid 进行支持,目前做一个简单支持:
- bRPC Client 端 proto request 信息中带 logid (uint64),Client 端 predict 添加一个 logid 的参数(默认值为0)
- bRPC Server 端不生成 logid,仅从 Client 端获取。获取 logid 后进行设置(
./build/core/general-server/general_model_service.pb.cc),并传递给 inference,以便传给op - PipelineServing 这边如果是 Batch 请求,则选择 Batch 中的一个 logid 传递给 Serving,并把这个操作通过日志记录下来:
INFO 2020-08-07 07:07:44,170 [operator.py:341] (logid=4) During access to PaddleServingService, we selected logid=4 (from batch: [4, 5, 6]) as a representative for logging.
INFO 2020-08-07 07:07:44,170 [operator.py:341] (logid=5) During access to PaddleServingService, we selected logid=4 (from batch: [4, 5, 6]) as a representative for logging.
INFO 2020-08-07 07:07:44,170 [operator.py:341] (logid=6) During access to PaddleServingService, we selected logid=4 (from batch: [4, 5, 6]) as a representative for logging.后续 Serving 需要完善(不在该PR中完成):
- 若 bRPC Client 端 request 信息中 logid 为默认值,那么 bRPC Server 端生成一个 logid
Other
- Channel 的 Queue 替换成 PriorityQueue:多个请求的数据可能不是按顺序进入 Channel 的,会导致先到的请求不一定先被处理,延迟过大。
-
build_dag_each_worker模式下,为了让不同进程生成的 id 不同:以 worker_idx 为 counter_base,worker_num 为 step 生成 data_id (即 request_id, log_id)