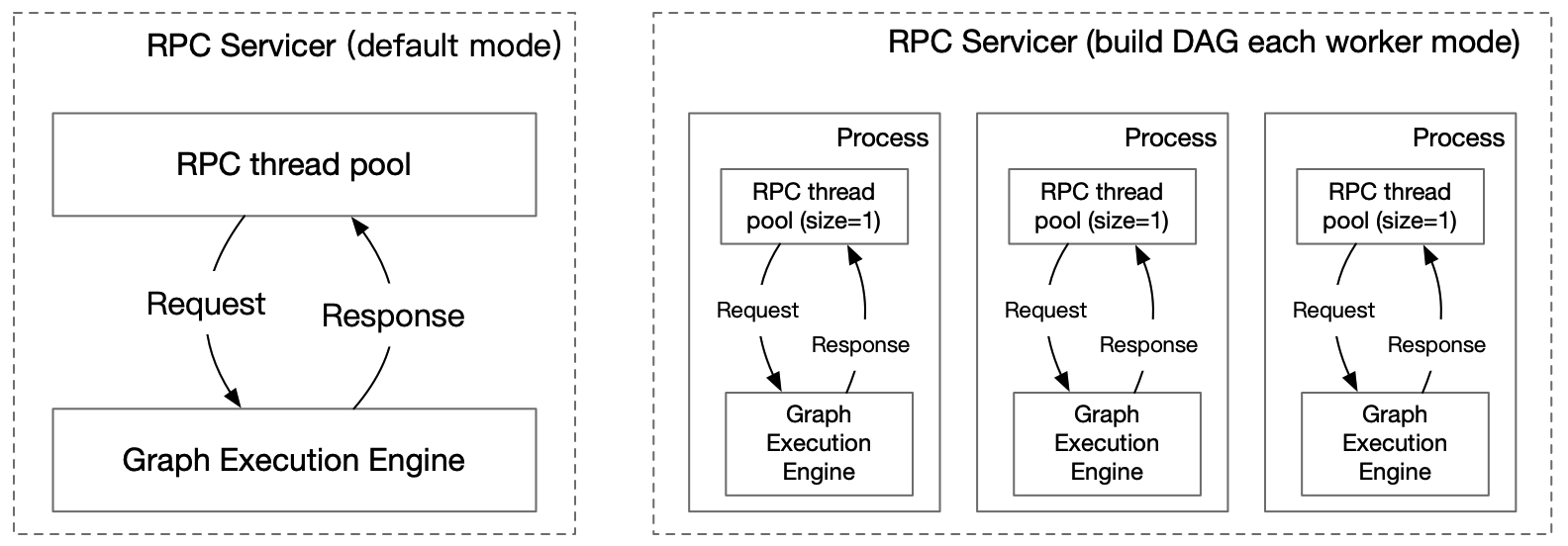
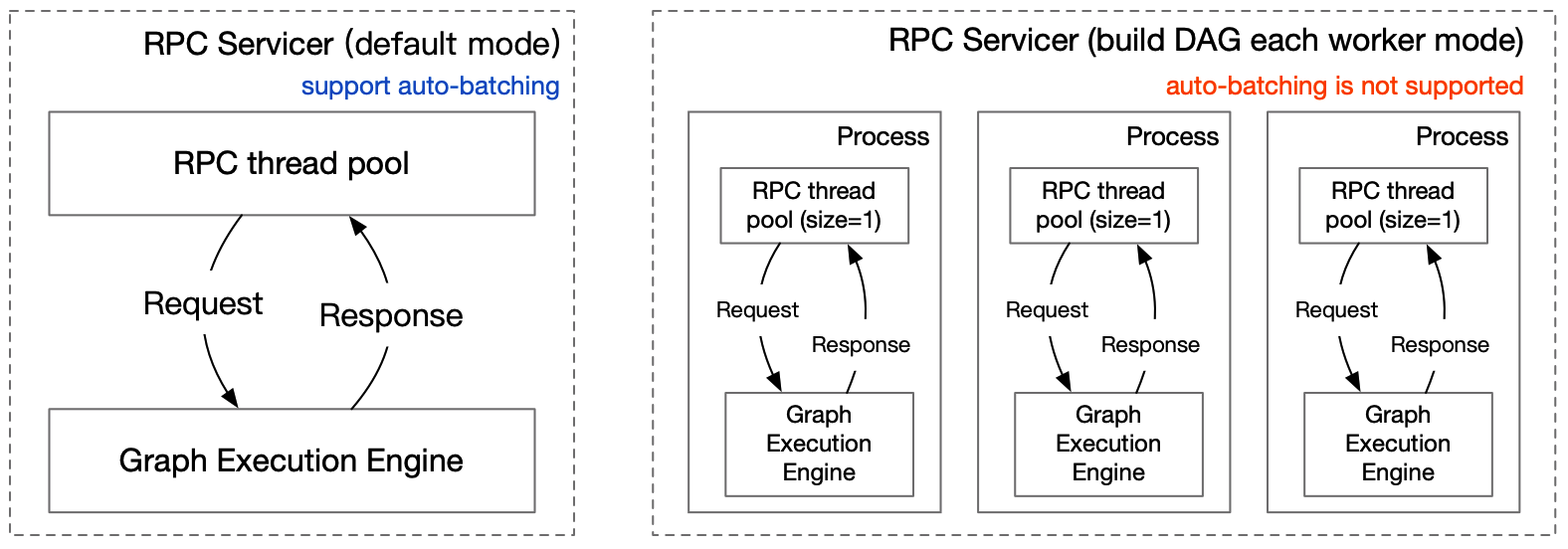
It is recommended to use Docker for compilation. We have prepared the Paddle Serving compilation environment for you, see [this document](DOCKER_IMAGES.md).
We should know something before converting to serving model
**inference_model_dir**:the directory of Paddle inference model
**serving_client_dir**: the directory of server side configuration
**serving_client_dir**: the directory of client side configuration
**model_filename**: this is model description file whose default value is `__model__`, if it's not default name, set `model_filename` explicitly
**params_filename**: during `save_inference_model` every Variable will be save as a single file. If we have the inference model whose params are compressed into one file, please set `params_filename` explicitly
@@ -33,6 +33,7 @@ The graph execution engine consists of OPs and Channels, and the connected OPs s
- The default function of a single OP is to access a single Paddle Serving Service based on the input Channel data and put the result into the output Channel.
- OP supports user customization, including preprocess, process, postprocess functions that can be inherited and implemented by the user.
- OP can set the number of concurrencies to increase the number of concurrencies processed.
- OP can obtain data from multiple different RPC requests for Auto-Batching.
- OP can be started by a thread or process.
### Channel Design
...
...
@@ -46,6 +47,7 @@ The graph execution engine consists of OPs and Channels, and the connected OPs s
</center>
### Extreme Case Consideration
- Request timeout
...
...
@@ -59,9 +61,9 @@ The graph execution engine consists of OPs and Channels, and the connected OPs s
- Whether input buffers and output buffers in Channel will increase indefinitely
- It will not increase indefinitely. The input to the entire graph execution engine is placed inside a Channel's internal queue, directly acting as a traffic control buffer queue for the entire service.
- For input buffer, adjust the number of concurrencies of OP1 and OP2 according to the amount of computation, so that the number of input buffers from each input OP is relatively balanced.
- For output buffer, you can use a similar process as input buffer, which adjusts the concurrency of OP3 and OP4 to control the buffer length of output buffer.
-Note: The length of the input buffer depends on the speed at which each item in the internal queue is ready, and the length of the output buffer depends on the speed at which downstream OPs obtain data from the output buffer.
- For input buffer, adjust the number of concurrencies of OP1 and OP2 according to the amount of computation, so that the number of input buffers from each input OP is relatively balanced. (The length of the input buffer depends on the speed at which each item in the internal queue is ready)
- For output buffer, you can use a similar process as input buffer, which adjusts the concurrency of OP3 and OP4 to control the buffer length of output buffer. (The length of the output buffer depends on the speed at which downstream OPs obtain data from the output buffer)
-The amount of data in the Channel will not exceed `worker_num` of gRPC, that is, it will not exceed the thread pool size.
| name | (str) String used to identify the OP type, which must be globally unique. |
| input_ops | (list) A list of all previous OPs of the current Op. |
| server_endpoints | (list) List of endpoints for remote Paddle Serving Service. If this parameter is not set, the OP will not access the remote Paddle Serving Service, that is, the process operation will not be performed. |
| fetch_list | (list) List of fetch variable names for remote Paddle Serving Service. |
| client_config | (str) The path of the client configuration file corresponding to the Paddle Serving Service. |
| concurrency | (int) The number of concurrent OPs. |
| timeout | (int) The timeout time of the process operation, in seconds. If the value is less than zero, no timeout is considered. |
| retry | (int) Timeout number of retries. When the value is 1, no retries are made. |
| name | (str) String used to identify the OP type, which must be globally unique. |
| input_ops | (list) A list of all previous OPs of the current Op. |
| server_endpoints | (list) List of endpoints for remote Paddle Serving Service. If this parameter is not set, the OP will not access the remote Paddle Serving Service, that is, the process operation will not be performed. |
| fetch_list | (list) List of fetch variable names for remote Paddle Serving Service. |
| client_config | (str) The path of the client configuration file corresponding to the Paddle Serving Service. |
| concurrency | (int) The number of concurrent OPs. |
| timeout | (int) The timeout time of the process operation, in ms. If the value is less than zero, no timeout is considered. |
| retry | (int) Timeout number of retries. When the value is 1, no retries are made. |
| batch_size | (int) The expected batch_size of Auto-Batching, since building batches may time out, the actual batch_size may be less than the set value. |
| auto_batching_timeout | (float) Timeout for building batches of Auto-Batching (the unit is ms). |
#### 2. General OP Secondary Development Interface
| def preprocess(self, input_dicts) | Process the data obtained from the channel, and the processed data will be used as the input of the **process** function. |
| def process(self, feed_dict) | The RPC prediction process is based on the Paddle Serving Client, and the processed data will be used as the input of the **postprocess** function. |
| def postprocess(self, input_dicts, fetch_dict) | After processing the prediction results, the processed data will be put into the subsequent Channel to be obtained by the subsequent OP. |
| def init_op(self) | Used to load resources (such as word dictionary). |
| self.concurrency_idx | Concurrency index of current thread / process (different kinds of OP are calculated separately). |
| def preprocess(self, input_dicts) | Process the data obtained from the channel, and the processed data will be used as the input of the **process** function. (This function handles a **sample**) |
| def process(self, feed_dict_list, typical_logid) | The RPC prediction process is based on the Paddle Serving Client, and the processed data will be used as the input of the **postprocess** function. (This function handles a **batch**) |
| def postprocess(self, input_dicts, fetch_dict) | After processing the prediction results, the processed data will be put into the subsequent Channel to be obtained by the subsequent OP. (This function handles a **sample**) |
| def init_op(self) | Used to load resources (such as word dictionary). |
| self.concurrency_idx | Concurrency index of current process(not thread) (different kinds of OP are calculated separately). |
In a running cycle, OP will execute three operations: preprocess, process, and postprocess (when the `server_endpoints` parameter is not set, the process operation is not executed). Users can rewrite these three functions. The default implementation is as follows:
The parameter of **preprocess** is the data `input_dicts` in the previous Channel. This variable is a dictionary with the name of the previous OP as key and the output of the corresponding OP as value.
The parameter of **preprocess** is the data `input_dicts` in the previous Channel. This variable (as a **sample**) is a dictionary with the name of the previous OP as key and the output of the corresponding OP as value.
The parameter of **process** is the input variable `fetch_dict` (the return value of the preprocess function) of the Paddle Serving Client prediction interface. This variable is a dictionary with feed_name as the key and the data in the ndarray format as the value.
The parameter of **process** is the input variable `fetch_dict_list` (a list of the return value of the preprocess function) of the Paddle Serving Client prediction interface. This variable (as a **batch**) is a list of dictionaries with feed_name as the key and the data in the ndarray format as the value. `typical_logid` is used as the logid that penetrates to PaddleServingService.
The parameters of **postprocess** are `input_dicts` and `fetch_dict`. `input_dicts` is consistent with the parameter of preprocess, and `fetch_dict`is the return value of the process function (if process is not executed, this value is the return value of preprocess).
The parameters of **postprocess** are `input_dicts` and `fetch_dict`. `input_dicts` is consistent with the parameter of preprocess, and `fetch_dict`(as a **sample**) is a sample of the return batch of the process function (if process is not executed, this value is the return value of preprocess).
Users can also rewrite the **init_op** function to load some custom resources (such as word dictionary). The default implementation is as follows:
...
...
@@ -143,7 +154,7 @@ def init_op(self):
pass
```
It should be noted that in the threaded version of OP, each OP will only call this function once, so the loaded resources must be thread safe.
It should be **noted** that in the threaded version of OP, each OP will only call this function once, so the loaded resources must be thread safe.
#### 3. RequestOp Definition
...
...
@@ -248,6 +259,8 @@ dag:
client_type:brpc# Use brpc or grpc client. The default is brpc
retry:1# The number of times DAG executor retries after failure. The default value is 1, that is, no retrying
use_profile:false# Whether to print the log on the server side. The default is false
tracer:
interval_s:600# Monitoring time interval of Tracer (in seconds). Do not start monitoring when the value is less than 1. The default value is -1
```
...
...
@@ -282,14 +295,8 @@ from paddle_serving_server.pipeline import PipelineServer
After the function is enabled, the server will print the corresponding log information to the standard output in the process of prediction. In order to show the time consumption of each stage more intuitively, scripts are provided for further analysis and processing of log files.
After the function is enabled, the server will print the corresponding log information to the standard output in the process of prediction. In order to show the time consumption of each stage more intuitively, Analyst module is provided for further analysis and processing of log files.
The output of the server is first saved to a file. Taking profile as an example, the script converts the time monitoring information in the log into JSON format and saves it to the trace file. The trace file can be visualized through the tracing function of Chrome browser.
The output of the server is first saved to a file. Taking `profile.txt` as an example, the script converts the time monitoring information in the log into JSON format and saves it to the `trace` file. The `trace` file can be visualized through the tracing function of Chrome browser.
```shell
python timeline_trace.py profile trace
from paddle_serving_server.pipeline import Analyst
import json
import sys
if __name__ =="__main__":
log_filename ="profile.txt"
trace_filename ="trace"
analyst = Analyst(log_filename)
analyst.save_trace(trace_filename)
```
Specific operation: open Chrome browser, input in the address bar `chrome://tracing/` , jump to the tracing page, click the load button, open the saved trace file, and then visualize the time information of each stage of the prediction service.
Specific operation: open Chrome browser, input in the address bar `chrome://tracing/` , jump to the tracing page, click the load button, open the saved `trace` file, and then visualize the time information of each stage of the prediction service.
{kind=link}
{kind=link}