Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
bfa28abc
S
Serving
项目概览
PaddlePaddle
/
Serving
大约 2 年 前同步成功
通知
187
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
bfa28abc
编写于
7月 17, 2020
作者:
B
barrierye
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add doc for pipeline
上级
a2c8103a
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
377 addition
and
0 deletion
+377
-0
doc/PIPELINE_SERVING_CN.md
doc/PIPELINE_SERVING_CN.md
+377
-0
doc/pipeline-img1.png
doc/pipeline-img1.png
+0
-0
未找到文件。
doc/PIPELINE_SERVING_CN.md
0 → 100644
浏览文件 @
bfa28abc
# Pipeline Serving
Paddle Serving 通常用于单模型的一键部署,但端到端的深度学习模型当前还不能解决所有问题,多个深度学习模型配合起来使用还是解决现实问题的常规手段。
Paddle Serving 提供了用户友好的多模型组合服务编程框架,Pipeline Serving,旨在降低编程门槛,提升整体的预估效率。
## 整体架构设计
Server端基于 gRPC 和图执行引擎构建,两者的关系如下图所示。
<center>
<img
src=
'pipeline_serving-image1.png'
height =
"250"
align=
"middle"
/>
</center>
### 图执行引擎
图执行引擎由 OP 和 Channel 构成,相连接的 OP 之间会共享一个 Channel。
-
Channel 可以理解为一个缓冲队列。每个 OP 只接受一个 Channel 的输入和一个多个 Channel 的输出(每个输出相同);一个 Channel 可以包含来自多个 OP 的输出,同一个 Channel 的数据可以作为多个 OP 的输入Channel
-
用户只需要定义 OP 间的关系,在编译期图引擎负责分析整个图的依赖关系,并声明Channel
-
Request 进入图执行引擎服务后会产生一个 Request Id,Reponse 会通过 Request Id 进行对应的返回
-
对于 OP 之间需要传输过大数据的情况,可以考虑 RAM DB 外存进行全局存储,通过在 Channel 中传递索引的 Key 来进行数据传输
<center>
<img
src=
'pipeline_serving-image2.png'
height =
"300"
align=
"middle"
/>
</center>
### OP的设计
-
单个OP默认的功能是根据输入的 Channel 数据,访问一个 Paddle Serving 的单模型服务,并将结果存在输出的 Channel
-
单个 OP 可以支持用户自定义,包括 preprocess,process,postprocess 三个函数都可以由用户继承和实现
-
单个 OP 可以控制并发数,从而增加处理并发数
-
OP 可以由线程或进程启动
### Channel的设计
-
Channel 是 OP 之间共享数据的数据结构,负责共享数据或者共享数据状态信息
-
Channel 可以支持多个OP的输出存储在同一个 Channel,同一个 Channel 中的数据可以被多个 OP 使用
-
下图为图执行引擎中 Channel 的设计,采用 input buffer 和 output buffer 进行多 OP 输入或多 OP 输出的数据对齐,中间采用一个 Queue 进行缓冲
<center>
<img
src=
'pipeline_serving-image3.png'
height =
"500"
align=
"middle"
/>
</center>
### 极端情况的考虑
-
请求超时的处理
整个图执行引擎每一步都有可能发生超时,图执行引擎里面通过设置 timeout 值来控制,任何环节超时的请求都会返回超时响应。
-
Channel 存储的数据过大
Channel 中可能会存储过大的数据,导致拷贝等耗时过高,图执行引擎里面可以通过将 OP 计算结果数据存储到外存,如高速的内存 KV 系统
-
Channel 设计中的 input buffer 和 output buffer 是否会无限增加
-
不会。整个图执行引擎的输入会放到一个 Channel 的 internal queue 里面,直接作为整个服务的流量控制缓冲队列
-
对于 input buffer,根据计算量的情况调整 OP1 和 OP2 的并发数,使得 input buffer 来自各个输入 OP 的数量相对平衡
-
对于 output buffer,可以采用和 input buffer 类似的处理方法,即调整 OP3 和 OP4 的并发数,使得 output buffer 的缓冲长度得到控制
-
注:input buffer 的长度取决于 internal queue 中每个 item 完全 ready 的速度,output buffer 的长度取决于下游 OP 从 output buffer 获取数据的速度
## 详细设计
### 用户接口设计
#### 1. 普通 OP 定义
普通 OP 作为图执行引擎中的基本单元,其构造函数如下:
```
python
def
__init__
(
name
=
None
,
input_ops
=
[],
server_endpoints
=
[],
fetch_list
=
[],
client_config
=
None
,
concurrency
=
1
,
timeout
=-
1
,
retry
=
1
)
```
各参数含义如下
| 参数名 | 含义 |
| :--------------: | :----------------------------------------------------------: |
| name | (str)用于标识 OP 类型的字符串,该字段必须全局唯一。 |
| input_ops | (list)当前 OP 的所有前继 OP 的列表。 |
| server_endpoints | (list)远程 Paddle Serving Service 的 endpoints 列表。如果不设置该参数,则不访问远程 Paddle Serving Service,即 不会执行 process 操作。 |
| fetch_list | (list)远程 Paddle Serving Service 的 fetch 列表。 |
| client_config | (str)Paddle Serving Service 对应的 Client 端配置文件路径。 |
| concurrency | (int)OP 的并发数。 |
| timeout | (int)process 操作的超时时间,单位为秒。若该值小于零,则视作不超时。 |
| retry | (int)超时重试次数。当该值为 1 时,不进行重试。 |
#### 2. 普通 OP二次开发接口
| 变量或接口 | 说明 |
| :--------------------------------------------: | :----------------------------------------------------------: |
| def preprocess(self, input_dicts) | 对从 Channel 中获取的数据进行处理,处理完的数据将作为
**process**
函数的输入。 |
| def process(self, feed_dict) | 基于 Paddle Serving Client 进行 RPC 预测,处理完的数据将作为
**postprocess**
函数的输入。 |
| def postprocess(self, input_dicts, fetch_dict) | 处理预测结果,处理完的数据将被放入后继 Channel 中,以被后继 OP 获取。 |
| def init_op(self) | 用于加载资源(如字典等)。 |
| self.concurrency_idx | 当前线程(进程)的并发数索引(不同种类的 OP 单独计算)。 |
OP 在一个运行周期中会依次执行 preprocess,process,postprocess 三个操作(当不设置
`server_endpoints`
参数时,不执行 process 操作),用户可以对这三个函数进行重写,默认实现如下:
```
python
def
preprocess
(
self
,
input_dicts
):
# multiple previous Op
if
len
(
input_dicts
)
!=
1
:
raise
NotImplementedError
(
'this Op has multiple previous inputs. Please override this func.'
)
(
_
,
input_dict
),
=
input_dicts
.
items
()
return
input_dict
def
process
(
self
,
feed_dict
):
err
,
err_info
=
ChannelData
.
check_npdata
(
feed_dict
)
if
err
!=
0
:
raise
NotImplementedError
(
"{} Please override preprocess func."
.
format
(
err_info
))
call_result
=
self
.
client
.
predict
(
feed
=
feed_dict
,
fetch
=
self
.
_fetch_names
)
return
call_result
def
postprocess
(
self
,
input_dicts
,
fetch_dict
):
return
fetch_dict
```
**preprocess**
的参数是前继 Channel 中的数据
`input_dicts`
,该变量是一个以前继 OP 的 name 为 Key,对应 OP 的输出为 Value 的字典。
**process **
的参数是 Paddle Serving Client 预测接口的输入变量
`fetch_dict`
(preprocess 函数的返回值),该变量是一个以 feed_name 为 Key,对应 ndarray 格式的数据为 Value 的字典。
**postprocess**
的参数是
`input_dicts`
和
`fetch_dict`
,
`input_dicts`
与 preprocess 的参数一致,
`fetch_dict`
是 process 函数的返回值(如果没有执行 process ,则该值为 preprocess 的返回值)。
用户还可以对
**init_op**
函数进行重写,已加载自定义的一些资源(比如字典等),默认实现如下:
```
python
def
init_op
(
self
):
pass
```
需要注意的是,在线程版 OP 中,每个 OP 只会调用一次该函数,故加载的资源必须要求是线程安全的。
#### 3. RequestOp 定义
RequestOp 用于处理 Pipeline Server 接收到的 RPC 数据,处理后的数据将会被加入到图执行引擎中。其构造函数如下:
```
python
def
__init__
(
self
)
```
#### 4. RequestOp 二次开发接口
| 变量或接口 | 说明 |
| :---------------------------------------: | :----------------------------------------: |
| def init_op(self) | 用于加载资源(如字典等),与普通 OP 一致。 |
| def unpack_request_package(self, request) | 处理接收到的 RPC 数据。 |
**unpack_request_package**
的默认实现是将 RPC request 中的 key 和 value 做成字典:
```
python
def
unpack_request_package
(
self
,
request
):
dictdata
=
{}
for
idx
,
key
in
enumerate
(
request
.
key
):
data
=
request
.
value
[
idx
]
try
:
data
=
eval
(
data
)
except
Exception
as
e
:
pass
dictdata
[
key
]
=
data
return
dictdata
```
要求返回值是一个字典类型。
#### 5. ResponseOp 定义
ResponseOp 用于处理图执行引擎的预测结果,处理后的数据将会作为 Pipeline Server 的RPC 返回值,其构造函数如下:
```
python
def
__init__
(
self
,
input_ops
)
```
其中,
`input_ops`
是图执行引擎的最后一个 OP,用户可以通过设置不同的
`input_ops`
以在不修改 OP 的拓扑关系下构造不同的 DAG。
#### 6. ResponseOp 二次开发接口
| 变量或接口 | 说明 |
| :------------------------------------------: | :-----------------------------------------: |
| def init_op(self) | 用于加载资源(如字典等),与普通 OP 一致。 |
| def pack_response_package(self, channeldata) | 处理图执行引擎的预测结果,作为 RPC 的返回。 |
**pack_response_package**
的默认实现是将预测结果的字典转化为 RPC response 中的 key 和 value:
```
python
def
pack_response_package
(
self
,
channeldata
):
resp
=
pipeline_service_pb2
.
Response
()
resp
.
ecode
=
channeldata
.
ecode
if
resp
.
ecode
==
ChannelDataEcode
.
OK
.
value
:
if
channeldata
.
datatype
==
ChannelDataType
.
CHANNEL_NPDATA
.
value
:
feed
=
channeldata
.
parse
()
np
.
set_printoptions
(
threshold
=
np
.
nan
)
for
name
,
var
in
feed
.
items
():
resp
.
value
.
append
(
var
.
__repr__
())
resp
.
key
.
append
(
name
)
elif
channeldata
.
datatype
==
ChannelDataType
.
DICT
.
value
:
feed
=
channeldata
.
parse
()
for
name
,
var
in
feed
.
items
():
if
not
isinstance
(
var
,
str
):
resp
.
ecode
=
ChannelDataEcode
.
TYPE_ERROR
.
value
resp
.
error_info
=
self
.
_log
(
"fetch var type must be str({})."
.
format
(
type
(
var
)))
break
resp
.
value
.
append
(
var
)
resp
.
key
.
append
(
name
)
else
:
resp
.
ecode
=
ChannelDataEcode
.
TYPE_ERROR
.
value
resp
.
error_info
=
self
.
_log
(
"Error type({}) in datatype."
.
format
(
channeldata
.
datatype
))
else
:
resp
.
error_info
=
channeldata
.
error_info
return
resp
```
#### 7. PipelineServer定义
PipelineServer 的定义比较简单,如下所示:
```
python
server
=
PipelineServer
()
server
.
set_response_op
(
response_op
)
server
.
prepare_server
(
config_yml_path
)
server
.
run_server
()
```
其中,
`response_op`
为上面提到的 ResponseOp,PipelineServer 将会根据各个 OP 的拓扑关系初始化 Channel 并构建计算图。
`config_yml_path`
为 PipelineServer 的配置文件,示例文件如下:
```
yaml
port
:
18080
# gRPC端口号
worker_num
:
1
# gRPC线程池大小(进程版 Servicer 中为进程数),默认为 1
build_dag_each_worker
:
false
# 是否使用进程版 Servicer,默认为 false
dag
:
is_thread_op
:
true
# 是否使用线程版Op,默认为 true
client_type
:
brpc
# 使用 brpc 或 grpc client,默认为 brpc
retry
:
1
# DAG Executor 在失败后重试次数,默认为 1,即不重试
use_profile
:
false
# 是否在 Server 端打印日志,默认为 false
```
## 例子
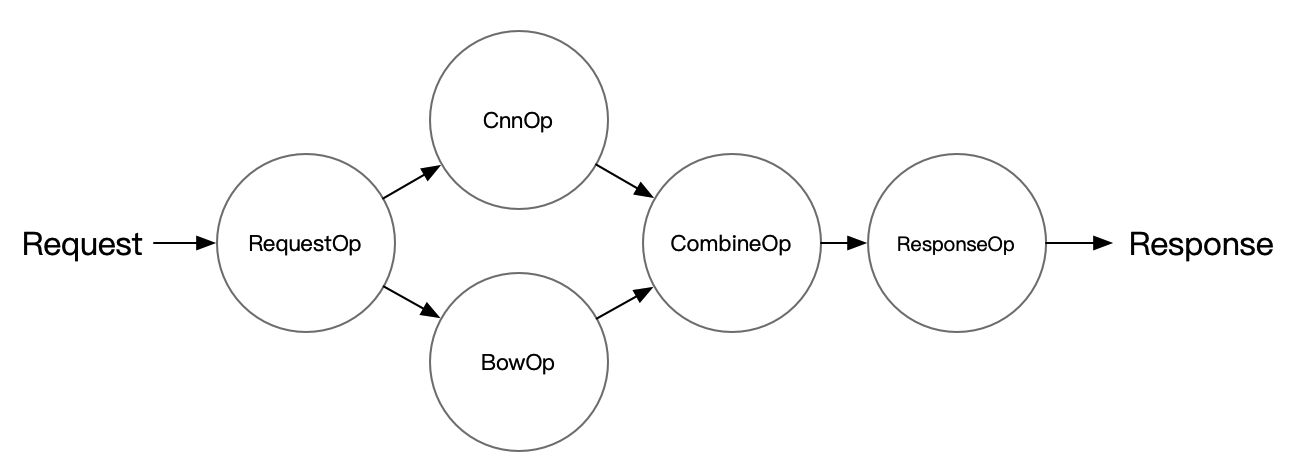
这里通过搭建简单的 imdb model ensemble 例子来展示如何使用 Pipeline Serving,相关代码在
`python/examples/pipeline/imdb_model_ensemble`
文件夹下可以找到,例子中的 Server 端结构如下图所示:
<center>
<img
src=
'pipeline_serving-image4.png'
height =
"200"
align=
"middle"
/>
</center>
### 获取模型文件并启动 Paddle Serving Service
```
shell
cd
python/examples/pipeline/imdb_model_ensemble
sh get_data.sh
python
-m
paddle_serving_server.serve
--model
imdb_cnn_model
--port
9292 &> cnn.log &
python
-m
paddle_serving_server.serve
--model
imdb_bow_model
--port
9393 &> bow.log &
```
### 启动 PipelineServer
运行下面代码
```
python
from
paddle_serving_server.pipeline
import
Op
,
RequestOp
,
ResponseOp
from
paddle_serving_server.pipeline
import
PipelineServer
from
paddle_serving_server.pipeline.proto
import
pipeline_service_pb2
from
paddle_serving_server.pipeline.channel
import
ChannelDataEcode
import
numpy
as
np
import
logging
from
paddle_serving_app.reader
import
IMDBDataset
logging
.
basicConfig
(
level
=
logging
.
DEBUG
)
_LOGGER
=
logging
.
getLogger
()
class
ImdbRequestOp
(
RequestOp
):
def
init_op
(
self
):
self
.
imdb_dataset
=
IMDBDataset
()
self
.
imdb_dataset
.
load_resource
(
'imdb.vocab'
)
def
unpack_request_package
(
self
,
request
):
dictdata
=
{}
for
idx
,
key
in
enumerate
(
request
.
key
):
if
key
!=
"words"
:
continue
words
=
request
.
value
[
idx
]
word_ids
,
_
=
self
.
imdb_dataset
.
get_words_and_label
(
words
)
dictdata
[
key
]
=
np
.
array
(
word_ids
)
return
dictdata
class
CombineOp
(
Op
):
def
preprocess
(
self
,
input_data
):
combined_prediction
=
0
for
op_name
,
data
in
input_data
.
items
():
_LOGGER
.
info
(
"{}: {}"
.
format
(
op_name
,
data
[
"prediction"
]))
combined_prediction
+=
data
[
"prediction"
]
data
=
{
"prediction"
:
combined_prediction
/
2
}
return
data
read_op
=
ImdbRequestOp
()
bow_op
=
Op
(
name
=
"bow"
,
input_ops
=
[
read_op
],
server_endpoints
=
[
"127.0.0.1:9393"
],
fetch_list
=
[
"prediction"
],
client_config
=
"imdb_bow_client_conf/serving_client_conf.prototxt"
,
concurrency
=
1
,
timeout
=-
1
,
retry
=
1
)
cnn_op
=
Op
(
name
=
"cnn"
,
input_ops
=
[
read_op
],
server_endpoints
=
[
"127.0.0.1:9292"
],
fetch_list
=
[
"prediction"
],
client_config
=
"imdb_cnn_client_conf/serving_client_conf.prototxt"
,
concurrency
=
1
,
timeout
=-
1
,
retry
=
1
)
combine_op
=
CombineOp
(
name
=
"combine"
,
input_ops
=
[
bow_op
,
cnn_op
],
concurrency
=
5
,
timeout
=-
1
,
retry
=
1
)
# use default ResponseOp implementation
response_op
=
ResponseOp
(
input_ops
=
[
combine_op
])
server
=
PipelineServer
()
server
.
set_response_op
(
response_op
)
server
.
prepare_server
(
'config.yml'
)
server
.
run_server
()
```
### 通过 PipelineClient 执行预测
```
python
from
paddle_serving_client.pipeline
import
PipelineClient
import
numpy
as
np
client
=
PipelineClient
()
client
.
connect
([
'127.0.0.1:18080'
])
words
=
'i am very sad | 0'
futures
=
[]
for
i
in
range
(
3
):
futures
.
append
(
client
.
predict
(
feed_dict
=
{
"words"
:
words
},
fetch
=
[
"prediction"
],
asyn
=
True
))
for
f
in
futures
:
res
=
f
.
result
()
if
res
[
"ecode"
]
!=
0
:
print
(
res
)
exit
(
1
)
```
doc/pipeline-img1.png
0 → 100644
浏览文件 @
bfa28abc
62.1 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}