fix conflict
Showing
core/sdk-cpp/include/macros.h
0 → 100644
doc/NEW_WEB_SERVICE.md
0 → 100644
doc/NEW_WEB_SERVICE_CN.md
0 → 100644
{kind=link}
{kind=link}
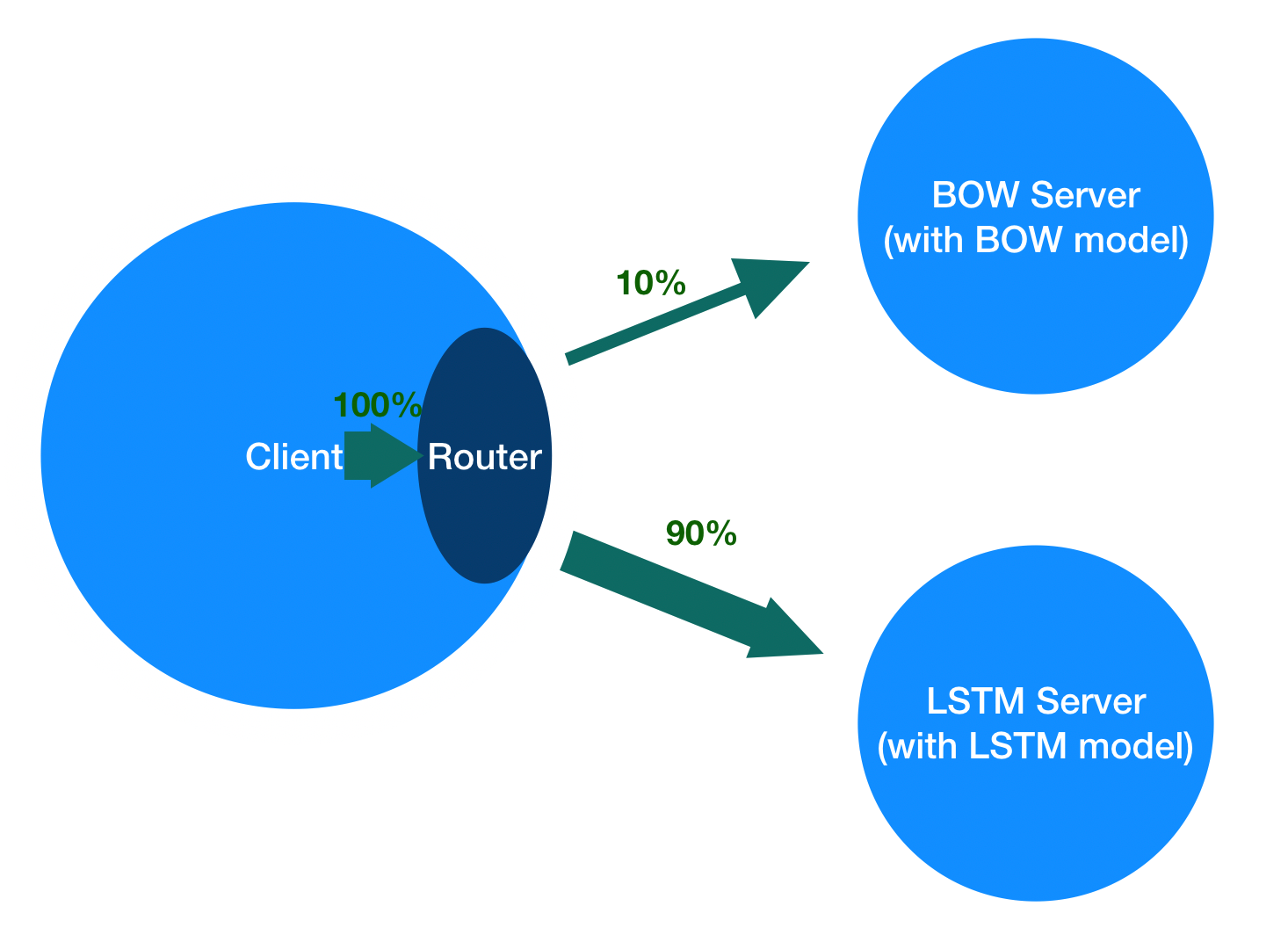
| W: | H:
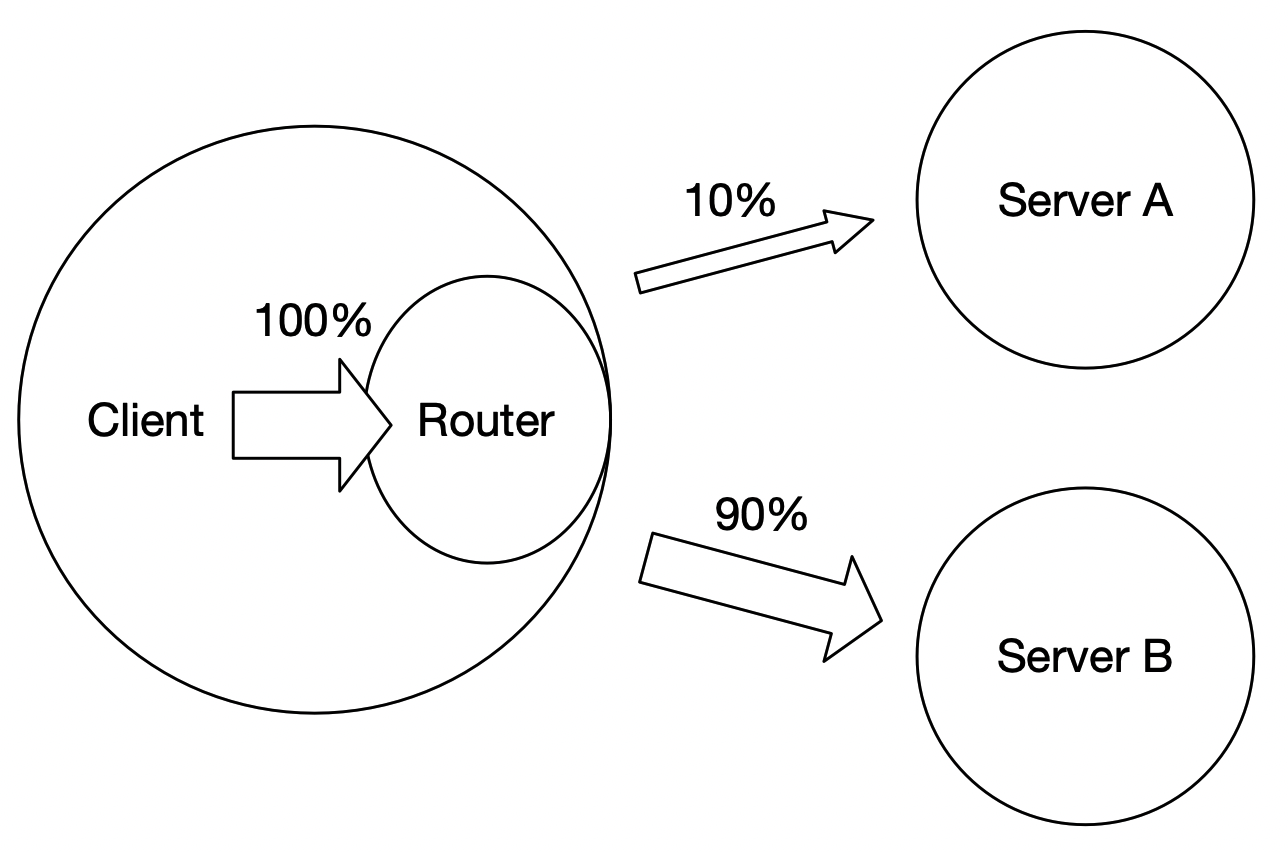
| W: | H:
python/examples/faster_rcnn_model/000000570688.jpg
100755 → 100644
{kind=link}
文件模式从 100755 更改为 100644