Merge pull request #769 from barrierye/pipeline-auto-batch
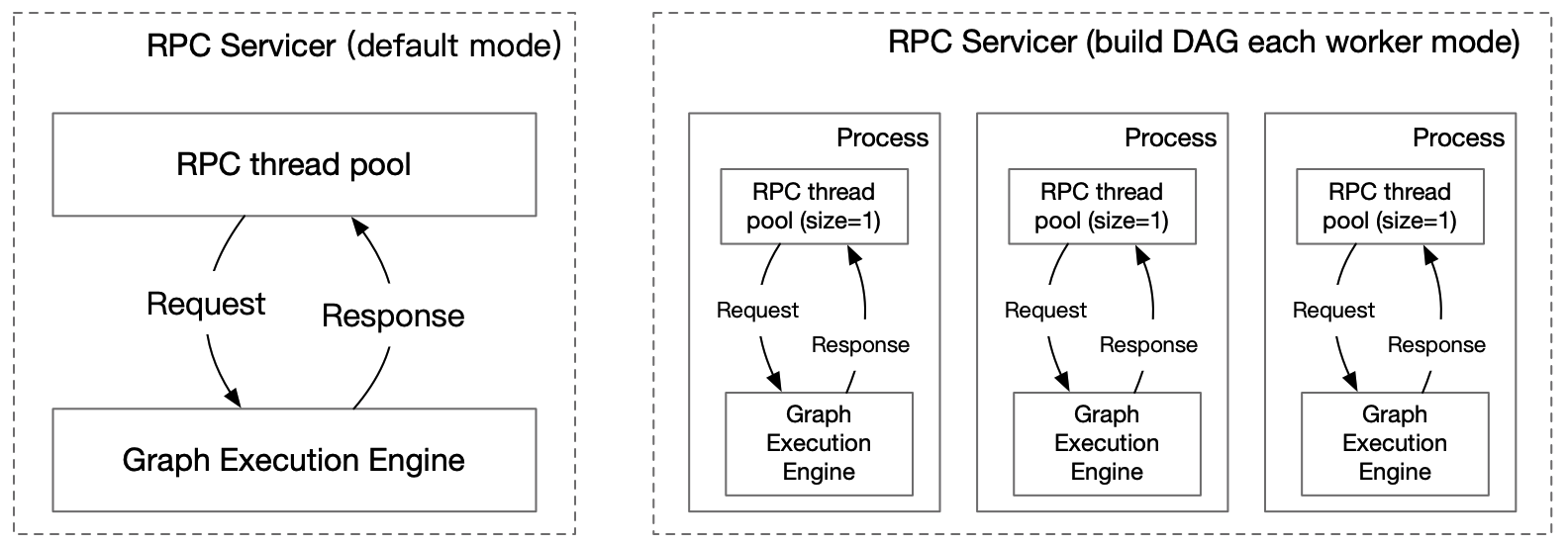
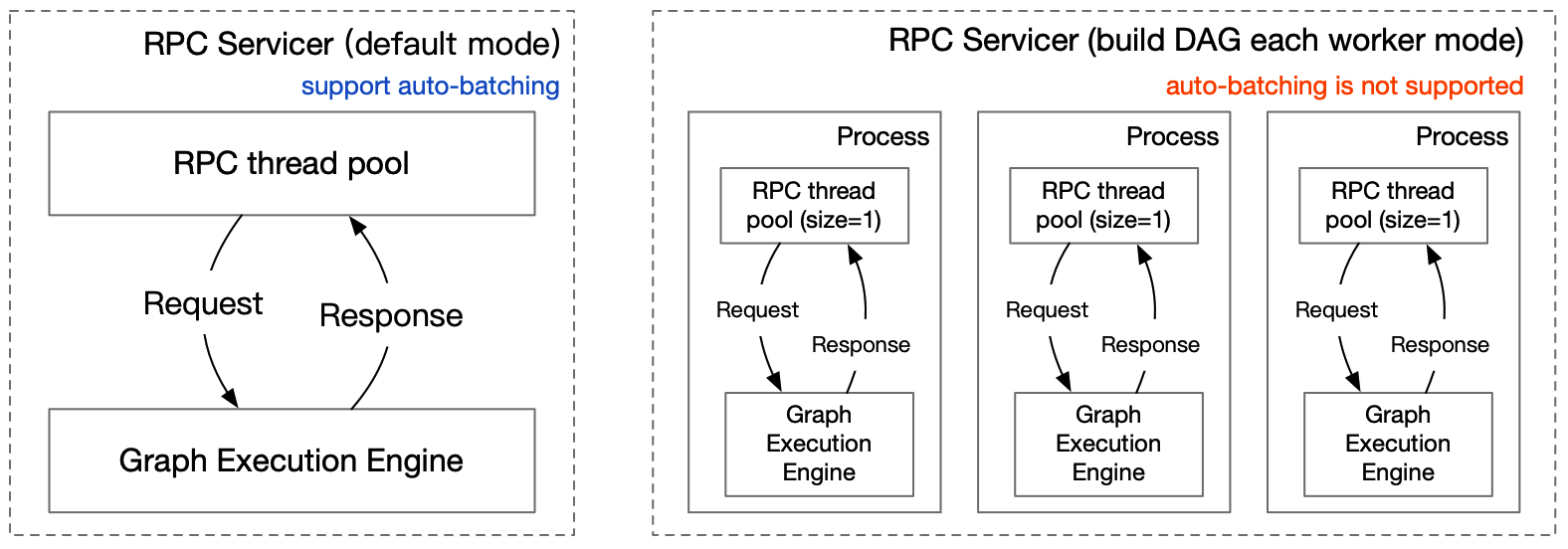
Pipeline Auto-batching feature & Update Log
Showing
文件已删除
{kind=link}
{kind=link}
| W: | H:
| W: | H:
python/pipeline/logger.py
0 → 100644
Pipeline Auto-batching feature & Update Log
| W: | H:
| W: | H: