Merge pull request #2 from PaddlePaddle/develop
merge with origin
Showing
.travis.yml
0 → 100644
README_CN.md
0 → 100644
core/predictor/tools/seq_file.cpp
0 → 100644
core/predictor/tools/seq_file.h
0 → 100644
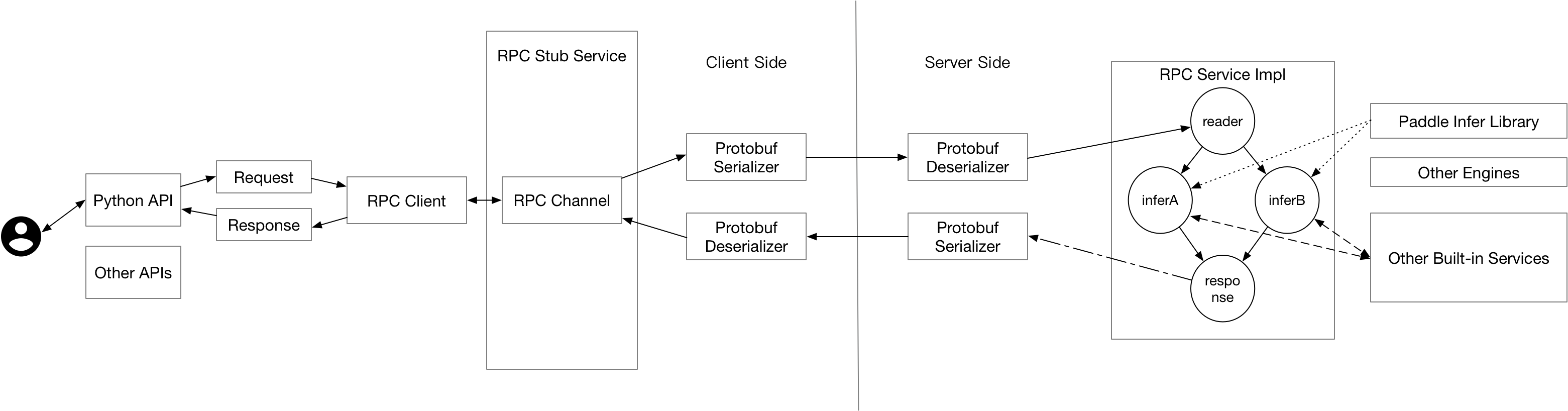
doc/DESIGN_DOC.md
0 → 100644
doc/DESIGN_DOC_EN.md
0 → 100644
doc/RUN_IN_DOCKER.md
0 → 100644
doc/RUN_IN_DOCKER_CN.md
0 → 100644
doc/SAVE.md
0 → 100644
{kind=link}
24.2 KB
doc/blank.png
0 → 100644
{kind=link}

18.2 KB
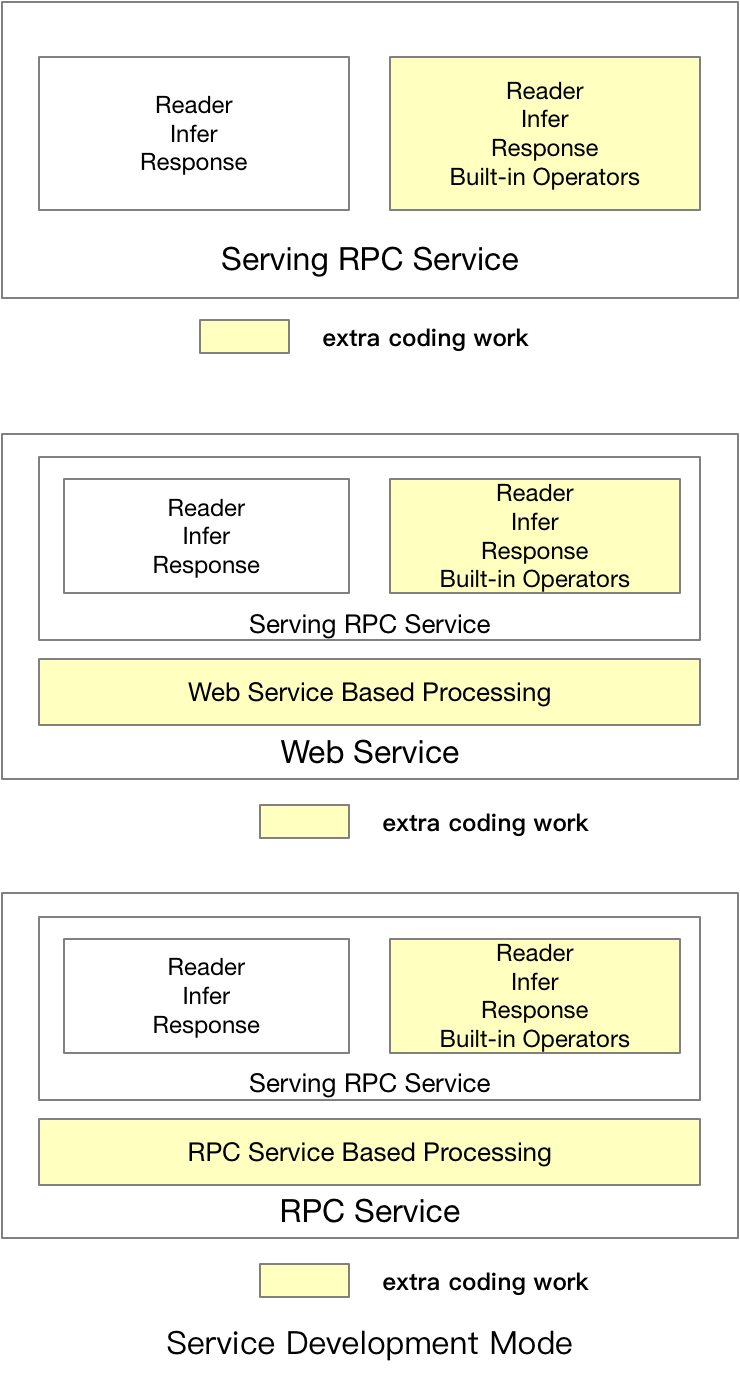
doc/coding_mode.png
0 → 100644
{kind=link}
126.6 KB
{kind=link}
66.0 KB
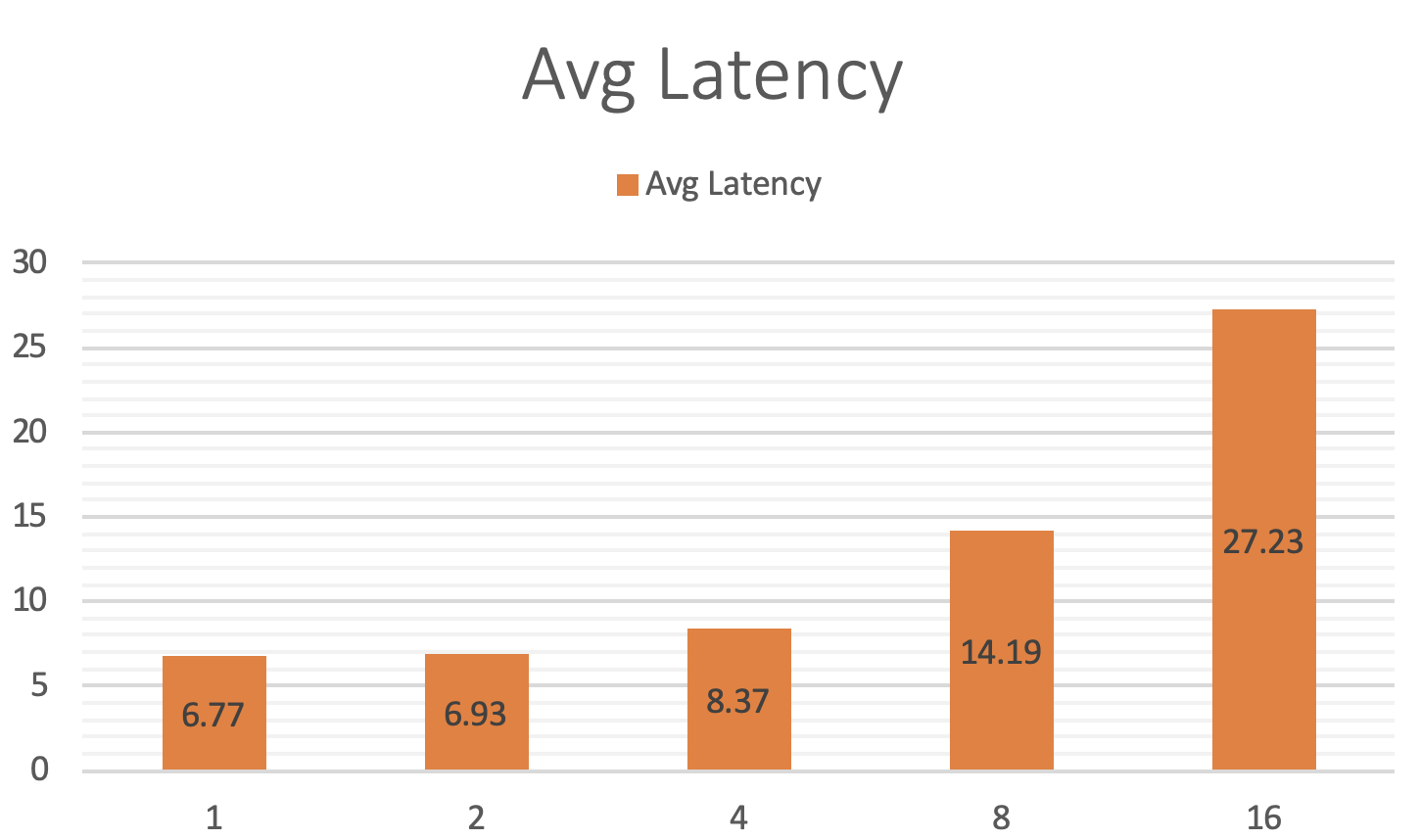
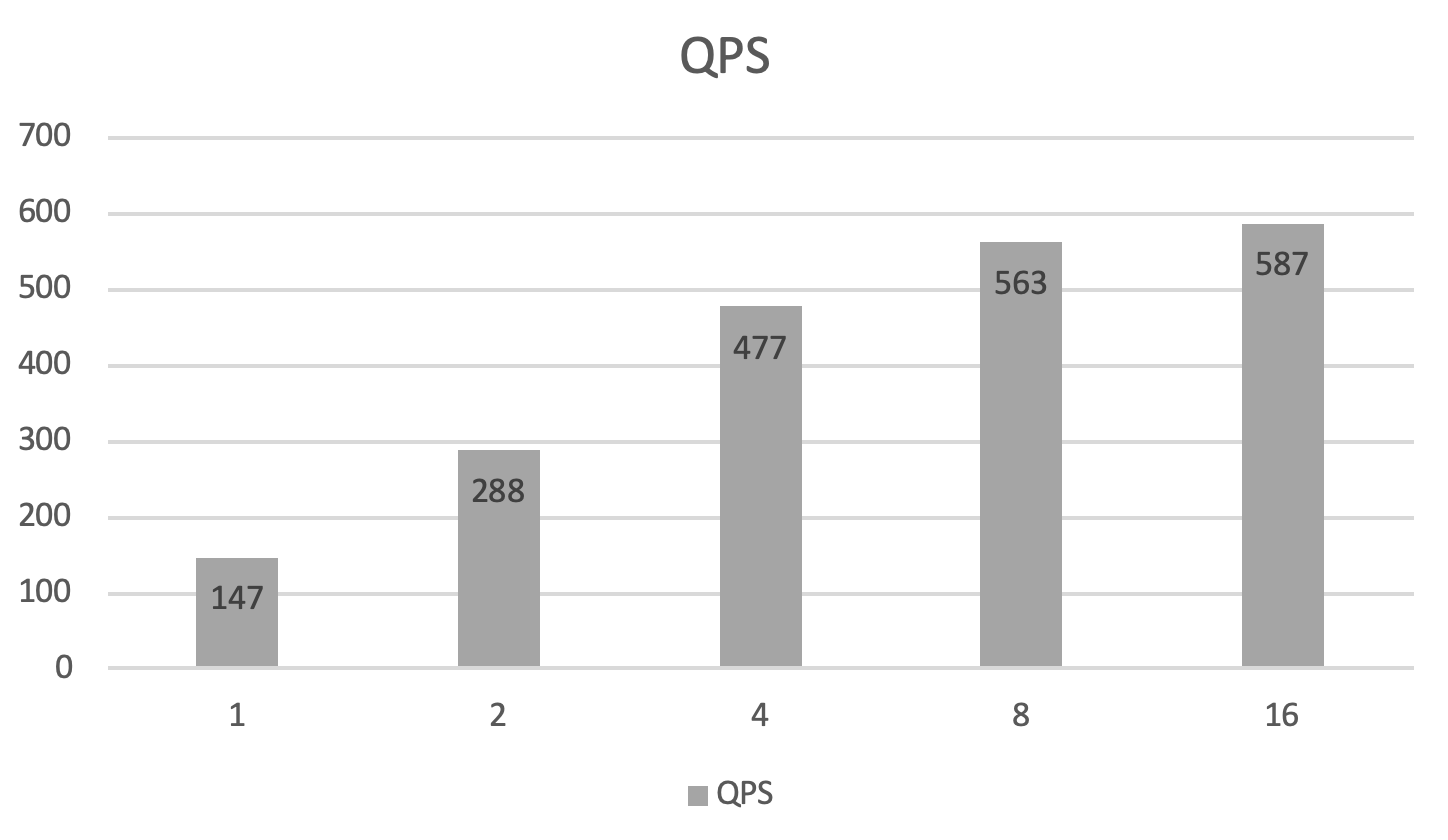
doc/criteo-cube-benchmark-qps.png
0 → 100644
{kind=link}
54.4 KB
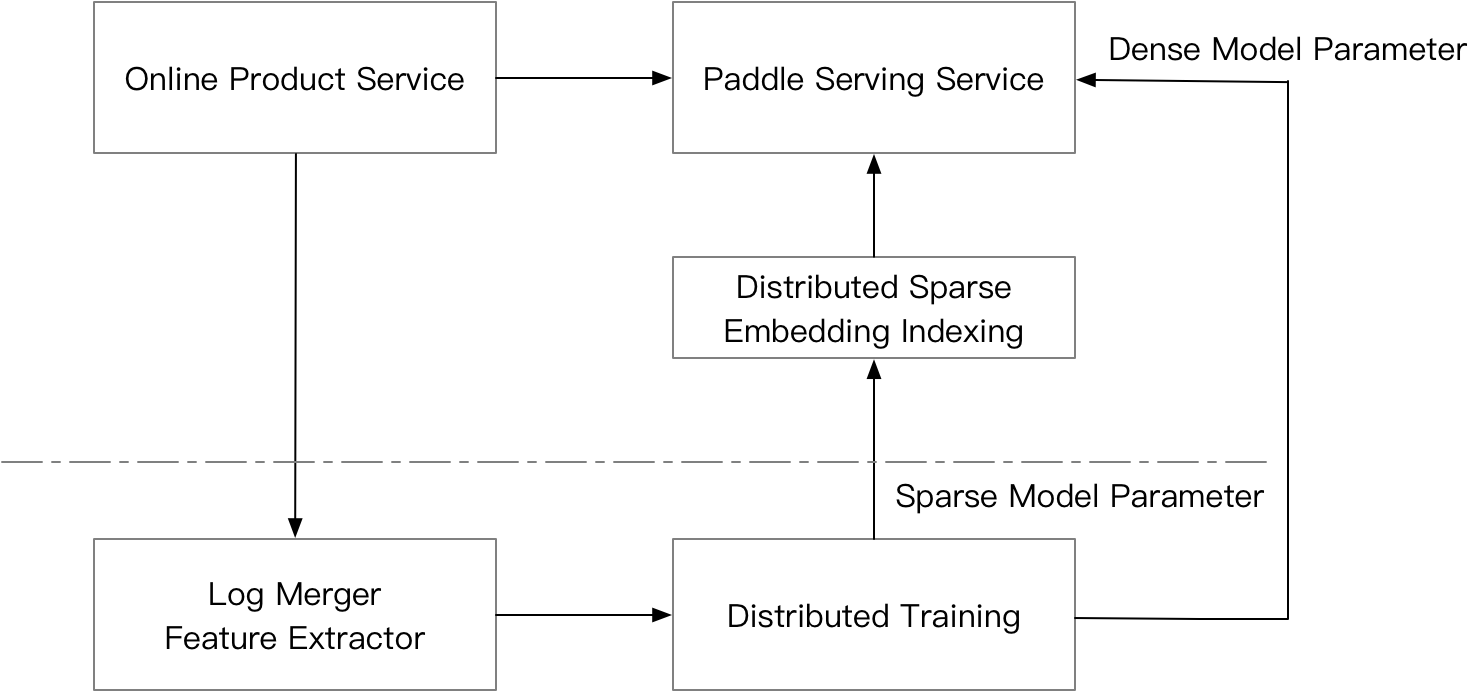
doc/cube.png
0 → 100644
{kind=link}

62.2 KB
doc/cube_eng.png
0 → 100644
{kind=link}
72.2 KB
doc/demo.gif
0 → 100644
{kind=link}

514.9 KB
doc/design_doc.png
0 → 100644
{kind=link}
182.3 KB
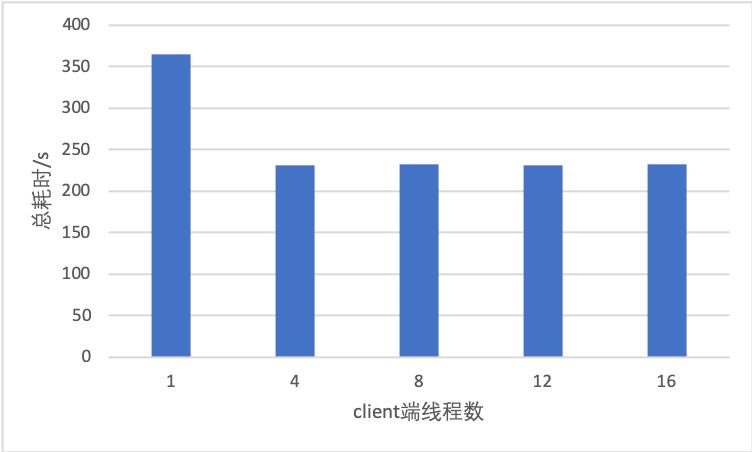
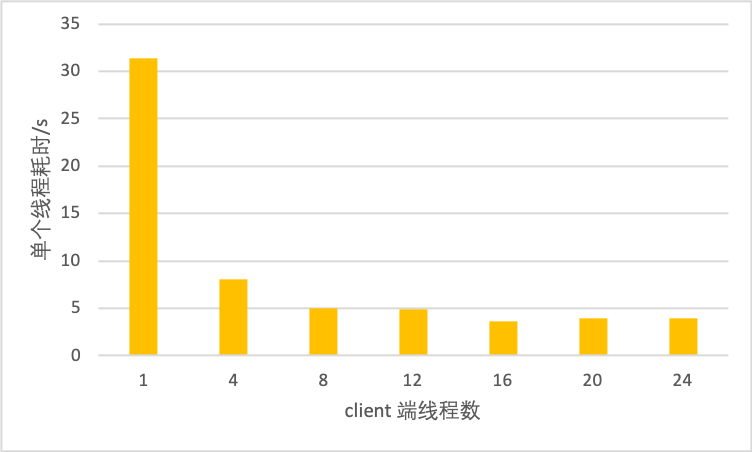
doc/imdb-benchmark-server-16.png
0 → 100644
{kind=link}
24.3 KB
doc/user_groups.png
0 → 100644
{kind=link}

265.4 KB
python/examples/bert/README.md
0 → 100644
python/examples/bert/batching.py
0 → 100644
python/examples/bert/benchmark.py
0 → 100644
python/examples/bert/benchmark.sh
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/examples/bert/get_data.sh
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/examples/imdb/benchmark.sh
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/examples/lac/get_data.sh
0 → 100644
此差异已折叠。
python/examples/lac/lac_client.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/examples/lac/lac_reader.py
0 → 100644
此差异已折叠。
此差异已折叠。
python/examples/lac/utils.py
0 → 100644
此差异已折叠。
python/examples/util/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/Dockerfile.ci
0 → 100644
此差异已折叠。
tools/Dockerfile.devel
0 → 100644
此差异已折叠。
此差异已折叠。
tools/Dockerfile.gpu.devel
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/serving_build.sh
0 → 100644
此差异已折叠。
tools/serving_check_style.sh
0 → 100644
此差异已折叠。