Merge branch 'develop' of https://github.com/PaddlePaddle/Serving into gpu-devel-dockerfile
Showing
doc/DESIGN_DOC.md
0 → 100644
doc/blank.png
0 → 100644
{kind=link}

18.2 KB
doc/coding_mode.png
0 → 100644
{kind=link}
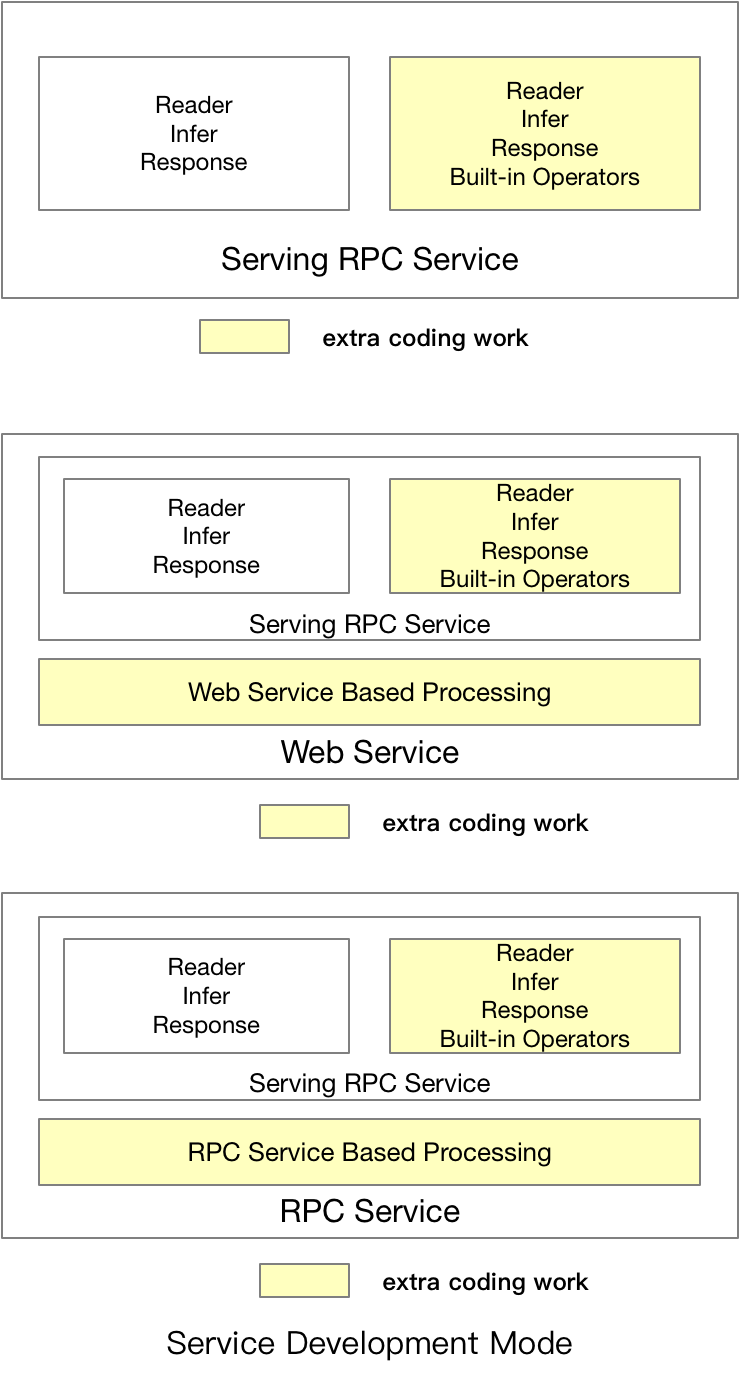
126.6 KB
doc/user_groups.png
0 → 100644
{kind=link}
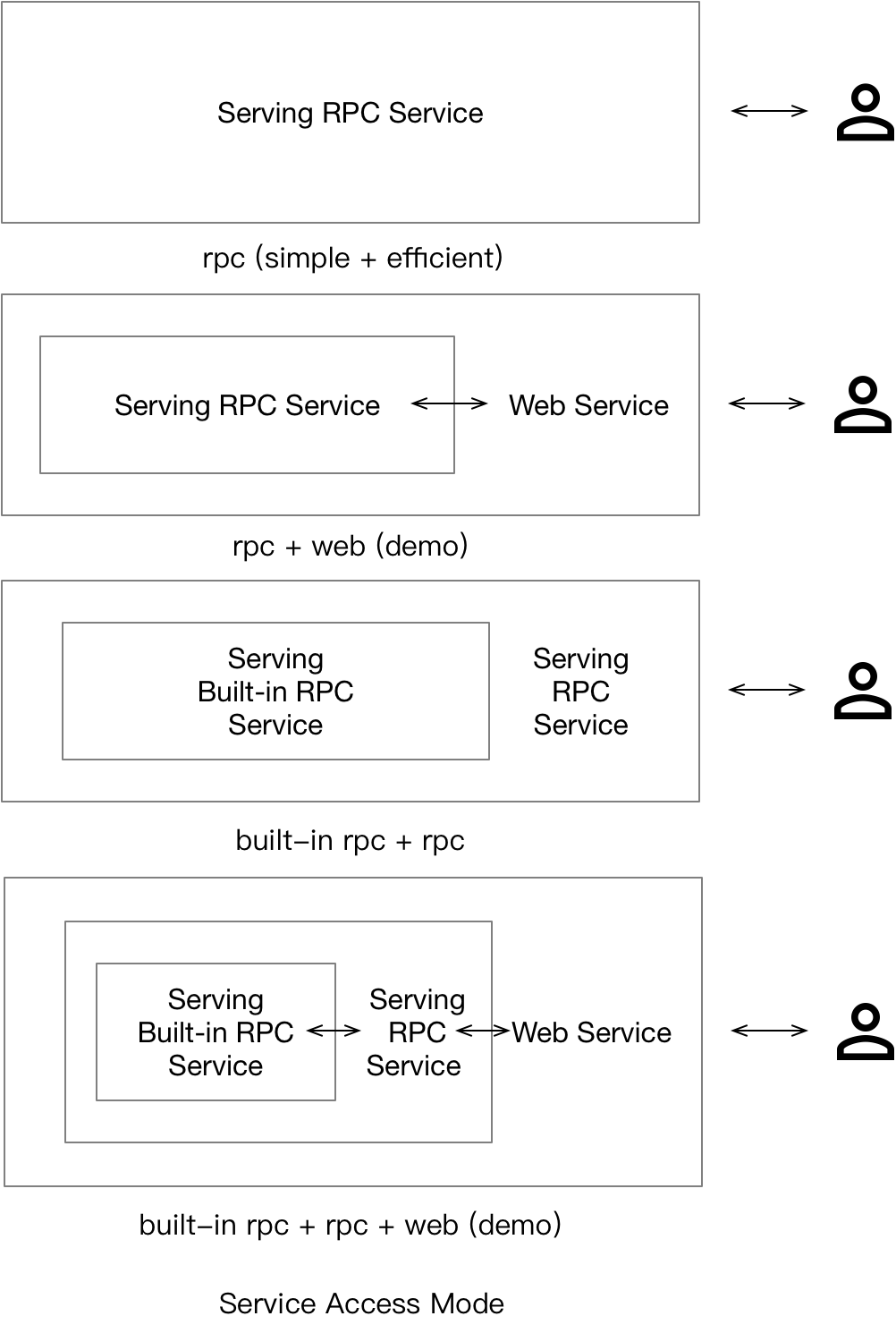
114.8 KB