Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
a3786b87
S
Serving
项目概览
PaddlePaddle
/
Serving
大约 2 年 前同步成功
通知
187
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
a3786b87
编写于
5月 23, 2022
作者:
S
ShiningZhang
提交者:
GitHub
5月 23, 2022
浏览文件
操作
浏览文件
下载
差异文件
Merge pull request #1733 from ShiningZhang/dev-doc
update Offical_doc
上级
00d2d9d1
2a1eb8a5
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
592 addition
and
0 deletion
+592
-0
doc/Offical_Docs/5-3_Serving_Configure_CN.md
doc/Offical_Docs/5-3_Serving_Configure_CN.md
+458
-0
doc/Offical_Docs/8-0_Cube_CN.md
doc/Offical_Docs/8-0_Cube_CN.md
+27
-0
doc/Offical_Docs/8-1_Cube_Architecture_CN.md
doc/Offical_Docs/8-1_Cube_Architecture_CN.md
+38
-0
doc/Offical_Docs/8-2_Cube_Compile_CN.md
doc/Offical_Docs/8-2_Cube_Compile_CN.md
+69
-0
doc/Offical_Docs/images/8-1_Cube_Architecture_CN_1.png
doc/Offical_Docs/images/8-1_Cube_Architecture_CN_1.png
+0
-0
未找到文件。
doc/Offical_Docs/5-3_Serving_Configure_CN.md
0 → 100644
浏览文件 @
a3786b87
# Serving 配置
## 简介
本文主要介绍 C++ Serving 以及 Python Pipeline 的各项配置:
-
[
模型配置文件
](
#模型配置文件
)
: 转换模型时自动生成,描述模型输入输出信息
-
[
C++ Serving
](
#c-serving
)
: 用于高性能场景,介绍了快速启动以及自定义配置方法
-
[
Python Pipeline
](
#python-pipeline
)
: 用于单算子多模型组合场景
## 模型配置文件
在开始介绍 Server 配置之前,先来介绍一下模型配置文件。我们在将模型转换为 PaddleServing 模型时,会生成对应的 serving_client_conf.prototxt 以及 serving_server_conf.prototxt,两者内容一致,为模型输入输出的参数信息,方便用户拼装参数。该配置文件用于 Server 以及 Client,并不需要用户自行修改。转换方法参考文档《
[
怎样保存用于Paddle Serving的模型
](
./Save_CN.md
)
》。protobuf 格式可参考
`core/configure/proto/general_model_config.proto`
。
样例如下:
```
feed_var {
name: "x"
alias_name: "x"
is_lod_tensor: false
feed_type: 1
shape: 13
}
fetch_var {
name: "concat_1.tmp_0"
alias_name: "concat_1.tmp_0"
is_lod_tensor: false
fetch_type: 1
shape: 3
shape: 640
shape: 640
}
```
其中
-
feed_var:模型输入
-
fetch_var:模型输出
-
name:名称
-
alias_name:别名,与名称对应
-
is_lod_tensor:是否为 lod,具体可参考《
[
Lod字段说明
](
./LOD_CN.md
)
》
-
feed_type:数据类型,详见表格
-
shape:数据维度
| feet_type | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 20 |
|-----------|-------|---------|-------|-------|------|------|-------|-------|-----|--------|
| 类型 | INT64 | FLOAT32 | INT32 | FP64 | INT16 | FP16 | BF16 | UINT8 | INT8 | STRING |
## C++ Serving
**一. 快速启动与关闭**
可以通过配置模型及端口号快速启动服务,启动命令如下:
```
BASH
python3 -m paddle_serving_server.serve --model serving_model --port 9393
```
该命令会自动生成配置文件,并使用生成的配置文件启动 C++ Serving。例如上述启动命令会自动生成 workdir_9393 目录,其结构如下
```
workdir_9393
├── general_infer_0
│ ├── fluid_time_file
│ ├── general_model.prototxt
│ └── model_toolkit.prototxt
├── infer_service.prototxt
├── resource.prototxt
└── workflow.prototxt
```
更多启动参数详见下表:
| Argument | Type | Default | Description |
| ---------------------------------------------- | ---- | ------- | ----------------------------------------------------- |
|
`thread`
| int |
`2`
| BRPC 服务的线程数 |
|
`runtime_thread_num`
| int[]|
`0`
| 异步模式下每个模型的线程数 |
|
`batch_infer_size`
| int[]|
`32`
| 异步模式下每个模型的 Batch 数 |
|
`gpu_ids`
| str[]|
`"-1"`
| 设置每个模型的 GPU id,例如当使用多卡部署时,可设置 "0,1,2" |
|
`port`
| int |
`9292`
| 服务的端口号 |
|
`model`
| str[]|
`""`
| 模型文件路径,例如包含两个模型时,可设置 "serving_model_1 serving_model_2" |
|
`mem_optim_off`
| - | - | 是否关闭内存优化选项 |
|
`ir_optim`
| bool | False | 是否开启图优化 |
|
`use_mkl`
(Only for cpu version) | - | - | 开启 MKL 选项,需要与 ir_optim 配合使用 |
|
`use_trt`
(Only for trt version) | - | - | 开启 TensorRT,需要与 ir_optim 配合使用 |
|
`use_lite`
(Only for Intel x86 CPU or ARM CPU) | - | - | 开启 PaddleLite,需要与 ir_optim 配合使用 |
|
`use_xpu`
| - | - | 开启百度昆仑 XPU 配置,需要与 ir_optim 配合使用 |
|
`precision`
| str | FP32 | 精度配置,支持 FP32, FP16, INT8 |
|
`use_calib`
| bool | False | 是否开启 TRT int8 校准模式 |
|
`gpu_multi_stream`
| bool | False | 是否开启 GPU 多流模式 |
|
`use_ascend_cl`
| bool | False | 开启昇腾配置,单独开启时适配 910,与 use_lite 共同开启时适配 310 |
|
`request_cache_size`
| int |
`0`
| 请求缓存的容量大小。默认为 0 时,缓存关闭 |
**二. 自定义配置启动**
一般情况下,自动生成的配置可以应对大部分场景。对于特殊场景,用户也可自行定义配置文件。这些配置文件包括 service.prototxt(配置服务列表)、workflow.prototxt(配置 OP 流程 workflow)、resource.prototxt(指定模型配置文件)、model_toolkit.prototxt(配置模型信息和预测引擎)、proj.conf(配置服务参数)。启动命令如下:
```
BASH
/bin/serving --flagfile=proj.conf
```
1.
proj.conf
proj.conf 用于传入服务参数,并指定了其他相关配置文件的路径。如果重复传入参数,则以最后序参数值为准。
```
# for paddle inference
--precision=fp32
--use_calib=False
--reload_interval_s=10
# for brpc
--max_concurrency=0
--num_threads=10
--bthread_concurrency=10
--max_body_size=536870912
# default path
--inferservice_path=conf
--inferservice_file=infer_service.prototxt
--resource_path=conf
--resource_file=resource.prototxt
--workflow_path=conf
--workflow_file=workflow.prototxt
```
各项参数的描述及默认值详见下表:
| name | Default | Description |
|------|--------|------|
|precision|"fp32"|Precision Mode, support FP32, FP16, INT8|
|use_calib|False|Only for deployment with TensorRT|
|reload_interval_s|10|Reload interval|
|max_concurrency|0|Limit of request processing in parallel, 0: unlimited|
|num_threads|10|Number of brpc service thread|
|bthread_concurrency|10|Number of bthread|
|max_body_size|536870912|Max size of brpc message|
|inferservice_path|"conf"|Path of inferservice conf|
|inferservice_file|"infer_service.prototxt"|Filename of inferservice conf|
|resource_path|"conf"|Path of resource conf|
|resource_file|"resource.prototxt"|Filename of resource conf|
|workflow_path|"conf"|Path of workflow conf|
|workflow_file|"workflow.prototxt"|Filename of workflow conf|
2.
service.prototxt
service.prototxt 用于配置 Paddle Serving 实例挂载的 service 列表。通过
`--inferservice_path`
和
`--inferservice_file`
指定加载路径。protobuf 格式可参考
`core/configure/server_configure.protobuf`
的
`InferServiceConf`
。示例如下:
```
port: 8010
services {
name: "GeneralModelService"
workflows: "workflow1"
}
```
其中:
-
port: 用于配置 Serving 实例监听的端口号。
-
services: 使用默认配置即可,不可修改。name 指定 service 名称,workflow1 的具体定义在 workflow.prototxt
3.
workflow.prototxt
workflow.prototxt 用来描述具体的 workflow。通过
`--workflow_path`
和
`--workflow_file`
指定加载路径。protobuf 格式可参考
`configure/server_configure.protobuf`
的
`Workflow`
类型。自定义 OP 请参考
[
自定义OP
](
)
如下示例,workflow 由3个 OP 构成,GeneralReaderOp 用于读取数据,GeneralInferOp 依赖于 GeneralReaderOp 并进行预测,GeneralResponseOp 将预测结果返回:
```
workflows {
name: "workflow1"
workflow_type: "Sequence"
nodes {
name: "general_reader_0"
type: "GeneralReaderOp"
}
nodes {
name: "general_infer_0"
type: "GeneralInferOp"
dependencies {
name: "general_reader_0"
mode: "RO"
}
}
nodes {
name: "general_response_0"
type: "GeneralResponseOp"
dependencies {
name: "general_infer_0"
mode: "RO"
}
}
}
```
其中:
-
name: workflow 名称,用于从 service.prototxt 索引到具体的 workflow
-
workflow_type: 只支持 "Sequence"
-
nodes: 用于串联成 workflow 的所有节点,可配置多个 nodes。nodes 间通过配置 dependencies 串联起来
-
node.name: 与 node.type 一一对应,具体可参考
`python/paddle_serving_server/dag.py`
-
node.type: 当前 node 所执行 OP 的类名称,与 serving/op/ 下每个具体的 OP 类的名称对应
-
node.dependencies: 依赖的上游 node 列表
-
node.dependencies.name: 与 workflow 内节点的 name 保持一致
-
node.dependencies.mode: RO-Read Only, RW-Read Write
4.
resource.prototxt
resource.prototxt,用于指定模型配置文件。通过
`--resource_path`
和
`--resource_file`
指定加载路径。它的 protobuf 格式参考
`core/configure/proto/server_configure.proto`
的
`ResourceConf`
。示例如下:
```
model_toolkit_path: "conf"
model_toolkit_file: "general_infer_0/model_toolkit.prototxt"
general_model_path: "conf"
general_model_file: "general_infer_0/general_model.prototxt"
```
其中:
-
model_toolkit_path: 用来指定 model_toolkit.prototxt 所在的目录
-
model_toolkit_file: 用来指定 model_toolkit.prototxt 所在的文件名
-
general_model_path: 用来指定 general_model.prototxt 所在的目录
-
general_model_file: 用来指定 general_model.prototxt 所在的文件名
5.
model_toolkit.prototxt
用来配置模型信息和预测引擎。它的 protobuf 格式参考
`core/configure/proto/server_configure.proto`
的 ModelToolkitConf。model_toolkit.protobuf 的磁盘路径不能通过命令行参数覆盖。示例如下:
```
engines {
name: "general_infer_0"
type: "PADDLE_INFER"
reloadable_meta: "uci_housing_model/fluid_time_file"
reloadable_type: "timestamp_ne"
model_dir: "uci_housing_model"
gpu_ids: -1
enable_memory_optimization: true
enable_ir_optimization: false
use_trt: false
use_lite: false
use_xpu: false
use_gpu: false
combined_model: false
gpu_multi_stream: false
use_ascend_cl: false
runtime_thread_num: 0
batch_infer_size: 32
enable_overrun: false
allow_split_request: true
}
```
其中
-
name: 引擎名称,与 workflow.prototxt 中的 node.name 以及所在目录名称对应
-
type: 预测引擎的类型。当前只支持 ”PADDLE_INFER“
-
reloadable_meta: 目前实际内容无意义,用来通过对该文件的 mtime 判断是否超过 reload 时间阈值
-
reloadable_type: 检查 reload 条件:timestamp_ne/timestamp_gt/md5sum/revision/none,详见表格
-
model_dir: 模型文件路径
-
gpu_ids: 引擎运行时使用的 GPU device id,支持指定多个,如:
-
enable_memory_optimization: 是否开启 memory 优化
-
enable_ir_optimization: 是否开启 ir 优化
-
use_trt: 是否开启 TensorRT,需同时开启 use_gpu
-
use_lite: 是否开启 PaddleLite
-
use_xpu: 是否使用昆仑 XPU
-
use_gpu: 是否使用 GPU
-
combined_model: 是否使用组合模型文件
-
gpu_multi_stream: 是否开启 gpu 多流模式
-
use_ascend_cl: 是否使用昇腾,单独开启适配昇腾 910,同时开启 lite 适配 310
-
runtime_thread_num: 若大于 0, 则启用 Async 异步模式,并创建对应数量的 predictor 实例。
-
batch_infer_size: Async 异步模式下的最大 batch 数
-
enable_overrun: Async 异步模式下总是将整个任务放入任务队列
-
allow_split_request: Async 异步模式下允许拆分任务
|reloadable_type|含义|
|---------------|----|
|timestamp_ne|reloadable_meta 所指定文件的 mtime 时间戳发生变化|
|timestamp_gt|reloadable_meta 所指定文件的 mtime 时间戳大于等于上次检查时记录的 mtime 时间戳|
|md5sum|目前无用,配置后永远不 reload|
|revision|目前无用,配置后用于不 reload|
6.
general_model.prototxt
general_model.prototxt 内容与模型配置 serving_server_conf.prototxt 相同,用了描述模型输入输出参数信息。
## Python Pipeline
**一. 快速启动与关闭**
Python Pipeline 启动脚本如下,脚本实现请参考
[
Pipeline Serving
](
):
```
BASH
python3 web_service.py
```
当您想要关闭 Serving 服务时(在 Pipeline 启动目录下或环境变量 SERVING_HOME 路径下,执行以下命令)可以如下命令,
stop 参数发送 SIGINT 至 Pipeline Serving,若 Linux 系统中改成 kill 则发送 SIGKILL 信号至 Pipeline Serving
```
BASH
python3 -m paddle_serving_server.serve stop
```
**二. 配置文件**
Python Pipeline 提供了用户友好的多模型组合服务编程框架,适用于多模型组合应用的场景。
其配置文件为 YAML 格式,一般默认为 config.yaml。示例如下:
```
YAML
rpc_port: 18090
http_port: 9999
worker_num: 20
build_dag_each_worker: false
```
| Argument | Type | Default | Description |
| ---------------------------------------------- | ---- | ------- | ----------------------------------------------------- |
|
`rpc_port`
| int |
`18090`
| rpc 端口, rpc_port 和 http_port 不允许同时为空。当 rpc_port 为空且 http_port 不为空时,会自动将 rpc_port 设置为 http_port+1 |
|
`http_port`
| int|
`9999`
| http 端口, rpc_port 和 http_port 不允许同时为空。当 rpc_port 可用且 http_port 为空时,不自动生成 http_port |
|
`worker_num`
| int|
`20`
| worker_num, 最大并发数。当 build_dag_each_worker=True 时, 框架会创建w orker_num 个进程,每个进程内构建 grpcSever和DAG,当 build_dag_each_worker=False 时,框架会设置主线程 grpc 线程池的 max_workers=worker_num |
|
`build_dag_each_worker`
| bool|
`false`
| False,框架在进程内创建一条 DAG;True,框架会每个进程内创建多个独立的 DAG |
```
YAML
dag:
is_thread_op: False
retry: 1
use_profile: false
tracer:
interval_s: 10
client_type: local_predictor
channel_size: 0
channel_recv_frist_arrive: False
```
| Argument | Type | Default | Description |
| ---------------------------------------------- | ---- | ------- | ----------------------------------------------------- |
|
`is_thread_op`
| bool |
`false`
| op 资源类型, True, 为线程模型;False,为进程模型 |
|
`retry`
| int |
`1`
| 重试次数 |
|
`use_profile`
| bool |
`false`
| 使用性能分析, True,生成 Timeline 性能数据,对性能有一定影响;False 为不使用 |
|
`tracer:interval_s`
| int |
`10 `
| rpc 端口, rpc_port 和 http_port 不允许同时为空。当 rpc_port 为空且 http_port 不为空时,会自动将 rpc_port 设置为 http_port+1 |
|
`client_type`
| string |
`local_predictor`
| client 类型,包括 brpc, grpc 和 local_predictor.local_predictor 不启动 Serving 服务,进程内预测 |
|
`channel_size`
| int |
`0`
| channel 的最大长度,默认为0 |
|
`channel_recv_frist_arrive`
| bool |
`false`
| 针对大模型分布式场景 tensor 并行,接收第一个返回结果后其他结果丢弃来提供速度 |
```
YAML
op:
op1:
#并发数,is_thread_op=True 时,为线程并发;否则为进程并发
concurrency: 6
#Serving IPs
#server_endpoints: ["127.0.0.1:9393"]
#Fetch 结果列表,以 client_config 中 fetch_var 的 alias_name 为准
#fetch_list: ["concat_1.tmp_0"]
#det 模型 client 端配置
#client_config: serving_client_conf.prototxt
#Serving 交互超时时间, 单位 ms
#timeout: 3000
#Serving 交互重试次数,默认不重试
#retry: 1
# 批量查询 Serving 的数量, 默认 1。batch_size>1 要设置 auto_batching_timeout,否则不足 batch_size 时会阻塞
#batch_size: 2
# 批量查询超时,与 batch_size 配合使用
#auto_batching_timeout: 2000
#当 op 配置没有 server_endpoints 时,从 local_service_conf 读取本地服务配置
local_service_conf:
#client 类型,包括 brpc, grpc 和 local_predictor.local_predictor 不启动 Serving 服务,进程内预测
client_type: local_predictor
#det 模型路径
model_config: ocr_det_model
#Fetch 结果列表,以 client_config 中 fetch_var 的 alias_name 为准
fetch_list: ["concat_1.tmp_0"]
# device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu, 5=arm ascend310, 6=arm ascend910
device_type: 0
#计算硬件 ID,当 devices 为""或不写时为 CPU 预测;当 devices 为 "0", "0,1,2" 时为 GPU 预测,表示使用的 GPU 卡
devices: ""
#use_mkldnn, 开启 mkldnn 时,必须同时设置 ir_optim=True,否则无效
#use_mkldnn: True
#ir_optim, 开启 TensorRT 时,必须同时设置 ir_optim=True,否则无效
ir_optim: True
#CPU 计算线程数,在 CPU 场景开启会降低单次请求响应时长
#thread_num: 10
#precsion, 预测精度,降低预测精度可提升预测速度
#GPU 支持: "fp32"(default), "fp16", "int8";
#CPU 支持: "fp32"(default), "fp16", "bf16"(mkldnn); 不支持: "int8"
precision: "fp32"
#mem_optim, memory / graphic memory optimization
#mem_optim: True
#use_calib, Use TRT int8 calibration
#use_calib: False
#The cache capacity of different input shapes for mkldnn
#mkldnn_cache_capacity: 0
#mkldnn_op_list, op list accelerated using MKLDNN, None default
#mkldnn_op_list: []
#mkldnn_bf16_op_list,op list accelerated using MKLDNN bf16, None default.
#mkldnn_bf16_op_list: []
#min_subgraph_size,the minimal subgraph size for opening tensorrt to optimize, 3 default
#min_subgraph_size: 3
```
| Argument | Type | Default | Description |
| ---------------------------------------------- | ---- | ------- | ----------------------------------------------------- |
|
`concurrency`
| int |
`6`
| 并发数,is_thread_op=True 时,为线程并发;否则为进程并发 |
|
`server_endpoints`
| list |
`-`
| 服务 IP 列表 |
|
`fetch_list`
| list |
`-`
| Fetch 结果列表,以 client_config 中 fetch_var 的 alias_name 为准 |
|
`client_config`
| string |
`-`
| 模型 client 端配置 |
|
`timeout`
| int |
`3000`
| Serving 交互超时时间, 单位 ms |
|
`retry`
| int |
`1`
| Serving 交互重试次数,默认不重试 |
|
`batch_size`
| int |
`1`
| 批量查询 Serving 的数量, 默认 1。batch_size>1 要设置 auto_batching_timeout,否则不足 batch_size 时会阻塞 |
|
`auto_batching_timeout`
| int |
`2000`
| 批量查询超时,与 batch_size 配合使用 |
|
`local_service_conf`
| map |
`-`
| 当 op 配置没有 server_endpoints 时,从 local_service_conf 读取本地服务配置 |
|
`client_type`
| string |
`-`
| client 类型,包括 brpc, grpc 和 local_predictor.local_predictor 不启动 Serving 服务,进程内预测 |
|
`model_config`
| string |
`-`
| 模型路径 |
|
`fetch_list`
| list |
`-`
| Fetch 结果列表,以 client_config 中 fetch_var 的 alias_name 为准 |
|
`device_type`
| int |
`0`
| 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu, 5=arm ascend310, 6=arm ascend910 |
|
`devices`
| string |
`-`
| 计算硬件 ID,当 devices 为""或不写时为 CPU 预测;当 devices 为 "0", "0,1,2" 时为 GPU 预测,表示使用的 GPU 卡 |
|
`use_mkldnn`
| bool |
`True`
| use_mkldnn, 开启 mkldnn 时,必须同时设置 ir_optim=True,否则无效|
|
`ir_optim`
| bool |
`True`
| 开启 TensorRT 时,必须同时设置 ir_optim=True,否则无效 |
|
`thread_num`
| int |
`10`
| CPU 计算线程数,在 CPU 场景开启会降低单次请求响应时长|
|
`precision`
| string |
`fp32`
| 预测精度,降低预测精度可提升预测速度,GPU 支持: "fp32"(default), "fp16", "int8";CPU 支持: "fp32"(default), "fp16", "bf16"(mkldnn); 不支持: "int8" |
|
`mem_optim`
| bool |
`True`
| 内存优化选项 |
|
`use_calib`
| bool |
`False`
| TRT int8 量化校准模型 |
|
`mkldnn_cache_capacity`
| int |
`0`
| mkldnn 的不同输入尺寸缓存大小 |
|
`mkldnn_op_list`
| list |
`-`
| mkldnn 加速的 op 列表 |
|
`mkldnn_bf16_op_list`
| list |
`-`
| mkldnn bf16 加速的 op 列表 |
|
`min_subgraph_size`
| int |
`3`
| 开启 tensorrt 优化的最小子图大小 |
**三. 进阶参数配置**
更多进阶参数配置介绍,可以参照下表:如单机多卡推理、异构硬件、低精度推理等请参考
[
Pipeline Serving 典型示例
](
)
| 特性 | 文档 |
| ---- | ---- |
| 单机多卡推理|
[
Pipeline Serving
](
)
|
| 异构硬件|
[
Pipeline Serving
](
)
|
| 低精度推理|
[
Pipeline Serving
](
)
|
\ No newline at end of file
doc/Offical_Docs/8-0_Cube_CN.md
0 → 100644
浏览文件 @
a3786b87
# 稀疏参数索引服务 Cube
在稀疏参数索引场景,如推荐、广告系统中通常会使用大规模 Embedding 表。由于在工业级的场景中,稀疏参数的规模非常大,达到 10^9 数量级。因此在一台机器上启动大规模稀疏参数预测是不实际的,因此我们引入百度多年来在稀疏参数索引领域的工业级产品 Cube,提供分布式的稀疏参数服务。
## Cube 工作原理
本章节介绍了 Cube 的基本使用方法和工作原理。请参考
[
Cube 架构
](
)
## Cube 编译安装
本章节介绍了 Cube 各个组件的编译以及安装方法。请参考
[
Cube 编译安装
](
)
## Cube 基础功能
本章节介绍了 Cube 的基础功能及使用方法。请参考
[
Cube 基础功能
](
)
## Cube 进阶功能
本章节介绍了 Cube 的高级功能使用方法。请参考
[
Cube 进阶功能
](
)
## 在 K8S 上使用 Cube
本章节介绍了在 K8S 平台上使用 Cube 的方法。请参考
[
在 K8S 上使用 Cube
](
)
## Cube 部署示例
本章节介绍了 Cube 的一个部署示例。请参考
[
Cube 部署示例
](
)
\ No newline at end of file
doc/Offical_Docs/8-1_Cube_Architecture_CN.md
0 → 100644
浏览文件 @
a3786b87
# 稀疏参数索引服务 Cube
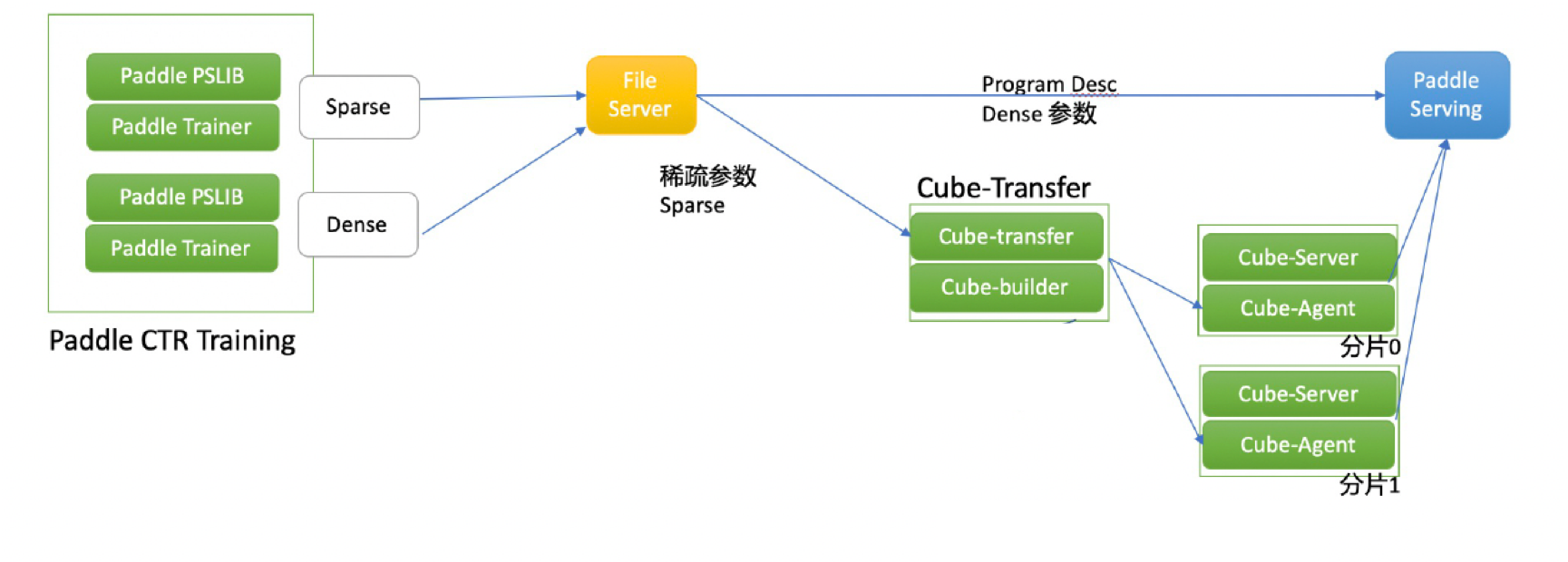
在稀疏参数索引场景,如推荐、广告系统中通常会使用大规模 Embedding 表。由于在工业级的场景中,稀疏参数的规模非常大,达到 10^9 数量级。因此在一台机器上启动大规模稀疏参数预测是不实际的,因此我们引入百度多年来在稀疏参数索引领域的工业级产品 Cube,用于部署大规模的稀疏参数模型,支持模型的分布式管理和快速更新,并且支持 Paddle Serving 进行低延迟的批量访问。
<img
src=
"images/8-1_Cube_Architecture_CN_1.png"
>
## Cube 组件介绍
**一. cube-builder**
cube-builder 是把模型生成分片文件和版本管理的工具。由于稀疏参数文件往往是一个大文件,需要使用哈希函数将其分割为不同的分片,并使用分布式当中的每一个节点去加载不同的分片。与此同时,工业级的场景需要支持定期模型的配送和流式训练,因此对于模型的版本管理十分重要,这也是在训练保存模型时缺失的部分,因此 cube-builder 在生成分片的同时,也可以人为指定增加版本信息。
**二. cube-transfer**
cube-transfer 是调度管理服务。一方面 cube-transfer 会监测上游模型,当模型更新时进行模型下载。另一方面,会调用 cube-builder 将下载好的模型进行分片。而后与 cube-agent 进行对接完成分片文件配送。
**三. cube-agent**
cube-agent 是与cube-transfer 配套使用的调度管理服务。cube-agent 会接收来自 cube-transfer 传输来的分片文件。而后发送信号给 cube-server 对应接口完成配送操作。
**四. cube-server**
cube-server 基于 Cube 的 KV 能力,对外提供稀疏参数服务。它通过 brpc 提供高性能分布式查询服务,并支持 RestAPI 来进行远端调用。
**五. cube-cli**
cube-cli 是 cube-server 的客户端,用于请求 cube-server 进行对应稀疏参数查询功能。这部分组件已经被整合到 paddle serving 当中,当我们准备好 cube.conf 配置文件并在 server 的代码中指定kv_infer 相关的 op 时,cube-cli 就会在 server 端准备就绪。
## 配送过程
一次完整的配送流程如下:
-
将训练好的模型存放到 FileServer 中,并在传输完成后生成完成标志,这里 FileServer 可以使用 http 协议的文件传输服务;
-
cube-transfer 监测到完成标志后,从 FileServer 中下载对应模型文件;
-
cube-transfer 使用 cube-builder 工具对稀疏参数模型进行分片;
-
cube-transfer 向 cube-agent 进行文件配送;
-
cube-agent 向 cube-server 发送加载命令,通知 cube-server 热加载新的参数文件;
-
cube-server 响应 Paddle Serving 发送的查询请求。
\ No newline at end of file
doc/Offical_Docs/8-2_Cube_Compile_CN.md
0 → 100644
浏览文件 @
a3786b87
# Cube 编译
## 编译依赖
**以下是主要组件及其编译依赖**
| 组件 | 说明 |
| :--------------------------: | :-------------------------------: |
| Cube-Server | C++程序,提供高效快速的 RPC 协议 |
| Cube-Agent | Go 程序,需要 Go 环境支持 |
| Cube-Transfer | Go 程序,需要 Go 环境支持 |
| Cube-Builder | C++程序 |
| Cube-Cli | C++组件,已集成进 C++ server 中,不需单独编译 |
## 编译方法
推荐使用 Docker 编译,我们已经为您准备好了编译环境并配置好了上述编译依赖,详见
[
镜像环境
](
)。
**一. 设置 PYTHON 环境变量**
请按照如下,确定好需要编译的 Python 版本,设置对应的环境变量,一共需要设置三个环境变量,分别是
`PYTHON_INCLUDE_DIR`
,
`PYTHON_LIBRARIES`
,
`PYTHON_EXECUTABLE`
。以下我们以 python 3.7为例,介绍如何设置这三个环境变量。
```
# 请自行修改至自身路径
export PYTHON_INCLUDE_DIR=/usr/local/include/python3.7m/
export PYTHON_LIBRARIES=/usr/local/lib/x86_64-linux-gnu/libpython3.7m.so
export PYTHON_EXECUTABLE=/usr/local/bin/python3.7
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin
python3.7 -m pip install -r python/requirements.txt
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.cn,direct
go install github.com/grpc-ecosystem/grpc-gateway/protoc-gen-grpc-gateway@v1.15.2
go install github.com/grpc-ecosystem/grpc-gateway/protoc-gen-swagger@v1.15.2
go install github.com/golang/protobuf/protoc-gen-go@v1.4.3
go install google.golang.org/grpc@v1.33.0
go env -w GO111MODULE=auto
```
环境变量的含义如下表所示。
| cmake 环境变量 | 含义 | 注意事项 | Docker 环境是否需要 |
|-----------------------|-------------------------------------|-------------------------------|--------------------|
| PYTHON_INCLUDE_DIR | Python.h 所在的目录,通常为
**
/include/python3.7/Python.h | 如果没有找到。说明 1)没有安装开发版本的 Python,需重新安装 2)权限不足无法查看相关系统目录。 | 是(/usr/local/include/python3.7) |
| PYTHON_LIBRARIES | libpython3.7.so 或 libpython3.7m.so 所在目录,通常为 /usr/local/lib | 如果没有找到。说明 1)没有安装开发版本的 Python,需重新安装 2)权限不足无法查看相关系统目录。 | 是(/usr/local/lib/x86_64-linux-gnu/libpython3.7m.so) |
| PYTHON_EXECUTABLE | python3.7 所在目录,通常为 /usr/local/bin | | 是(/usr/local/bin/python3.7) |
**二. 编译**
```
mkdir build_cube
cd build_cube
cmake -DPYTHON_INCLUDE_DIR=$PYTHON_INCLUDE_DIR \
-DPYTHON_LIBRARIES=$PYTHON_LIBRARIES \
-DPYTHON_EXECUTABLE=$PYTHON_EXECUTABLE \
-DSERVER=ON \
-DWITH_GPU=OFF ..
make -j
cd ..
```
最终我们会在
`build_cube/core/cube`
目录下看到 Cube 组件已经编译完成,其中:
-
Cube-Server:build_cube/core/cube/cube-server/cube
-
Cube-Agent:build_cube/core/cube/cube-agent/src/cube-agent
-
Cube-Transfer:build_cube/core/cube/cube-transfer/src/cube-transfer
-
Cube-Builder:build_cube/core/cube/cube-builder/cube-builder
\ No newline at end of file
doc/Offical_Docs/images/8-1_Cube_Architecture_CN_1.png
0 → 100644
浏览文件 @
a3786b87
754.3 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}