Merge branch 'develop' into dev-doc
Showing
core/configure/proto/server_configure.proto
100755 → 100644
core/predictor/framework/bsf-inl.h
100755 → 100644
doc/Offical_Docs/12-0_FAQ_CN.md
0 → 100644
此差异已折叠。
此差异已折叠。
doc/Offical_Docs/Home_Page_CN.md
0 → 100644
{kind=link}

358.2 KB
{kind=link}
295.1 KB
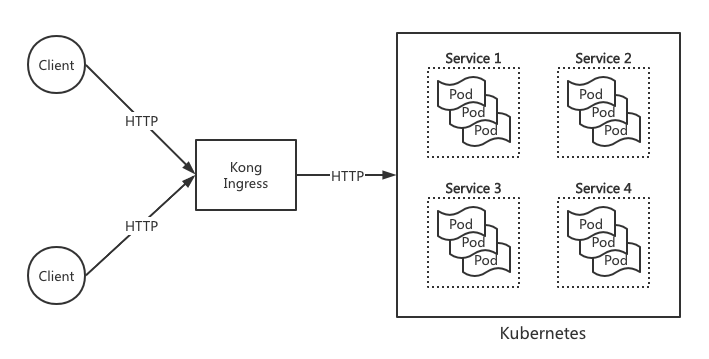
doc/images/kubernetes_design.png
0 → 100644
{kind=link}
33.6 KB
{kind=link}
674.8 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
doc/wechat_group_1.jpeg
0 → 100644
{kind=link}
119.1 KB
此差异已折叠。
{kind=link}

38.8 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
examples/C++/PaddleNLP/bert/bert_gpu_server.py
100644 → 100755
此差异已折叠。
examples/C++/PaddleNLP/bert/bert_server.py
100644 → 100755
此差异已折叠。
examples/C++/PaddleRec/criteo_ctr/test_server.py
100644 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}

38.8 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
python/pipeline/local_service_handler.py
100644 → 100755
此差异已折叠。
此差异已折叠。