Merge pull request #296 from wangjiawei04/jiawei/dist_kv_benchmark
Dist KV Op, Cube Criteo Demo & Benchmark
Showing
core/predictor/tools/seq_file.cpp
0 → 100644
core/predictor/tools/seq_file.h
0 → 100644
{kind=link}
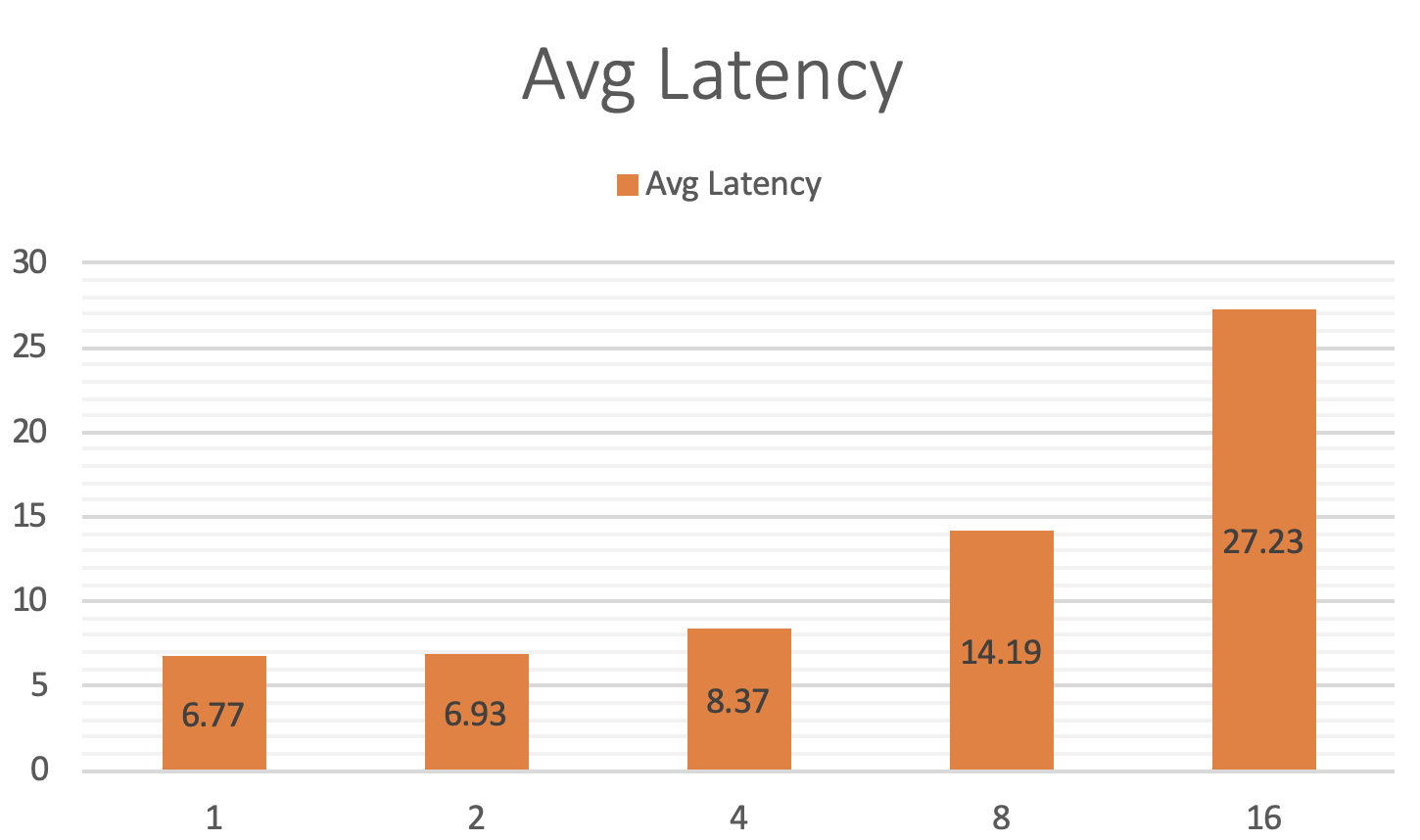
66.0 KB
doc/criteo-cube-benchmark-qps.png
0 → 100644
{kind=link}
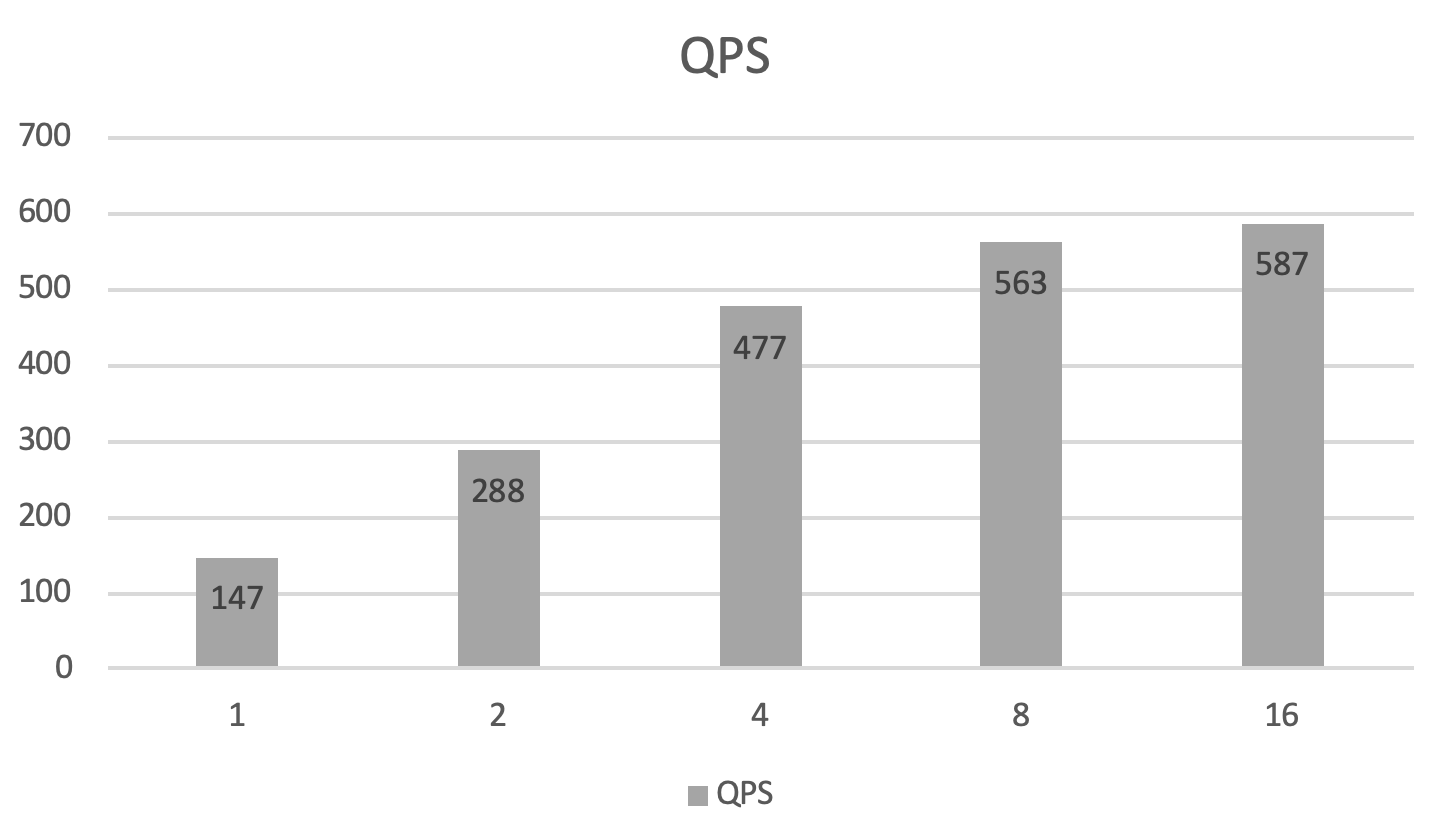
54.4 KB