Merge branch 'develop' into dev-doc1
Showing
doc/Offical_Docs/12-0_FAQ_CN.md
0 → 100644
此差异已折叠。
doc/Offical_Docs/8-0_Cube_CN.md
0 → 100644
doc/Offical_Docs/Home_Page_CN.md
0 → 100644
{kind=link}
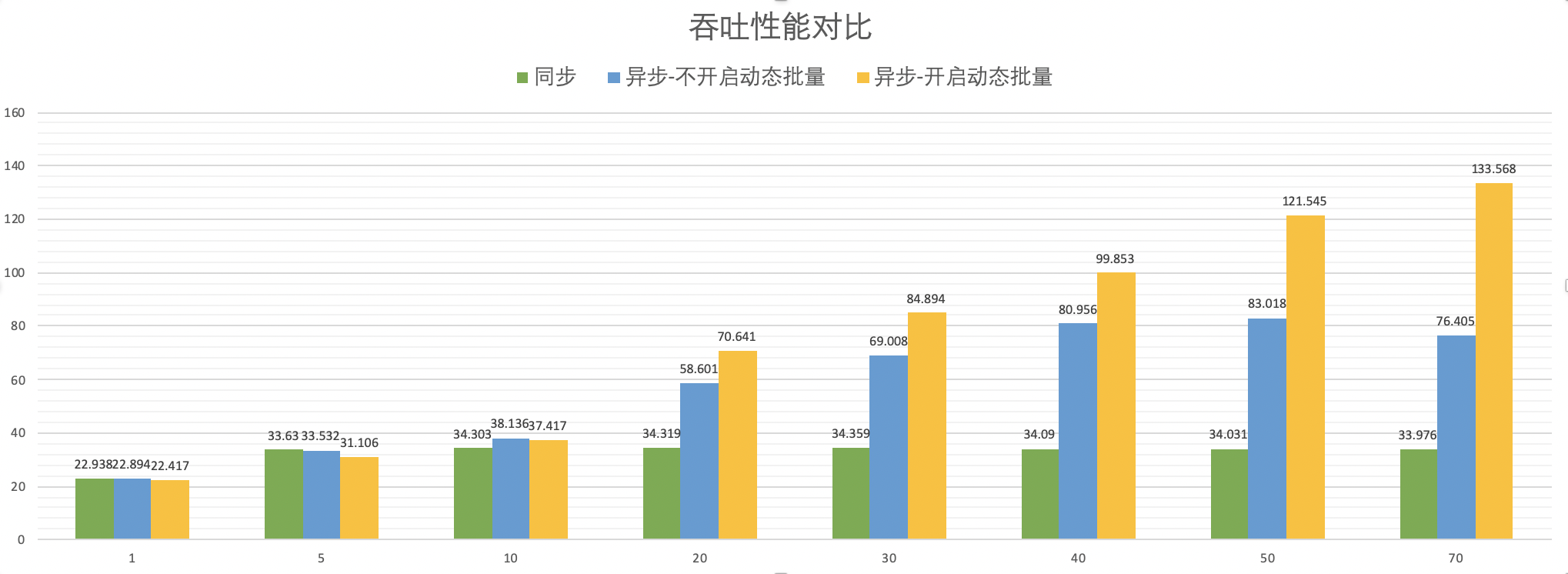
358.2 KB
{kind=link}
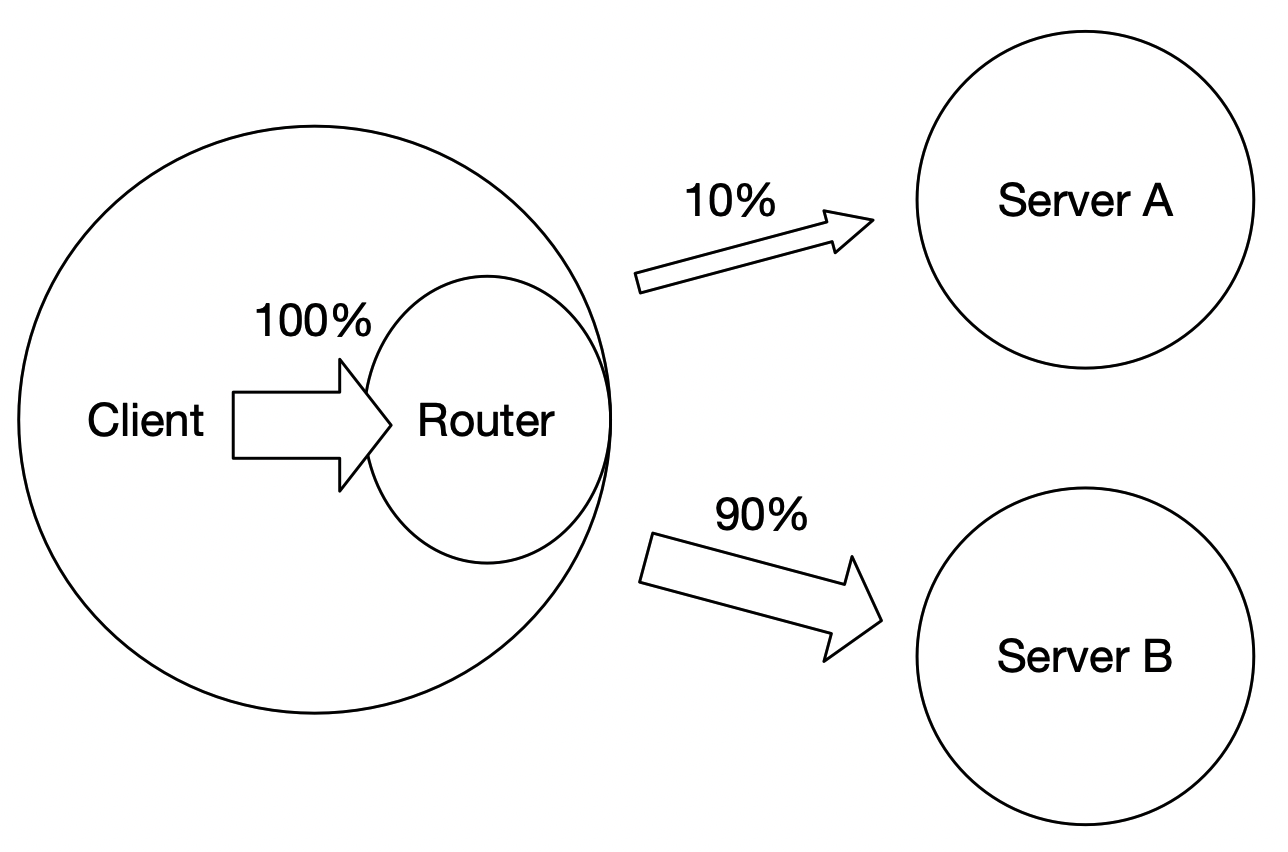
295.1 KB
{kind=link}
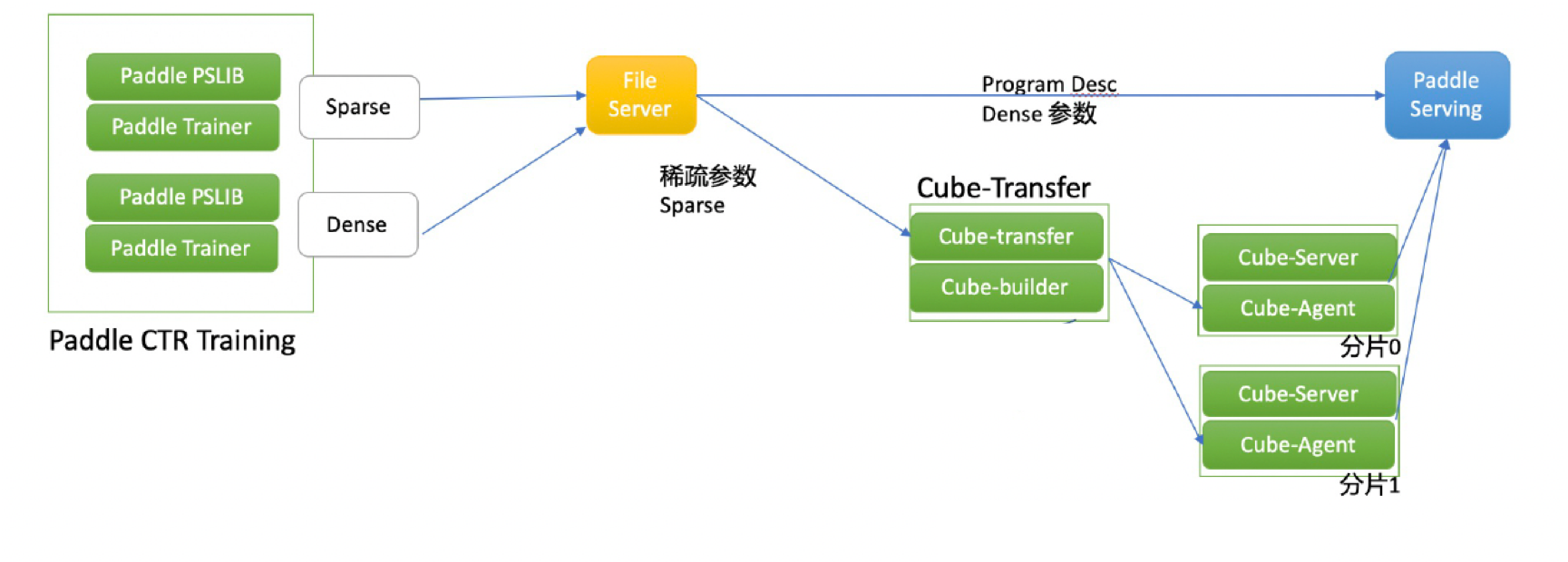
754.3 KB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

38.8 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。