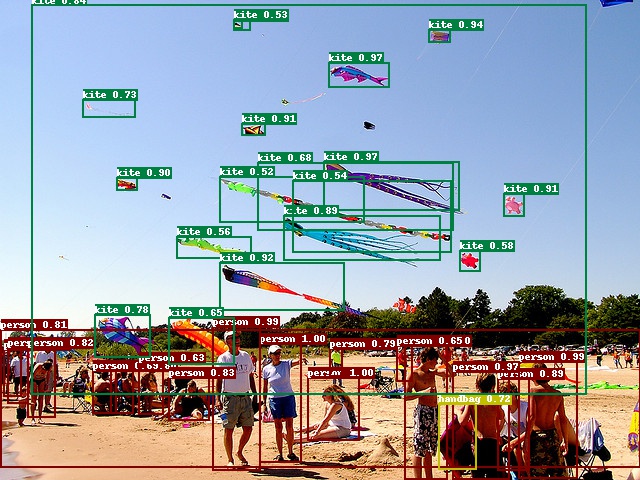
If you want to have more detection models, please refer to [Paddle Detection Model Zoo](https://github.com/PaddlePaddle/PaddleDetection/blob/release/0.2/docs/MODEL_ZOO_cn.md)
This is the picture after adding bbox. You can see that the client has done post-processing for the picture. In addition, the output/bbox.json also has the number and coordinate information of each box.
{kind=link}

{kind=link}