Merge pull request #35 from wangguibao/ctr_model_serving
CTR PREDICTION model serving
Showing
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
demo-serving/conf/cube.conf
0 → 100644
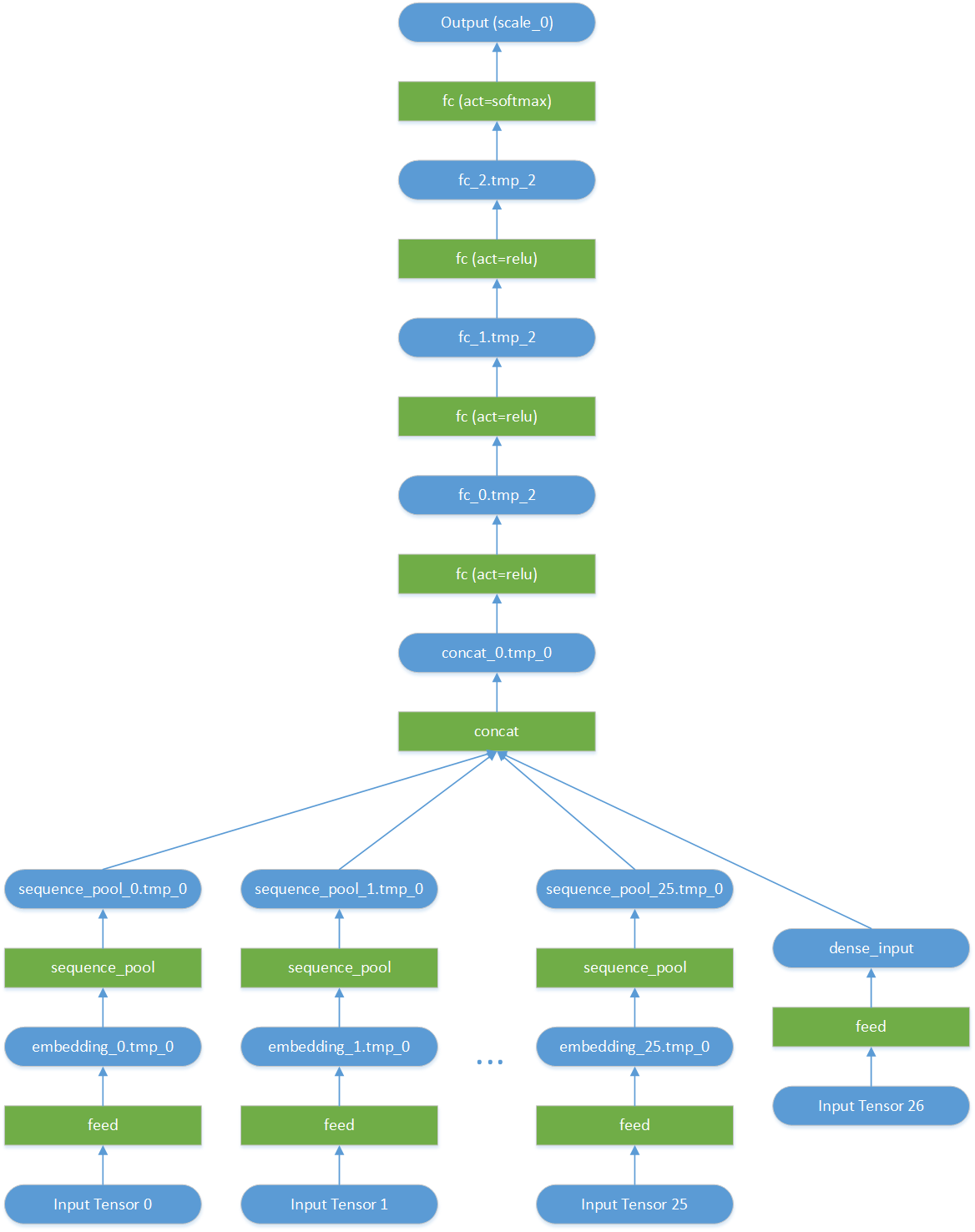
doc/CTR_PREDICTION.md
0 → 100755
doc/pruned-ctr-network.png
0 → 100755
{kind=link}
68.5 KB
predictor/framework/kv_manager.h
0 → 100644