Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
Serving
提交
43130344
S
Serving
项目概览
PaddlePaddle
/
Serving
1 年多 前同步成功
通知
186
Star
833
Fork
253
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
105
列表
看板
标记
里程碑
合并请求
10
Wiki
2
Wiki
分析
仓库
DevOps
项目成员
Pages
S
Serving
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
105
Issue
105
列表
看板
标记
里程碑
合并请求
10
合并请求
10
Pages
分析
分析
仓库分析
DevOps
Wiki
2
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
43130344
编写于
3月 20, 2020
作者:
Y
Your Name
浏览文件
操作
浏览文件
下载
差异文件
merge
上级
20010c1d
a5ffd6c6
变更
40
隐藏空白更改
内联
并排
Showing
40 changed file
with
1614 addition
and
22 deletion
+1614
-22
README.md
README.md
+10
-4
core/configure/proto/server_configure.proto
core/configure/proto/server_configure.proto
+4
-3
core/cube/cube-api/include/cube_api.h
core/cube/cube-api/include/cube_api.h
+7
-0
core/cube/cube-api/src/cube_api.cpp
core/cube/cube-api/src/cube_api.cpp
+8
-0
core/general-server/CMakeLists.txt
core/general-server/CMakeLists.txt
+1
-0
core/general-server/op/general_dist_kv_infer_op.cpp
core/general-server/op/general_dist_kv_infer_op.cpp
+167
-0
core/general-server/op/general_dist_kv_infer_op.h
core/general-server/op/general_dist_kv_infer_op.h
+46
-0
core/predictor/CMakeLists.txt
core/predictor/CMakeLists.txt
+1
-1
core/predictor/common/CMakeLists.txt
core/predictor/common/CMakeLists.txt
+1
-1
core/predictor/framework/resource.cpp
core/predictor/framework/resource.cpp
+20
-0
core/predictor/framework/resource.h
core/predictor/framework/resource.h
+1
-0
core/predictor/proto/CMakeLists.txt
core/predictor/proto/CMakeLists.txt
+1
-0
core/predictor/proto/framework.proto
core/predictor/proto/framework.proto
+217
-0
core/predictor/tools/CMakeLists.txt
core/predictor/tools/CMakeLists.txt
+4
-0
core/predictor/tools/seq_file.cpp
core/predictor/tools/seq_file.cpp
+83
-0
core/predictor/tools/seq_file.h
core/predictor/tools/seq_file.h
+52
-0
core/predictor/tools/seq_generator.cpp
core/predictor/tools/seq_generator.cpp
+116
-0
doc/criteo-cube-benchmark-avgcost.png
doc/criteo-cube-benchmark-avgcost.png
+0
-0
doc/criteo-cube-benchmark-qps.png
doc/criteo-cube-benchmark-qps.png
+0
-0
python/examples/criteo_ctr_with_cube/README.md
python/examples/criteo_ctr_with_cube/README.md
+61
-0
python/examples/criteo_ctr_with_cube/args.py
python/examples/criteo_ctr_with_cube/args.py
+105
-0
python/examples/criteo_ctr_with_cube/benchmark.py
python/examples/criteo_ctr_with_cube/benchmark.py
+80
-0
python/examples/criteo_ctr_with_cube/benchmark.sh
python/examples/criteo_ctr_with_cube/benchmark.sh
+10
-0
python/examples/criteo_ctr_with_cube/benchmark_batch.py
python/examples/criteo_ctr_with_cube/benchmark_batch.py
+85
-0
python/examples/criteo_ctr_with_cube/benchmark_batch.sh
python/examples/criteo_ctr_with_cube/benchmark_batch.sh
+12
-0
python/examples/criteo_ctr_with_cube/clean.sh
python/examples/criteo_ctr_with_cube/clean.sh
+5
-0
python/examples/criteo_ctr_with_cube/criteo.py
python/examples/criteo_ctr_with_cube/criteo.py
+81
-0
python/examples/criteo_ctr_with_cube/criteo_reader.py
python/examples/criteo_ctr_with_cube/criteo_reader.py
+83
-0
python/examples/criteo_ctr_with_cube/cube/conf/cube.conf
python/examples/criteo_ctr_with_cube/cube/conf/cube.conf
+13
-0
python/examples/criteo_ctr_with_cube/cube/conf/gflags.conf
python/examples/criteo_ctr_with_cube/cube/conf/gflags.conf
+4
-0
python/examples/criteo_ctr_with_cube/cube/keys
python/examples/criteo_ctr_with_cube/cube/keys
+10
-0
python/examples/criteo_ctr_with_cube/cube_prepare.sh
python/examples/criteo_ctr_with_cube/cube_prepare.sh
+7
-0
python/examples/criteo_ctr_with_cube/get_data.sh
python/examples/criteo_ctr_with_cube/get_data.sh
+2
-0
python/examples/criteo_ctr_with_cube/local_train.py
python/examples/criteo_ctr_with_cube/local_train.py
+100
-0
python/examples/criteo_ctr_with_cube/network_conf.py
python/examples/criteo_ctr_with_cube/network_conf.py
+77
-0
python/examples/criteo_ctr_with_cube/test_client.py
python/examples/criteo_ctr_with_cube/test_client.py
+48
-0
python/examples/criteo_ctr_with_cube/test_server.py
python/examples/criteo_ctr_with_cube/test_server.py
+37
-0
python/paddle_serving_client/__init__.py
python/paddle_serving_client/__init__.py
+11
-10
python/paddle_serving_server/__init__.py
python/paddle_serving_server/__init__.py
+8
-1
tools/serving_build.sh
tools/serving_build.sh
+36
-2
未找到文件。
README.md
浏览文件 @
43130344
...
...
@@ -98,9 +98,12 @@ print(fetch_map)
<h3
align=
"center"
>
Chinese Word Segmentation
</h4>
-
**Description**
: Chinese word segmentation HTTP service that can be deployed with one line command.
-
**Description**
:
```
shell
Chinese word segmentation HTTP service that can be deployed with one line command.
```
-
**Download**
:
-
**Download
Servable Package
**
:
```
shell
wget
--no-check-certificate
https://paddle-serving.bj.bcebos.com/lac/lac_model_jieba_web.tar.gz
```
...
...
@@ -120,9 +123,12 @@ curl -H "Content-Type:application/json" -X POST -d '{"words": "我爱北京天
<h3
align=
"center"
>
Image Classification
</h4>
-
**Description**
: Image classification trained with Imagenet dataset. A label and corresponding probability will be returned.
-
**Description**
:
```
shell
Image classification trained with Imagenet dataset. A label and corresponding probability will be returned.
```
-
**Download**
:
-
**Download
Servable Package
**
:
```
shell
wget
--no-check-certificate
https://paddle-serving.bj.bcebos.com/imagenet-example/imagenet_demo.tar.gz
```
...
...
core/configure/proto/server_configure.proto
浏览文件 @
43130344
...
...
@@ -52,9 +52,10 @@ message ModelToolkitConf { repeated EngineDesc engines = 1; };
message
ResourceConf
{
required
string
model_toolkit_path
=
1
;
required
string
model_toolkit_file
=
2
;
optional
string
cube_config_file
=
3
;
optional
string
general_model_path
=
4
;
optional
string
general_model_file
=
5
;
optional
string
general_model_path
=
3
;
optional
string
general_model_file
=
4
;
optional
string
cube_config_path
=
5
;
optional
string
cube_config_file
=
6
;
};
// DAG node depency info
...
...
core/cube/cube-api/include/cube_api.h
浏览文件 @
43130344
...
...
@@ -99,6 +99,13 @@ class CubeAPI {
std
::
function
<
void
(
DictValue
*
,
size_t
)
>
parse
,
std
::
string
*
version
);
/**
* @brief: get all table names from cube server, thread safe.
* @param [out] vals: vector of table names
*
*/
std
::
vector
<
std
::
string
>
get_table_names
();
public:
static
const
char
*
error_msg
(
int
error_code
);
...
...
core/cube/cube-api/src/cube_api.cpp
浏览文件 @
43130344
...
...
@@ -682,5 +682,13 @@ int CubeAPI::opt_seek(const std::string& dict_name,
return
ret
;
}
std
::
vector
<
std
::
string
>
CubeAPI
::
get_table_names
()
{
const
std
::
vector
<
const
MetaInfo
*>
metas
=
_meta
->
metas
();
std
::
vector
<
std
::
string
>
table_names
;
for
(
auto
itr
=
metas
.
begin
();
itr
!=
metas
.
end
();
++
itr
)
{
table_names
.
push_back
((
*
itr
)
->
dict_name
);
}
return
table_names
;
}
}
// namespace mcube
}
// namespace rec
core/general-server/CMakeLists.txt
浏览文件 @
43130344
include_directories
(
SYSTEM
${
CMAKE_CURRENT_LIST_DIR
}
/../../
)
include
(
op/CMakeLists.txt
)
include
(
proto/CMakeLists.txt
)
add_executable
(
serving
${
serving_srcs
}
)
...
...
core/general-server/op/general_dist_kv_infer_op.cpp
0 → 100755
浏览文件 @
43130344
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include "core/general-server/op/general_dist_kv_infer_op.h"
#include <algorithm>
#include <iostream>
#include <memory>
#include <sstream>
#include <unordered_map>
#include <utility>
#include "core/cube/cube-api/include/cube_api.h"
#include "core/predictor/framework/infer.h"
#include "core/predictor/framework/memory.h"
#include "core/predictor/framework/resource.h"
#include "core/util/include/timer.h"
namespace
baidu
{
namespace
paddle_serving
{
namespace
serving
{
using
baidu
::
paddle_serving
::
Timer
;
using
baidu
::
paddle_serving
::
predictor
::
MempoolWrapper
;
using
baidu
::
paddle_serving
::
predictor
::
general_model
::
Tensor
;
using
baidu
::
paddle_serving
::
predictor
::
general_model
::
Response
;
using
baidu
::
paddle_serving
::
predictor
::
general_model
::
Request
;
using
baidu
::
paddle_serving
::
predictor
::
general_model
::
FetchInst
;
using
baidu
::
paddle_serving
::
predictor
::
InferManager
;
using
baidu
::
paddle_serving
::
predictor
::
PaddleGeneralModelConfig
;
int
GeneralDistKVInferOp
::
inference
()
{
VLOG
(
2
)
<<
"Going to run inference"
;
const
GeneralBlob
*
input_blob
=
get_depend_argument
<
GeneralBlob
>
(
pre_name
());
VLOG
(
2
)
<<
"Get precedent op name: "
<<
pre_name
();
GeneralBlob
*
output_blob
=
mutable_data
<
GeneralBlob
>
();
if
(
!
input_blob
)
{
LOG
(
ERROR
)
<<
"Failed mutable depended argument, op:"
<<
pre_name
();
return
-
1
;
}
const
TensorVector
*
in
=
&
input_blob
->
tensor_vector
;
TensorVector
*
out
=
&
output_blob
->
tensor_vector
;
int
batch_size
=
input_blob
->
GetBatchSize
();
VLOG
(
2
)
<<
"input batch size: "
<<
batch_size
;
std
::
vector
<
uint64_t
>
keys
;
std
::
vector
<
rec
::
mcube
::
CubeValue
>
values
;
int
sparse_count
=
0
;
int
dense_count
=
0
;
std
::
vector
<
std
::
pair
<
int64_t
*
,
size_t
>>
dataptr_size_pairs
;
size_t
key_len
=
0
;
for
(
size_t
i
=
0
;
i
<
in
->
size
();
++
i
)
{
if
(
in
->
at
(
i
).
dtype
!=
paddle
::
PaddleDType
::
INT64
)
{
++
dense_count
;
continue
;
}
++
sparse_count
;
size_t
elem_num
=
1
;
for
(
size_t
s
=
0
;
s
<
in
->
at
(
i
).
shape
.
size
();
++
s
)
{
elem_num
*=
in
->
at
(
i
).
shape
[
s
];
}
key_len
+=
elem_num
;
int64_t
*
data_ptr
=
static_cast
<
int64_t
*>
(
in
->
at
(
i
).
data
.
data
());
dataptr_size_pairs
.
push_back
(
std
::
make_pair
(
data_ptr
,
elem_num
));
}
keys
.
resize
(
key_len
);
int
key_idx
=
0
;
for
(
size_t
i
=
0
;
i
<
dataptr_size_pairs
.
size
();
++
i
)
{
std
::
copy
(
dataptr_size_pairs
[
i
].
first
,
dataptr_size_pairs
[
i
].
first
+
dataptr_size_pairs
[
i
].
second
,
keys
.
begin
()
+
key_idx
);
key_idx
+=
dataptr_size_pairs
[
i
].
second
;
}
rec
::
mcube
::
CubeAPI
*
cube
=
rec
::
mcube
::
CubeAPI
::
instance
();
std
::
vector
<
std
::
string
>
table_names
=
cube
->
get_table_names
();
if
(
table_names
.
size
()
==
0
)
{
LOG
(
ERROR
)
<<
"cube init error or cube config not given."
;
return
-
1
;
}
int
ret
=
cube
->
seek
(
table_names
[
0
],
keys
,
&
values
);
if
(
values
.
size
()
!=
keys
.
size
()
||
values
[
0
].
buff
.
size
()
==
0
)
{
LOG
(
ERROR
)
<<
"cube value return null"
;
}
size_t
EMBEDDING_SIZE
=
values
[
0
].
buff
.
size
()
/
sizeof
(
float
);
TensorVector
sparse_out
;
sparse_out
.
resize
(
sparse_count
);
TensorVector
dense_out
;
dense_out
.
resize
(
dense_count
);
int
cube_val_idx
=
0
;
int
sparse_idx
=
0
;
int
dense_idx
=
0
;
std
::
unordered_map
<
int
,
int
>
in_out_map
;
baidu
::
paddle_serving
::
predictor
::
Resource
&
resource
=
baidu
::
paddle_serving
::
predictor
::
Resource
::
instance
();
std
::
shared_ptr
<
PaddleGeneralModelConfig
>
model_config
=
resource
.
get_general_model_config
();
for
(
size_t
i
=
0
;
i
<
in
->
size
();
++
i
)
{
if
(
in
->
at
(
i
).
dtype
!=
paddle
::
PaddleDType
::
INT64
)
{
dense_out
[
dense_idx
]
=
in
->
at
(
i
);
++
dense_idx
;
continue
;
}
sparse_out
[
sparse_idx
].
lod
.
resize
(
in
->
at
(
i
).
lod
.
size
());
for
(
size_t
x
=
0
;
x
<
sparse_out
[
sparse_idx
].
lod
.
size
();
++
x
)
{
sparse_out
[
sparse_idx
].
lod
[
x
].
resize
(
in
->
at
(
i
).
lod
[
x
].
size
());
std
::
copy
(
in
->
at
(
i
).
lod
[
x
].
begin
(),
in
->
at
(
i
).
lod
[
x
].
end
(),
sparse_out
[
sparse_idx
].
lod
[
x
].
begin
());
}
sparse_out
[
sparse_idx
].
dtype
=
paddle
::
PaddleDType
::
FLOAT32
;
sparse_out
[
sparse_idx
].
shape
.
push_back
(
sparse_out
[
sparse_idx
].
lod
[
0
].
back
());
sparse_out
[
sparse_idx
].
shape
.
push_back
(
EMBEDDING_SIZE
);
sparse_out
[
sparse_idx
].
name
=
model_config
->
_feed_name
[
i
];
sparse_out
[
sparse_idx
].
data
.
Resize
(
sparse_out
[
sparse_idx
].
lod
[
0
].
back
()
*
EMBEDDING_SIZE
*
sizeof
(
float
));
float
*
dst_ptr
=
static_cast
<
float
*>
(
sparse_out
[
sparse_idx
].
data
.
data
());
for
(
int
x
=
0
;
x
<
sparse_out
[
sparse_idx
].
lod
[
0
].
back
();
++
x
)
{
float
*
data_ptr
=
dst_ptr
+
x
*
EMBEDDING_SIZE
;
memcpy
(
data_ptr
,
values
[
cube_val_idx
].
buff
.
data
(),
values
[
cube_val_idx
].
buff
.
size
());
cube_val_idx
++
;
}
++
sparse_idx
;
}
TensorVector
infer_in
;
infer_in
.
insert
(
infer_in
.
end
(),
dense_out
.
begin
(),
dense_out
.
end
());
infer_in
.
insert
(
infer_in
.
end
(),
sparse_out
.
begin
(),
sparse_out
.
end
());
output_blob
->
SetBatchSize
(
batch_size
);
VLOG
(
2
)
<<
"infer batch size: "
<<
batch_size
;
Timer
timeline
;
int64_t
start
=
timeline
.
TimeStampUS
();
timeline
.
Start
();
if
(
InferManager
::
instance
().
infer
(
GENERAL_MODEL_NAME
,
&
infer_in
,
out
,
batch_size
))
{
LOG
(
ERROR
)
<<
"Failed do infer in fluid model: "
<<
GENERAL_MODEL_NAME
;
return
-
1
;
}
int64_t
end
=
timeline
.
TimeStampUS
();
CopyBlobInfo
(
input_blob
,
output_blob
);
AddBlobInfo
(
output_blob
,
start
);
AddBlobInfo
(
output_blob
,
end
);
return
0
;
}
DEFINE_OP
(
GeneralDistKVInferOp
);
}
// namespace serving
}
// namespace paddle_serving
}
// namespace baidu
core/general-server/op/general_dist_kv_infer_op.h
0 → 100644
浏览文件 @
43130344
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <string>
#include <vector>
#ifdef BCLOUD
#ifdef WITH_GPU
#include "paddle/paddle_inference_api.h"
#else
#include "paddle/fluid/inference/api/paddle_inference_api.h"
#endif
#else
#include "paddle_inference_api.h" // NOLINT
#endif
#include "core/general-server/general_model_service.pb.h"
#include "core/general-server/op/general_infer_helper.h"
namespace
baidu
{
namespace
paddle_serving
{
namespace
serving
{
class
GeneralDistKVInferOp
:
public
baidu
::
paddle_serving
::
predictor
::
OpWithChannel
<
GeneralBlob
>
{
public:
typedef
std
::
vector
<
paddle
::
PaddleTensor
>
TensorVector
;
DECLARE_OP
(
GeneralDistKVInferOp
);
int
inference
();
};
}
// namespace serving
}
// namespace paddle_serving
}
// namespace baidu
core/predictor/CMakeLists.txt
浏览文件 @
43130344
...
...
@@ -3,7 +3,7 @@ include(common/CMakeLists.txt)
include
(
op/CMakeLists.txt
)
include
(
mempool/CMakeLists.txt
)
include
(
framework/CMakeLists.txt
)
#include(plugin
/CMakeLists.txt)
include
(
tools
/CMakeLists.txt
)
include
(
src/CMakeLists.txt
)
...
...
core/predictor/common/CMakeLists.txt
浏览文件 @
43130344
FILE
(
GLOB common_srcs
${
CMAKE_CURRENT_LIST_DIR
}
/
*
.cpp
)
FILE
(
GLOB common_srcs
${
CMAKE_CURRENT_LIST_DIR
}
/
constant
.cpp
)
LIST
(
APPEND pdserving_srcs
${
common_srcs
}
)
core/predictor/framework/resource.cpp
浏览文件 @
43130344
...
...
@@ -141,6 +141,17 @@ int Resource::initialize(const std::string& path, const std::string& file) {
LOG
(
ERROR
)
<<
"unable to create tls_bthread_key of thrd_data"
;
return
-
1
;
}
// init rocksDB or cube instance
if
(
resource_conf
.
has_cube_config_file
()
&&
resource_conf
.
has_cube_config_path
())
{
LOG
(
INFO
)
<<
"init cube client, path[ "
<<
resource_conf
.
cube_config_path
()
<<
" ], config file [ "
<<
resource_conf
.
cube_config_file
()
<<
" ]."
;
rec
::
mcube
::
CubeAPI
*
cube
=
rec
::
mcube
::
CubeAPI
::
instance
();
std
::
string
cube_config_fullpath
=
"./"
+
resource_conf
.
cube_config_path
()
+
"/"
+
resource_conf
.
cube_config_file
();
this
->
cube_config_fullpath
=
cube_config_fullpath
;
}
THREAD_SETSPECIFIC
(
_tls_bspec_key
,
NULL
);
return
0
;
...
...
@@ -149,6 +160,15 @@ int Resource::initialize(const std::string& path, const std::string& file) {
// model config
int
Resource
::
general_model_initialize
(
const
std
::
string
&
path
,
const
std
::
string
&
file
)
{
if
(
this
->
cube_config_fullpath
.
size
()
!=
0
)
{
LOG
(
INFO
)
<<
"init cube by config file : "
<<
this
->
cube_config_fullpath
;
rec
::
mcube
::
CubeAPI
*
cube
=
rec
::
mcube
::
CubeAPI
::
instance
();
int
ret
=
cube
->
init
(
this
->
cube_config_fullpath
.
c_str
());
if
(
ret
!=
0
)
{
LOG
(
ERROR
)
<<
"cube init error"
;
return
-
1
;
}
}
VLOG
(
2
)
<<
"general model path: "
<<
path
;
VLOG
(
2
)
<<
"general model file: "
<<
file
;
if
(
!
FLAGS_enable_general_model
)
{
...
...
core/predictor/framework/resource.h
浏览文件 @
43130344
...
...
@@ -108,6 +108,7 @@ class Resource {
private:
int
thread_finalize
()
{
return
0
;
}
std
::
shared_ptr
<
PaddleGeneralModelConfig
>
_config
;
std
::
string
cube_config_fullpath
;
THREAD_KEY_T
_tls_bspec_key
;
};
...
...
core/predictor/proto/CMakeLists.txt
浏览文件 @
43130344
...
...
@@ -7,6 +7,7 @@ LIST(APPEND protofiles
${
CMAKE_CURRENT_LIST_DIR
}
/./builtin_format.proto
${
CMAKE_CURRENT_LIST_DIR
}
/./msg_data.proto
${
CMAKE_CURRENT_LIST_DIR
}
/./xrecord_format.proto
${
CMAKE_CURRENT_LIST_DIR
}
/./framework.proto
)
PROTOBUF_GENERATE_SERVING_CPP
(
TRUE PROTO_SRCS PROTO_HDRS
${
protofiles
}
)
...
...
core/predictor/proto/framework.proto
0 → 100755
浏览文件 @
43130344
/* Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
syntax
=
"proto2"
;
option
optimize_for
=
LITE_RUNTIME
;
package
paddle
.
framework.proto
;
// Any incompatible changes to ProgramDesc and its dependencies should
// raise the version defined version.h.
//
// Serailization and Deserialization codes should be modified in a way
// that supports old versions following the version and compatibility policy.
message
Version
{
optional
int64
version
=
1
[
default
=
0
];
}
enum
AttrType
{
INT
=
0
;
FLOAT
=
1
;
STRING
=
2
;
INTS
=
3
;
FLOATS
=
4
;
STRINGS
=
5
;
BOOLEAN
=
6
;
BOOLEANS
=
7
;
BLOCK
=
8
;
LONG
=
9
;
BLOCKS
=
10
;
LONGS
=
11
;
}
// OpDesc describes an instance of a C++ framework::OperatorBase
// derived class type.
message
OpDesc
{
message
Attr
{
required
string
name
=
1
;
required
AttrType
type
=
2
;
optional
int32
i
=
3
;
optional
float
f
=
4
;
optional
string
s
=
5
;
repeated
int32
ints
=
6
;
repeated
float
floats
=
7
;
repeated
string
strings
=
8
;
optional
bool
b
=
10
;
repeated
bool
bools
=
11
;
optional
int32
block_idx
=
12
;
optional
int64
l
=
13
;
repeated
int32
blocks_idx
=
14
;
repeated
int64
longs
=
15
;
};
message
Var
{
required
string
parameter
=
1
;
repeated
string
arguments
=
2
;
};
required
string
type
=
3
;
repeated
Var
inputs
=
1
;
repeated
Var
outputs
=
2
;
repeated
Attr
attrs
=
4
;
optional
bool
is_target
=
5
[
default
=
false
];
};
// OpProto describes a C++ framework::OperatorBase derived class.
message
OpProto
{
// VarProto describes the C++ type framework::Variable.
message
Var
{
required
string
name
=
1
;
required
string
comment
=
2
;
optional
bool
duplicable
=
3
[
default
=
false
];
optional
bool
intermediate
=
4
[
default
=
false
];
optional
bool
dispensable
=
5
[
default
=
false
];
}
// AttrProto describes the C++ type Attribute.
message
Attr
{
required
string
name
=
1
;
required
AttrType
type
=
2
;
required
string
comment
=
3
;
// If that attribute is generated, it means the Paddle third
// language binding has responsibility to fill that
// attribute. End-User should not set that attribute.
optional
bool
generated
=
4
[
default
=
false
];
}
required
string
type
=
1
;
repeated
Var
inputs
=
2
;
repeated
Var
outputs
=
3
;
repeated
Attr
attrs
=
4
;
required
string
comment
=
5
;
}
message
VarType
{
enum
Type
{
// Pod Types
BOOL
=
0
;
INT16
=
1
;
INT32
=
2
;
INT64
=
3
;
FP16
=
4
;
FP32
=
5
;
FP64
=
6
;
// Tensor<size_t> is used in C++.
SIZE_T
=
19
;
UINT8
=
20
;
INT8
=
21
;
// Other types that may need additional descriptions
LOD_TENSOR
=
7
;
SELECTED_ROWS
=
8
;
FEED_MINIBATCH
=
9
;
FETCH_LIST
=
10
;
STEP_SCOPES
=
11
;
LOD_RANK_TABLE
=
12
;
LOD_TENSOR_ARRAY
=
13
;
PLACE_LIST
=
14
;
READER
=
15
;
// Any runtime decided variable type is raw
// raw variables should manage their own allocations
// in operators like nccl_op
RAW
=
17
;
TUPLE
=
18
;
}
required
Type
type
=
1
;
message
TensorDesc
{
// Should only be PODType. Is enforced in C++
required
Type
data_type
=
1
;
repeated
int64
dims
=
2
;
// [UNK, 640, 480] is saved as [-1, 640, 480]
}
optional
TensorDesc
selected_rows
=
2
;
message
LoDTensorDesc
{
required
TensorDesc
tensor
=
1
;
optional
int32
lod_level
=
2
[
default
=
0
];
}
optional
LoDTensorDesc
lod_tensor
=
3
;
message
LoDTensorArrayDesc
{
required
TensorDesc
tensor
=
1
;
optional
int32
lod_level
=
2
[
default
=
0
];
}
optional
LoDTensorArrayDesc
tensor_array
=
4
;
message
ReaderDesc
{
repeated
LoDTensorDesc
lod_tensor
=
1
;
}
optional
ReaderDesc
reader
=
5
;
message
Tuple
{
repeated
Type
element_type
=
1
;
}
optional
Tuple
tuple
=
7
;
}
message
VarDesc
{
required
string
name
=
1
;
required
VarType
type
=
2
;
optional
bool
persistable
=
3
[
default
=
false
];
// True if the variable is an input data and
// have to check the feed data shape and dtype
optional
bool
need_check_feed
=
4
[
default
=
false
];
}
message
BlockDesc
{
required
int32
idx
=
1
;
required
int32
parent_idx
=
2
;
repeated
VarDesc
vars
=
3
;
repeated
OpDesc
ops
=
4
;
optional
int32
forward_block_idx
=
5
[
default
=
-
1
];
}
// CompatibleInfo is used to determine if a feature is compatible and
// provides the information.
message
CompatibleInfo
{
enum
Type
{
COMPATIBLE
=
0
;
DEFINITELY_NOT
=
1
;
POSSIBLE
=
2
;
BUG_FIX
=
3
;
PRECISION_CHANGE
=
4
;
}
required
string
version
=
1
;
required
Type
type
=
2
;
}
// In some cases, Paddle Fluid may perform operator definition iterations,
// and the operator uses OpCompatibleMap for compatibility testing.
message
OpCompatibleMap
{
message
OpCompatiblePair
{
required
string
op_name
=
1
;
required
CompatibleInfo
compatible_info
=
2
;
}
repeated
OpCompatiblePair
pair
=
1
;
optional
string
default_required_version
=
2
;
}
// Please refer to
// https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/program.md
// for more details.
// TODO(panyx0718): A model can have multiple programs. Need a
// way to distinguish them. Maybe ID or name?
message
ProgramDesc
{
reserved
2
;
// For backward compatibility.
repeated
BlockDesc
blocks
=
1
;
optional
Version
version
=
4
;
optional
OpCompatibleMap
op_compatible_map
=
3
;
}
core/predictor/tools/CMakeLists.txt
0 → 100644
浏览文件 @
43130344
set
(
seq_gen_src
${
CMAKE_CURRENT_LIST_DIR
}
/seq_generator.cpp
${
CMAKE_CURRENT_LIST_DIR
}
/seq_file.cpp
)
LIST
(
APPEND seq_gen_src
${
PROTO_SRCS
}
)
add_executable
(
seq_generator
${
seq_gen_src
}
)
target_link_libraries
(
seq_generator protobuf -lpthread
)
core/predictor/tools/seq_file.cpp
0 → 100644
浏览文件 @
43130344
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <netinet/in.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <ctime>
#include <iostream>
#include <unistd.h>
#include "seq_file.h"
SeqFileWriter
::
SeqFileWriter
(
const
char
*
file
)
{
_fs
=
new
std
::
ofstream
(
file
,
std
::
ios
::
binary
);
std
::
srand
(
std
::
time
(
0
));
for
(
int
i
=
0
;
i
<
SYNC_MARKER_SIZE
;
++
i
)
{
_sync_marker
[
i
]
=
std
::
rand
()
%
255
;
}
_write_seq_header
();
_bytes_to_prev_sync
=
0
;
}
void
SeqFileWriter
::
close
()
{
_fs
->
close
();
delete
_fs
;
}
SeqFileWriter
::~
SeqFileWriter
()
{
close
();
}
void
SeqFileWriter
::
_write_sync_marker
()
{
char
begin
[]
=
{
'\xFF'
,
'\xFF'
,
'\xFF'
,
'\xFF'
};
_fs
->
write
(
begin
,
4
);
_fs
->
write
(
_sync_marker
,
SYNC_MARKER_SIZE
);
}
void
SeqFileWriter
::
_write_seq_header
()
{
_fs
->
write
(
SEQ_HEADER
,
sizeof
(
SEQ_HEADER
)
-
1
);
_fs
->
write
(
_sync_marker
,
SYNC_MARKER_SIZE
);
}
int
SeqFileWriter
::
write
(
const
char
*
key
,
size_t
key_len
,
const
char
*
value
,
size_t
value_len
)
{
if
(
key_len
!=
sizeof
(
int64_t
))
{
std
::
cout
<<
"Key length not equal to "
<<
sizeof
(
int64_t
)
<<
std
::
endl
;
return
-
1
;
}
uint32_t
record_len
=
key_len
+
value_len
;
uint32_t
b_record_len
=
htonl
(
record_len
);
uint32_t
b_key_len
=
htonl
((
uint32_t
)
key_len
);
// std::cout << "b_record_len " << b_record_len << " record_len " <<
// record_len << std::endl;
_fs
->
write
((
char
*
)
&
b_record_len
,
sizeof
(
uint32_t
));
_fs
->
write
((
char
*
)
&
b_key_len
,
sizeof
(
uint32_t
));
_fs
->
write
(
key
,
key_len
);
_fs
->
write
(
value
,
value_len
);
_bytes_to_prev_sync
+=
record_len
;
if
(
_bytes_to_prev_sync
>=
SYNC_INTERVAL
)
{
_write_sync_marker
();
_bytes_to_prev_sync
=
0
;
}
return
0
;
}
/* vim: set expandtab ts=4 sw=4 sts=4 tw=100: */
core/predictor/tools/seq_file.h
0 → 100644
浏览文件 @
43130344
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#ifndef __SEQ_FILE_H_
#define __SEQ_FILE_H_
#include <fstream>
const
int
SYNC_MARKER_SIZE
=
16
;
const
char
SEQ_HEADER
[]
=
"SEQ
\x06
"
"
\"
org.apache.hadoop.io.BytesWritable
\"
"
"org.apache.hadoop.io.BytesWritable"
"
\x00\x00\x00\x00\x00\x00
"
;
const
int
SYNC_INTERVAL
=
2000
;
class
SeqFileWriter
{
public:
SeqFileWriter
(
const
char
*
file
);
~
SeqFileWriter
();
public:
int
write
(
const
char
*
key
,
size_t
key_len
,
const
char
*
value
,
size_t
value_len
);
private:
void
close
();
void
_write_sync_marker
();
void
_write_seq_header
();
private:
char
_sync_marker
[
SYNC_MARKER_SIZE
];
int
_bytes_to_prev_sync
;
std
::
ofstream
*
_fs
;
};
#endif //__SEQ_FILE_H_
/* vim: set expandtab ts=4 sw=4 sts=4 tw=100: */
core/predictor/tools/seq_generator.cpp
0 → 100644
浏览文件 @
43130344
// Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include <fstream>
#include <iostream>
#include <memory>
#include "core/predictor/framework.pb.h"
#include "seq_file.h"
using
paddle
::
framework
::
proto
::
VarType
;
std
::
map
<
int
,
size_t
>
var_type_size
;
void
reg_var_types
()
{
var_type_size
[
static_cast
<
int
>
(
VarType
::
FP16
)]
=
sizeof
(
int16_t
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
FP32
)]
=
sizeof
(
float
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
FP64
)]
=
sizeof
(
double
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
INT32
)]
=
sizeof
(
int
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
INT64
)]
=
sizeof
(
int64_t
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
BOOL
)]
=
sizeof
(
bool
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
SIZE_T
)]
=
sizeof
(
size_t
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
INT16
)]
=
sizeof
(
int16_t
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
UINT8
)]
=
sizeof
(
uint8_t
);
var_type_size
[
static_cast
<
int
>
(
VarType
::
INT8
)]
=
sizeof
(
int8_t
);
}
int
dump_parameter
(
const
char
*
input_file
,
const
char
*
output_file
)
{
std
::
ifstream
is
(
input_file
);
// the 1st field, unit32_t version for LoDTensor
uint32_t
version
;
is
.
read
(
reinterpret_cast
<
char
*>
(
&
version
),
sizeof
(
version
));
if
(
version
!=
0
)
{
std
::
cout
<<
"Version number "
<<
version
<<
" not supported"
<<
std
::
endl
;
return
-
1
;
}
// the 2st field, LoD information
uint64_t
lod_level
;
is
.
read
(
reinterpret_cast
<
char
*>
(
&
lod_level
),
sizeof
(
lod_level
));
std
::
vector
<
std
::
vector
<
size_t
>>
lod
;
lod
.
resize
(
lod_level
);
for
(
uint64_t
i
=
0
;
i
<
lod_level
;
++
i
)
{
uint64_t
size
;
is
.
read
(
reinterpret_cast
<
char
*>
(
&
size
),
sizeof
(
size
));
std
::
vector
<
size_t
>
tmp
(
size
/
sizeof
(
size_t
));
is
.
read
(
reinterpret_cast
<
char
*>
(
tmp
.
data
()),
static_cast
<
std
::
streamsize
>
(
size
));
lod
[
i
]
=
tmp
;
}
// the 3st filed, Tensor
// Note: duplicate version field
is
.
read
(
reinterpret_cast
<
char
*>
(
&
version
),
sizeof
(
version
));
if
(
version
!=
0
)
{
std
::
cout
<<
"Version number "
<<
version
<<
" not supported"
<<
std
::
endl
;
return
-
1
;
}
// int32_t size
// proto buffer
VarType
::
TensorDesc
desc
;
int32_t
size
;
is
.
read
(
reinterpret_cast
<
char
*>
(
&
size
),
sizeof
(
size
));
std
::
unique_ptr
<
char
[]
>
buf
(
new
char
[
size
]);
is
.
read
(
reinterpret_cast
<
char
*>
(
buf
.
get
()),
size
);
if
(
!
desc
.
ParseFromArray
(
buf
.
get
(),
size
))
{
std
::
cout
<<
"Cannot parse tensor desc"
<<
std
::
endl
;
return
-
1
;
}
// read tensor
std
::
vector
<
int64_t
>
dims
;
dims
.
reserve
(
static_cast
<
size_t
>
(
desc
.
dims
().
size
()));
std
::
copy
(
desc
.
dims
().
begin
(),
desc
.
dims
().
end
(),
std
::
back_inserter
(
dims
));
std
::
cout
<<
"Dims:"
;
for
(
auto
x
:
dims
)
{
std
::
cout
<<
" "
<<
x
;
}
std
::
cout
<<
std
::
endl
;
if
(
dims
.
size
()
!=
2
)
{
std
::
cout
<<
"Parameter dims not 2D"
<<
std
::
endl
;
return
-
1
;
}
size_t
numel
=
1
;
for
(
auto
x
:
dims
)
{
numel
*=
x
;
}
size_t
buf_size
=
numel
*
var_type_size
[
desc
.
data_type
()];
char
*
tensor_buf
=
new
char
[
buf_size
];
is
.
read
(
static_cast
<
char
*>
(
tensor_buf
),
buf_size
);
is
.
close
();
SeqFileWriter
seq_file_writer
(
output_file
);
int
value_buf_len
=
var_type_size
[
desc
.
data_type
()]
*
dims
[
1
];
char
*
value_buf
=
new
char
[
value_buf_len
];
size_t
offset
=
0
;
for
(
int64_t
i
=
0
;
i
<
dims
[
0
];
++
i
)
{
// std::cout << "key_len " << key_len << " value_len " << value_buf_len <<
// std::endl;
memcpy
(
value_buf
,
tensor_buf
+
offset
,
value_buf_len
);
seq_file_writer
.
write
((
char
*
)
&
i
,
sizeof
(
i
),
value_buf
,
value_buf_len
);
offset
+=
value_buf_len
;
}
return
0
;
}
int
main
(
int
argc
,
char
**
argv
)
{
if
(
argc
!=
3
)
{
std
::
cout
<<
"Usage: seq_generator PARAMETER_FILE OUTPUT_FILE"
<<
std
::
endl
;
return
-
1
;
}
reg_var_types
();
dump_parameter
(
argv
[
1
],
argv
[
2
]);
}
/* vim: set expandtab ts=4 sw=4 sts=4 tw=100: */
doc/criteo-cube-benchmark-avgcost.png
0 → 100644
浏览文件 @
43130344
66.0 KB
doc/criteo-cube-benchmark-qps.png
0 → 100644
浏览文件 @
43130344
54.4 KB
python/examples/criteo_ctr_with_cube/README.md
0 → 100755
浏览文件 @
43130344
## 带稀疏参数服务器的CTR预测服务
### 获取样例数据
```
sh get_data.sh
```
### 保存模型和配置文件
```
python local_train.py
```
执行脚本后会在当前目录生成ctr_server_model和ctr_client_config文件夹,以及ctr_server_model_kv, ctr_client_conf_kv。
### 启动稀疏参数服务器
```
cp ../../../build_server/core/predictor/seq_generator seq_generator
cp ../../../build_server/output/bin/cube* ./cube/
sh cube_prepare.sh &
```
### 启动RPC预测服务,服务端线程数为4(可在test_server.py配置)
```
python test_server.py ctr_serving_model_kv
```
### 执行预测
```
python test_client.py ctr_client_conf/serving_client_conf.prototxt ./raw_data
```
### Benchmark
设备 :Intel(R) Xeon(R) CPU 6148 @ 2.40GHz
模型 :
[
Criteo CTR
](
https://github.com/PaddlePaddle/Serving/blob/develop/python/examples/ctr_criteo_with_cube/network_conf.py
)
server core/thread num : 4/8
执行
```
bash benchmark.sh
```
客户端每个线程会发送1000个batch
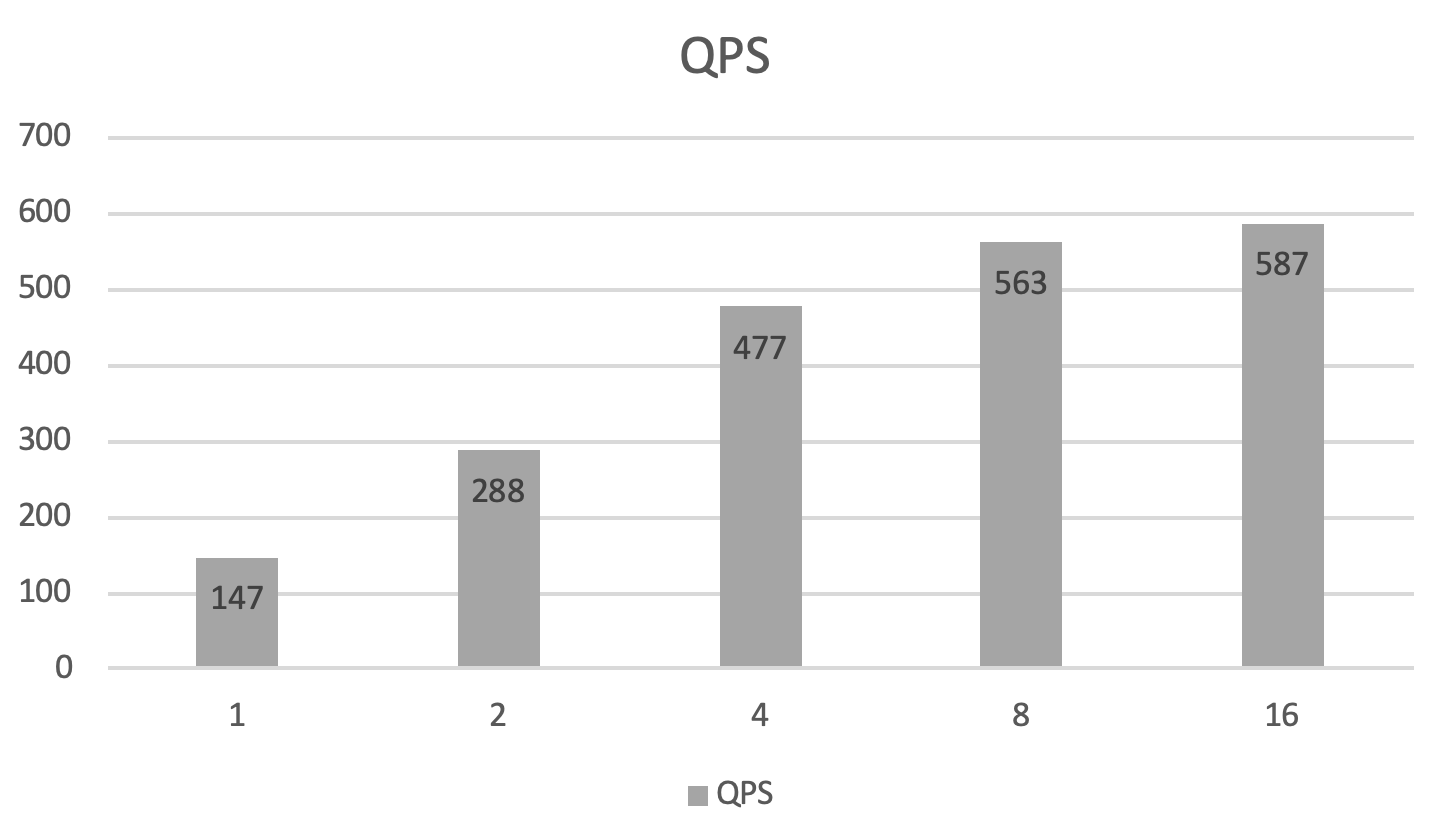
| client thread num | prepro | client infer | op0 | op1 | op2 | postpro | avg_latency | qps |
| ------------------ | ------ | ------------ | ------ | ----- | ------ | ------- | ----- | ----- |
| 1 | 0.035 | 1.596 | 0.021 | 0.518 | 0.0024 | 0.0025 | 6.774 | 147.7 |
| 2 | 0.034 | 1.780 | 0.027 | 0.463 | 0.0020 | 0.0023 | 6.931 | 288.3 |
| 4 | 0.038 | 2.954 | 0.025 | 0.455 | 0.0019 | 0.0027 | 8.378 | 477.5 |
| 8 | 0.044 | 8.230 | 0.028 | 0.464 | 0.0023 | 0.0034 | 14.191 | 563.8 |
| 16 | 0.048 | 21.037 | 0.028 | 0.455 | 0.0025 | 0.0041 | 27.236 | 587.5 |
平均每个线程耗时图如下

每个线程QPS耗时如下

python/examples/criteo_ctr_with_cube/args.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
argparse
def
parse_args
():
parser
=
argparse
.
ArgumentParser
(
description
=
"PaddlePaddle CTR example"
)
parser
.
add_argument
(
'--train_data_path'
,
type
=
str
,
default
=
'./data/raw/train.txt'
,
help
=
"The path of training dataset"
)
parser
.
add_argument
(
'--sparse_only'
,
type
=
bool
,
default
=
False
,
help
=
"Whether we use sparse features only"
)
parser
.
add_argument
(
'--test_data_path'
,
type
=
str
,
default
=
'./data/raw/valid.txt'
,
help
=
"The path of testing dataset"
)
parser
.
add_argument
(
'--batch_size'
,
type
=
int
,
default
=
1000
,
help
=
"The size of mini-batch (default:1000)"
)
parser
.
add_argument
(
'--embedding_size'
,
type
=
int
,
default
=
10
,
help
=
"The size for embedding layer (default:10)"
)
parser
.
add_argument
(
'--num_passes'
,
type
=
int
,
default
=
10
,
help
=
"The number of passes to train (default: 10)"
)
parser
.
add_argument
(
'--model_output_dir'
,
type
=
str
,
default
=
'models'
,
help
=
'The path for model to store (default: models)'
)
parser
.
add_argument
(
'--sparse_feature_dim'
,
type
=
int
,
default
=
1000001
,
help
=
'sparse feature hashing space for index processing'
)
parser
.
add_argument
(
'--is_local'
,
type
=
int
,
default
=
1
,
help
=
'Local train or distributed train (default: 1)'
)
parser
.
add_argument
(
'--cloud_train'
,
type
=
int
,
default
=
0
,
help
=
'Local train or distributed train on paddlecloud (default: 0)'
)
parser
.
add_argument
(
'--async_mode'
,
action
=
'store_true'
,
default
=
False
,
help
=
'Whether start pserver in async mode to support ASGD'
)
parser
.
add_argument
(
'--no_split_var'
,
action
=
'store_true'
,
default
=
False
,
help
=
'Whether split variables into blocks when update_method is pserver'
)
parser
.
add_argument
(
'--role'
,
type
=
str
,
default
=
'pserver'
,
# trainer or pserver
help
=
'The path for model to store (default: models)'
)
parser
.
add_argument
(
'--endpoints'
,
type
=
str
,
default
=
'127.0.0.1:6000'
,
help
=
'The pserver endpoints, like: 127.0.0.1:6000,127.0.0.1:6001'
)
parser
.
add_argument
(
'--current_endpoint'
,
type
=
str
,
default
=
'127.0.0.1:6000'
,
help
=
'The path for model to store (default: 127.0.0.1:6000)'
)
parser
.
add_argument
(
'--trainer_id'
,
type
=
int
,
default
=
0
,
help
=
'The path for model to store (default: models)'
)
parser
.
add_argument
(
'--trainers'
,
type
=
int
,
default
=
1
,
help
=
'The num of trianers, (default: 1)'
)
return
parser
.
parse_args
()
python/examples/criteo_ctr_with_cube/benchmark.py
0 → 100755
浏览文件 @
43130344
# -*- coding: utf-8 -*-
#
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
Client
import
sys
import
os
import
criteo
as
criteo
import
time
from
paddle_serving_client.utils
import
MultiThreadRunner
from
paddle_serving_client.utils
import
benchmark_args
from
paddle_serving_client.metric
import
auc
args
=
benchmark_args
()
def
single_func
(
idx
,
resource
):
client
=
Client
()
client
.
load_client_config
(
'ctr_client_conf/serving_client_conf.prototxt'
)
client
.
connect
([
'127.0.0.1:9292'
])
batch
=
1
buf_size
=
100
dataset
=
criteo
.
CriteoDataset
()
dataset
.
setup
(
1000001
)
test_filelists
=
[
"./raw_data/part-%d"
%
x
for
x
in
range
(
len
(
os
.
listdir
(
"./raw_data"
)))
]
reader
=
dataset
.
infer_reader
(
test_filelists
[
len
(
test_filelists
)
-
40
:],
batch
,
buf_size
)
args
.
batch_size
=
1
if
args
.
request
==
"rpc"
:
fetch
=
[
"prob"
]
print
(
"Start Time"
)
start
=
time
.
time
()
itr
=
1000
for
ei
in
range
(
itr
):
if
args
.
batch_size
==
1
:
data
=
reader
().
next
()
feed_dict
=
{}
feed_dict
[
'dense_input'
]
=
data
[
0
][
0
]
for
i
in
range
(
1
,
27
):
feed_dict
[
"embedding_{}.tmp_0"
.
format
(
i
-
1
)]
=
data
[
0
][
i
]
result
=
client
.
predict
(
feed
=
feed_dict
,
fetch
=
fetch
)
else
:
print
(
"unsupport batch size {}"
.
format
(
args
.
batch_size
))
elif
args
.
request
==
"http"
:
raise
(
"Not support http service."
)
end
=
time
.
time
()
qps
=
itr
/
(
end
-
start
)
return
[[
end
-
start
,
qps
]]
if
__name__
==
'__main__'
:
multi_thread_runner
=
MultiThreadRunner
()
endpoint_list
=
[
"127.0.0.1:9292"
]
#result = single_func(0, {"endpoint": endpoint_list})
result
=
multi_thread_runner
.
run
(
single_func
,
args
.
thread
,
{
"endpoint"
:
endpoint_list
})
avg_cost
=
0
qps
=
0
for
i
in
range
(
args
.
thread
):
avg_cost
+=
result
[
0
][
i
*
2
+
0
]
qps
+=
result
[
0
][
i
*
2
+
1
]
avg_cost
=
avg_cost
/
args
.
thread
print
(
"average total cost {} s."
.
format
(
avg_cost
))
print
(
"qps {} ins/s"
.
format
(
qps
))
python/examples/criteo_ctr_with_cube/benchmark.sh
0 → 100755
浏览文件 @
43130344
rm
profile_log
batch_size
=
1
for
thread_num
in
1 2 4 8 16
do
$PYTHONROOT
/bin/python benchmark.py
--thread
$thread_num
--model
ctr_client_conf/serving_client_conf.prototxt
--request
rpc
>
profile 2>&1
echo
"========================================"
echo
"batch size :
$batch_size
"
>>
profile_log
$PYTHONROOT
/bin/python ../util/show_profile.py profile
$thread_num
>>
profile_log
tail
-n
2 profile
>>
profile_log
done
python/examples/criteo_ctr_with_cube/benchmark_batch.py
0 → 100755
浏览文件 @
43130344
# -*- coding: utf-8 -*-
#
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
Client
import
sys
import
os
import
criteo
as
criteo
import
time
from
paddle_serving_client.utils
import
MultiThreadRunner
from
paddle_serving_client.utils
import
benchmark_args
from
paddle_serving_client.metric
import
auc
args
=
benchmark_args
()
def
single_func
(
idx
,
resource
):
client
=
Client
()
print
([
resource
[
"endpoint"
][
idx
%
len
(
resource
[
"endpoint"
])]])
client
.
load_client_config
(
'ctr_client_conf/serving_client_conf.prototxt'
)
client
.
connect
([
'127.0.0.1:9292'
])
batch
=
1
buf_size
=
100
dataset
=
criteo
.
CriteoDataset
()
dataset
.
setup
(
1000001
)
test_filelists
=
[
"./raw_data/part-%d"
%
x
for
x
in
range
(
len
(
os
.
listdir
(
"./raw_data"
)))
]
reader
=
dataset
.
infer_reader
(
test_filelists
[
len
(
test_filelists
)
-
40
:],
batch
,
buf_size
)
if
args
.
request
==
"rpc"
:
fetch
=
[
"prob"
]
start
=
time
.
time
()
itr
=
1000
for
ei
in
range
(
itr
):
if
args
.
batch_size
>
1
:
feed_batch
=
[]
for
bi
in
range
(
args
.
batch_size
):
data
=
reader
().
next
()
feed_dict
=
{}
feed_dict
[
'dense_input'
]
=
data
[
0
][
0
]
for
i
in
range
(
1
,
27
):
feed_dict
[
"embedding_{}.tmp_0"
.
format
(
i
-
1
)]
=
data
[
0
][
i
]
feed_batch
.
append
(
feed_dict
)
result
=
client
.
batch_predict
(
feed_batch
=
feed_batch
,
fetch
=
fetch
)
else
:
print
(
"unsupport batch size {}"
.
format
(
args
.
batch_size
))
elif
args
.
request
==
"http"
:
raise
(
"Not support http service."
)
end
=
time
.
time
()
qps
=
itr
*
args
.
batch_size
/
(
end
-
start
)
return
[[
end
-
start
,
qps
]]
if
__name__
==
'__main__'
:
multi_thread_runner
=
MultiThreadRunner
()
endpoint_list
=
[
"127.0.0.1:9292"
]
#result = single_func(0, {"endpoint": endpoint_list})
result
=
multi_thread_runner
.
run
(
single_func
,
args
.
thread
,
{
"endpoint"
:
endpoint_list
})
print
(
result
)
avg_cost
=
0
qps
=
0
for
i
in
range
(
args
.
thread
):
avg_cost
+=
result
[
0
][
i
*
2
+
0
]
qps
+=
result
[
0
][
i
*
2
+
1
]
avg_cost
=
avg_cost
/
args
.
thread
print
(
"average total cost {} s."
.
format
(
avg_cost
))
print
(
"qps {} ins/s"
.
format
(
qps
))
python/examples/criteo_ctr_with_cube/benchmark_batch.sh
0 → 100755
浏览文件 @
43130344
rm
profile_log
for
thread_num
in
1 2 4 8 16
do
for
batch_size
in
1 2 4 8 16 32 64 128 256 512
do
$PYTHONROOT
/bin/python benchmark_batch.py
--thread
$thread_num
--batch_size
$batch_size
--model
serving_client_conf/serving_client_conf.prototxt
--request
rpc
>
profile 2>&1
echo
"========================================"
echo
"batch size :
$batch_size
"
>>
profile_log
$PYTHONROOT
/bin/python ../util/show_profile.py profile
$thread_num
>>
profile_log
tail
-n
2 profile
>>
profile_log
done
done
python/examples/criteo_ctr_with_cube/clean.sh
0 → 100755
浏览文件 @
43130344
ps
-ef
|
grep
cube |
awk
{
'print $2'
}
| xargs
kill
-9
ps
-ef
|
grep
SimpleHTTPServer |
awk
{
'print $2'
}
| xargs
kill
-9
rm
-rf
cube/cube_data cube/data cube/log
*
cube/nohup
*
cube/output/ cube/donefile cube/input cube/monitor cube/cube-builder.INFO
ps
-ef
|
grep test
|
awk
{
'print $2'
}
| xargs
kill
-9
ps
-ef
|
grep
serving |
awk
{
'print $2'
}
| xargs
kill
-9
python/examples/criteo_ctr_with_cube/criteo.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
sys
class
CriteoDataset
(
object
):
def
setup
(
self
,
sparse_feature_dim
):
self
.
cont_min_
=
[
0
,
-
3
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
]
self
.
cont_max_
=
[
20
,
600
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
cont_diff_
=
[
20
,
603
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
hash_dim_
=
sparse_feature_dim
# here, training data are lines with line_index < train_idx_
self
.
train_idx_
=
41256555
self
.
continuous_range_
=
range
(
1
,
14
)
self
.
categorical_range_
=
range
(
14
,
40
)
def
_process_line
(
self
,
line
):
features
=
line
.
rstrip
(
'
\n
'
).
split
(
'
\t
'
)
dense_feature
=
[]
sparse_feature
=
[]
for
idx
in
self
.
continuous_range_
:
if
features
[
idx
]
==
''
:
dense_feature
.
append
(
0.0
)
else
:
dense_feature
.
append
((
float
(
features
[
idx
])
-
self
.
cont_min_
[
idx
-
1
])
/
\
self
.
cont_diff_
[
idx
-
1
])
for
idx
in
self
.
categorical_range_
:
sparse_feature
.
append
(
[
hash
(
str
(
idx
)
+
features
[
idx
])
%
self
.
hash_dim_
])
return
dense_feature
,
sparse_feature
,
[
int
(
features
[
0
])]
def
infer_reader
(
self
,
filelist
,
batch
,
buf_size
):
def
local_iter
():
for
fname
in
filelist
:
with
open
(
fname
.
strip
(),
"r"
)
as
fin
:
for
line
in
fin
:
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
#yield dense_feature, sparse_feature, label
yield
[
dense_feature
]
+
sparse_feature
+
[
label
]
import
paddle
batch_iter
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
local_iter
,
buf_size
=
buf_size
),
batch_size
=
batch
)
return
batch_iter
def
generate_sample
(
self
,
line
):
def
data_iter
():
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
feature_name
=
[
"dense_input"
]
for
idx
in
self
.
categorical_range_
:
feature_name
.
append
(
"C"
+
str
(
idx
-
13
))
feature_name
.
append
(
"label"
)
yield
zip
(
feature_name
,
[
dense_feature
]
+
sparse_feature
+
[
label
])
return
data_iter
if
__name__
==
"__main__"
:
criteo_dataset
=
CriteoDataset
()
criteo_dataset
.
setup
(
int
(
sys
.
argv
[
1
]))
criteo_dataset
.
run_from_stdin
()
python/examples/criteo_ctr_with_cube/criteo_reader.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
sys
import
paddle.fluid.incubate.data_generator
as
dg
class
CriteoDataset
(
dg
.
MultiSlotDataGenerator
):
def
setup
(
self
,
sparse_feature_dim
):
self
.
cont_min_
=
[
0
,
-
3
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
,
0
]
self
.
cont_max_
=
[
20
,
600
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
cont_diff_
=
[
20
,
603
,
100
,
50
,
64000
,
500
,
100
,
50
,
500
,
10
,
10
,
10
,
50
]
self
.
hash_dim_
=
sparse_feature_dim
# here, training data are lines with line_index < train_idx_
self
.
train_idx_
=
41256555
self
.
continuous_range_
=
range
(
1
,
14
)
self
.
categorical_range_
=
range
(
14
,
40
)
def
_process_line
(
self
,
line
):
features
=
line
.
rstrip
(
'
\n
'
).
split
(
'
\t
'
)
dense_feature
=
[]
sparse_feature
=
[]
for
idx
in
self
.
continuous_range_
:
if
features
[
idx
]
==
''
:
dense_feature
.
append
(
0.0
)
else
:
dense_feature
.
append
((
float
(
features
[
idx
])
-
self
.
cont_min_
[
idx
-
1
])
/
\
self
.
cont_diff_
[
idx
-
1
])
for
idx
in
self
.
categorical_range_
:
sparse_feature
.
append
(
[
hash
(
str
(
idx
)
+
features
[
idx
])
%
self
.
hash_dim_
])
return
dense_feature
,
sparse_feature
,
[
int
(
features
[
0
])]
def
infer_reader
(
self
,
filelist
,
batch
,
buf_size
):
def
local_iter
():
for
fname
in
filelist
:
with
open
(
fname
.
strip
(),
"r"
)
as
fin
:
for
line
in
fin
:
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
#yield dense_feature, sparse_feature, label
yield
[
dense_feature
]
+
sparse_feature
+
[
label
]
import
paddle
batch_iter
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
local_iter
,
buf_size
=
buf_size
),
batch_size
=
batch
)
return
batch_iter
def
generate_sample
(
self
,
line
):
def
data_iter
():
dense_feature
,
sparse_feature
,
label
=
self
.
_process_line
(
line
)
feature_name
=
[
"dense_input"
]
for
idx
in
self
.
categorical_range_
:
feature_name
.
append
(
"C"
+
str
(
idx
-
13
))
feature_name
.
append
(
"label"
)
yield
zip
(
feature_name
,
[
dense_feature
]
+
sparse_feature
+
[
label
])
return
data_iter
if
__name__
==
"__main__"
:
criteo_dataset
=
CriteoDataset
()
criteo_dataset
.
setup
(
int
(
sys
.
argv
[
1
]))
criteo_dataset
.
run_from_stdin
()
python/examples/criteo_ctr_with_cube/cube/conf/cube.conf
0 → 100755
浏览文件 @
43130344
[{
"dict_name"
:
"test_dict"
,
"shard"
:
1
,
"dup"
:
1
,
"timeout"
:
200
,
"retry"
:
3
,
"backup_request"
:
100
,
"type"
:
"ipport_list"
,
"load_balancer"
:
"rr"
,
"nodes"
: [{
"ipport_list"
:
"list://127.0.0.1:8027"
}]
}]
python/examples/criteo_ctr_with_cube/cube/conf/gflags.conf
0 → 100755
浏览文件 @
43130344
--
port
=
8027
--
dict_split
=
1
--
in_mem
=
true
--
log_dir
=./
log
/
python/examples/criteo_ctr_with_cube/cube/keys
0 → 100755
浏览文件 @
43130344
1
2
3
4
5
6
7
8
9
10
python/examples/criteo_ctr_with_cube/cube_prepare.sh
0 → 100755
浏览文件 @
43130344
mkdir
-p
cube_model
mkdir
-p
cube/data
./seq_generator ctr_serving_model/SparseFeatFactors ./cube_model/feature
./cube/cube-builder
-dict_name
=
test_dict
-job_mode
=
base
-last_version
=
0
-cur_version
=
0
-depend_version
=
0
-input_path
=
./cube_model
-output_path
=
./cube/data
-shard_num
=
1
-only_build
=
false
mv
./cube/data/0_0/test_dict_part0/
*
./cube/data/
cd
cube
&&
./cube
python/examples/criteo_ctr_with_cube/get_data.sh
0 → 100755
浏览文件 @
43130344
wget
--no-check-certificate
https://paddle-serving.bj.bcebos.com/data/ctr_prediction/ctr_data.tar.gz
tar
-zxvf
ctr_data.tar.gz
python/examples/criteo_ctr_with_cube/local_train.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
__future__
import
print_function
from
args
import
parse_args
import
os
import
paddle.fluid
as
fluid
import
sys
from
network_conf
import
dnn_model
dense_feature_dim
=
13
def
train
():
args
=
parse_args
()
sparse_only
=
args
.
sparse_only
if
not
os
.
path
.
isdir
(
args
.
model_output_dir
):
os
.
mkdir
(
args
.
model_output_dir
)
dense_input
=
fluid
.
layers
.
data
(
name
=
"dense_input"
,
shape
=
[
dense_feature_dim
],
dtype
=
'float32'
)
sparse_input_ids
=
[
fluid
.
layers
.
data
(
name
=
"C"
+
str
(
i
),
shape
=
[
1
],
lod_level
=
1
,
dtype
=
"int64"
)
for
i
in
range
(
1
,
27
)
]
label
=
fluid
.
layers
.
data
(
name
=
'label'
,
shape
=
[
1
],
dtype
=
'int64'
)
#nn_input = None if sparse_only else dense_input
nn_input
=
dense_input
predict_y
,
loss
,
auc_var
,
batch_auc_var
,
infer_vars
=
dnn_model
(
nn_input
,
sparse_input_ids
,
label
,
args
.
embedding_size
,
args
.
sparse_feature_dim
)
optimizer
=
fluid
.
optimizer
.
SGD
(
learning_rate
=
1e-4
)
optimizer
.
minimize
(
loss
)
exe
=
fluid
.
Executor
(
fluid
.
CPUPlace
())
exe
.
run
(
fluid
.
default_startup_program
())
dataset
=
fluid
.
DatasetFactory
().
create_dataset
(
"InMemoryDataset"
)
dataset
.
set_use_var
([
dense_input
]
+
sparse_input_ids
+
[
label
])
python_executable
=
"python"
pipe_command
=
"{} criteo_reader.py {}"
.
format
(
python_executable
,
args
.
sparse_feature_dim
)
dataset
.
set_pipe_command
(
pipe_command
)
dataset
.
set_batch_size
(
128
)
thread_num
=
10
dataset
.
set_thread
(
thread_num
)
whole_filelist
=
[
"raw_data/part-%d"
%
x
for
x
in
range
(
len
(
os
.
listdir
(
"raw_data"
)))
]
print
(
whole_filelist
)
dataset
.
set_filelist
(
whole_filelist
[:
100
])
dataset
.
load_into_memory
()
fluid
.
layers
.
Print
(
auc_var
)
epochs
=
1
for
i
in
range
(
epochs
):
exe
.
train_from_dataset
(
program
=
fluid
.
default_main_program
(),
dataset
=
dataset
,
debug
=
True
)
print
(
"epoch {} finished"
.
format
(
i
))
import
paddle_serving_client.io
as
server_io
feed_var_dict
=
{}
feed_var_dict
[
'dense_input'
]
=
dense_input
for
i
,
sparse
in
enumerate
(
sparse_input_ids
):
feed_var_dict
[
"embedding_{}.tmp_0"
.
format
(
i
)]
=
sparse
fetch_var_dict
=
{
"prob"
:
predict_y
}
feed_kv_dict
=
{}
feed_kv_dict
[
'dense_input'
]
=
dense_input
for
i
,
emb
in
enumerate
(
infer_vars
):
feed_kv_dict
[
"embedding_{}.tmp_0"
.
format
(
i
)]
=
emb
fetch_var_dict
=
{
"prob"
:
predict_y
}
server_io
.
save_model
(
"ctr_serving_model"
,
"ctr_client_conf"
,
feed_var_dict
,
fetch_var_dict
,
fluid
.
default_main_program
())
server_io
.
save_model
(
"ctr_serving_model_kv"
,
"ctr_client_conf_kv"
,
feed_kv_dict
,
fetch_var_dict
,
fluid
.
default_main_program
())
if
__name__
==
'__main__'
:
train
()
python/examples/criteo_ctr_with_cube/network_conf.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
paddle.fluid
as
fluid
import
math
def
dnn_model
(
dense_input
,
sparse_inputs
,
label
,
embedding_size
,
sparse_feature_dim
):
def
embedding_layer
(
input
):
emb
=
fluid
.
layers
.
embedding
(
input
=
input
,
is_sparse
=
True
,
is_distributed
=
False
,
size
=
[
sparse_feature_dim
,
embedding_size
],
param_attr
=
fluid
.
ParamAttr
(
name
=
"SparseFeatFactors"
,
initializer
=
fluid
.
initializer
.
Uniform
()))
x
=
fluid
.
layers
.
sequence_pool
(
input
=
emb
,
pool_type
=
'sum'
)
return
emb
,
x
def
mlp_input_tensor
(
emb_sums
,
dense_tensor
):
#if isinstance(dense_tensor, fluid.Variable):
# return fluid.layers.concat(emb_sums, axis=1)
#else:
return
fluid
.
layers
.
concat
(
emb_sums
+
[
dense_tensor
],
axis
=
1
)
def
mlp
(
mlp_input
):
fc1
=
fluid
.
layers
.
fc
(
input
=
mlp_input
,
size
=
400
,
act
=
'relu'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
mlp_input
.
shape
[
1
]))))
fc2
=
fluid
.
layers
.
fc
(
input
=
fc1
,
size
=
400
,
act
=
'relu'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
fc1
.
shape
[
1
]))))
fc3
=
fluid
.
layers
.
fc
(
input
=
fc2
,
size
=
400
,
act
=
'relu'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
fc2
.
shape
[
1
]))))
pre
=
fluid
.
layers
.
fc
(
input
=
fc3
,
size
=
2
,
act
=
'softmax'
,
param_attr
=
fluid
.
ParamAttr
(
initializer
=
fluid
.
initializer
.
Normal
(
scale
=
1
/
math
.
sqrt
(
fc3
.
shape
[
1
]))))
return
pre
emb_pair_sums
=
list
(
map
(
embedding_layer
,
sparse_inputs
))
emb_sums
=
[
x
[
1
]
for
x
in
emb_pair_sums
]
infer_vars
=
[
x
[
0
]
for
x
in
emb_pair_sums
]
mlp_in
=
mlp_input_tensor
(
emb_sums
,
dense_input
)
predict
=
mlp
(
mlp_in
)
cost
=
fluid
.
layers
.
cross_entropy
(
input
=
predict
,
label
=
label
)
avg_cost
=
fluid
.
layers
.
reduce_sum
(
cost
)
accuracy
=
fluid
.
layers
.
accuracy
(
input
=
predict
,
label
=
label
)
auc_var
,
batch_auc_var
,
auc_states
=
\
fluid
.
layers
.
auc
(
input
=
predict
,
label
=
label
,
num_thresholds
=
2
**
12
,
slide_steps
=
20
)
return
predict
,
avg_cost
,
auc_var
,
batch_auc_var
,
infer_vars
python/examples/criteo_ctr_with_cube/test_client.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
from
paddle_serving_client
import
Client
import
sys
import
os
import
criteo
as
criteo
import
time
from
paddle_serving_client.metric
import
auc
client
=
Client
()
client
.
load_client_config
(
sys
.
argv
[
1
])
client
.
connect
([
"127.0.0.1:9292"
])
batch
=
1
buf_size
=
100
dataset
=
criteo
.
CriteoDataset
()
dataset
.
setup
(
1000001
)
test_filelists
=
[
"{}/part-0"
.
format
(
sys
.
argv
[
2
])]
reader
=
dataset
.
infer_reader
(
test_filelists
,
batch
,
buf_size
)
label_list
=
[]
prob_list
=
[]
start
=
time
.
time
()
for
ei
in
range
(
10000
):
data
=
reader
().
next
()
feed_dict
=
{}
feed_dict
[
'dense_input'
]
=
data
[
0
][
0
]
for
i
in
range
(
1
,
27
):
feed_dict
[
"embedding_{}.tmp_0"
.
format
(
i
-
1
)]
=
data
[
0
][
i
]
fetch_map
=
client
.
predict
(
feed
=
feed_dict
,
fetch
=
[
"prob"
])
prob_list
.
append
(
fetch_map
[
'prob'
][
1
])
label_list
.
append
(
data
[
0
][
-
1
][
0
])
print
(
auc
(
label_list
,
prob_list
))
end
=
time
.
time
()
print
(
end
-
start
)
python/examples/criteo_ctr_with_cube/test_server.py
0 → 100755
浏览文件 @
43130344
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# pylint: disable=doc-string-missing
import
os
import
sys
from
paddle_serving_server
import
OpMaker
from
paddle_serving_server
import
OpSeqMaker
from
paddle_serving_server
import
Server
op_maker
=
OpMaker
()
read_op
=
op_maker
.
create
(
'general_reader'
)
general_dist_kv_infer_op
=
op_maker
.
create
(
'general_dist_kv_infer'
)
response_op
=
op_maker
.
create
(
'general_response'
)
op_seq_maker
=
OpSeqMaker
()
op_seq_maker
.
add_op
(
read_op
)
op_seq_maker
.
add_op
(
general_dist_kv_infer_op
)
op_seq_maker
.
add_op
(
response_op
)
server
=
Server
()
server
.
set_op_sequence
(
op_seq_maker
.
get_op_sequence
())
server
.
set_num_threads
(
4
)
server
.
load_model_config
(
sys
.
argv
[
1
])
server
.
prepare_server
(
workdir
=
"work_dir1"
,
port
=
9292
,
device
=
"cpu"
)
server
.
run_server
()
python/paddle_serving_client/__init__.py
浏览文件 @
43130344
...
...
@@ -228,16 +228,17 @@ class Client(object):
fetch_names
,
result_batch
,
self
.
pid
)
result_map_batch
=
[]
for
index
in
range
(
batch_size
):
result_map
=
{}
for
i
,
name
in
enumerate
(
fetch_names
):
if
self
.
fetch_names_to_type_
[
name
]
==
int_type
:
result_map
[
name
]
=
result_batch
.
get_int64_by_name
(
name
)[
index
]
elif
self
.
fetch_names_to_type_
[
name
]
==
float_type
:
result_map
[
name
]
=
result_batch
.
get_float_by_name
(
name
)[
index
]
result_map_batch
.
append
(
result_map
)
result_map
=
{}
for
i
,
name
in
enumerate
(
fetch_names
):
if
self
.
fetch_names_to_type_
[
name
]
==
int_type
:
result_map
[
name
]
=
result_batch
.
get_int64_by_name
(
name
)
elif
self
.
fetch_names_to_type_
[
name
]
==
float_type
:
result_map
[
name
]
=
result_batch
.
get_float_by_name
(
name
)
for
i
in
range
(
batch_size
):
single_result
=
{}
for
key
in
result_map
:
single_result
[
key
]
=
result_map
[
key
][
i
]
result_map_batch
.
append
(
single_result
)
return
result_map_batch
...
...
python/paddle_serving_server/__init__.py
浏览文件 @
43130344
...
...
@@ -32,6 +32,7 @@ class OpMaker(object):
"general_text_reader"
:
"GeneralTextReaderOp"
,
"general_text_response"
:
"GeneralTextResponseOp"
,
"general_single_kv"
:
"GeneralSingleKVOp"
,
"general_dist_kv_infer"
:
"GeneralDistKVInferOp"
,
"general_dist_kv"
:
"GeneralDistKVOp"
,
"general_copy"
:
"GeneralCopyOp"
}
...
...
@@ -82,6 +83,7 @@ class Server(object):
self
.
infer_service_fn
=
"infer_service.prototxt"
self
.
model_toolkit_fn
=
"model_toolkit.prototxt"
self
.
general_model_config_fn
=
"general_model.prototxt"
self
.
cube_config_fn
=
"cube.conf"
self
.
workdir
=
""
self
.
max_concurrency
=
0
self
.
num_threads
=
4
...
...
@@ -157,6 +159,11 @@ class Server(object):
"w"
)
as
fout
:
fout
.
write
(
str
(
self
.
model_conf
))
self
.
resource_conf
=
server_sdk
.
ResourceConf
()
for
workflow
in
self
.
workflow_conf
.
workflows
:
for
node
in
workflow
.
nodes
:
if
"dist_kv"
in
node
.
name
:
self
.
resource_conf
.
cube_config_path
=
workdir
self
.
resource_conf
.
cube_config_file
=
self
.
cube_config_fn
self
.
resource_conf
.
model_toolkit_path
=
workdir
self
.
resource_conf
.
model_toolkit_file
=
self
.
model_toolkit_fn
self
.
resource_conf
.
general_model_path
=
workdir
...
...
@@ -295,6 +302,6 @@ class Server(object):
self
.
workdir
,
self
.
workflow_fn
,
self
.
num_threads
)
print
(
"Going to Run Comand"
)
print
(
"Going to Run Com
m
and"
)
print
(
command
)
os
.
system
(
command
)
tools/serving_build.sh
浏览文件 @
43130344
...
...
@@ -47,7 +47,7 @@ function build_server() {
-DPYTHON_LIBRARIES
=
$PYTHONROOT
/lib64/libpython2.7.so
\
-DPYTHON_EXECUTABLE
=
$PYTHONROOT
/bin/python
\
-DCLIENT_ONLY
=
OFF ..
check_cmd
"make -j2 >/dev/null"
check_cmd
"make -j2 >/dev/null
&& make install -j2 >/dev/null
"
pip
install
-U
python/dist/paddle_serving_server
*
>
/dev/null
;;
GPU
)
...
...
@@ -56,7 +56,7 @@ function build_server() {
-DPYTHON_EXECUTABLE
=
$PYTHONROOT
/bin/python
\
-DCLIENT_ONLY
=
OFF
\
-DWITH_GPU
=
ON ..
check_cmd
"make -j2 >/dev/null"
check_cmd
"make -j2 >/dev/null
&& make install -j2 >/dev/null
"
pip
install
-U
python/dist/paddle_serving_server
*
>
/dev/null
;;
*
)
...
...
@@ -78,6 +78,7 @@ function python_test_fit_a_line() {
cd
fit_a_line
# pwd: /Serving/python/examples/fit_a_line
sh get_data.sh
local
TYPE
=
$1
echo
$TYPE
case
$TYPE
in
CPU
)
# test rpc
...
...
@@ -127,12 +128,45 @@ function python_test_fit_a_line() {
cd
..
# pwd: /Serving/python/examples
}
function
python_run_criteo_ctr_with_cube
()
{
# pwd: /Serving/python/examples
local
TYPE
=
$1
yum
install
-y
bc
>
/dev/null
cd
criteo_ctr_with_cube
# pwd: /Serving/python/examples/criteo_ctr_with_cube
check_cmd
"wget https://paddle-serving.bj.bcebos.com/unittest/ctr_cube_unittest.tar.gz"
check_cmd
"tar xf ctr_cube_unittest.tar.gz"
check_cmd
"mv models/ctr_client_conf ./"
check_cmd
"mv models/ctr_serving_model_kv ./"
check_cmd
"mv models/data ./cube/"
check_cmd
"mv models/ut_data ./"
cp
../../../build-server-
$TYPE
/output/bin/cube
*
./cube/
mkdir
-p
$PYTHONROOT
/lib/python2.7/site-packages/paddle_serving_server/serving-cpu-avx-openblas-0.1.3/
yes
|
cp
../../../build-server-
$TYPE
/output/demo/serving/bin/serving
$PYTHONROOT
/lib/python2.7/site-packages/paddle_serving_server/serving-cpu-avx-openblas-0.1.3/
sh cube_prepare.sh &
check_cmd
"mkdir work_dir1 && cp cube/conf/cube.conf ./work_dir1/"
python test_server.py ctr_serving_model_kv &
check_cmd
"python test_client.py ctr_client_conf/serving_client_conf.prototxt ./ut_data >score"
AUC
=
$(
tail
-n
2 score |
awk
'NR==1'
)
VAR2
=
"0.70"
RES
=
$(
echo
"
$AUC
>
$VAR2
"
| bc
)
if
[[
$RES
-eq
0
]]
;
then
echo
"error with criteo_ctr_with_cube inference auc test, auc should > 0.70"
exit
1
fi
echo
"criteo_ctr_with_cube inference auc test success"
ps
-ef
|
grep
"paddle_serving_server"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
ps
-ef
|
grep
"cube"
|
grep
-v
grep
|
awk
'{print $2}'
| xargs
kill
cd
..
# pwd: /Serving/python/examples
}
function
python_run_test
()
{
# Using the compiled binary
local
TYPE
=
$1
# pwd: /Serving
export
SERVING_BIN
=
$PWD
/build-server-
${
TYPE
}
/core/general-server/serving
cd
python/examples
# pwd: /Serving/python/examples
python_test_fit_a_line
$TYPE
# pwd: /Serving/python/examples
python_run_criteo_ctr_with_cube
$TYPE
# pwd: /Serving/python/examples
echo
"test python
$TYPE
part finished as expected."
cd
../..
# pwd: /Serving
}
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
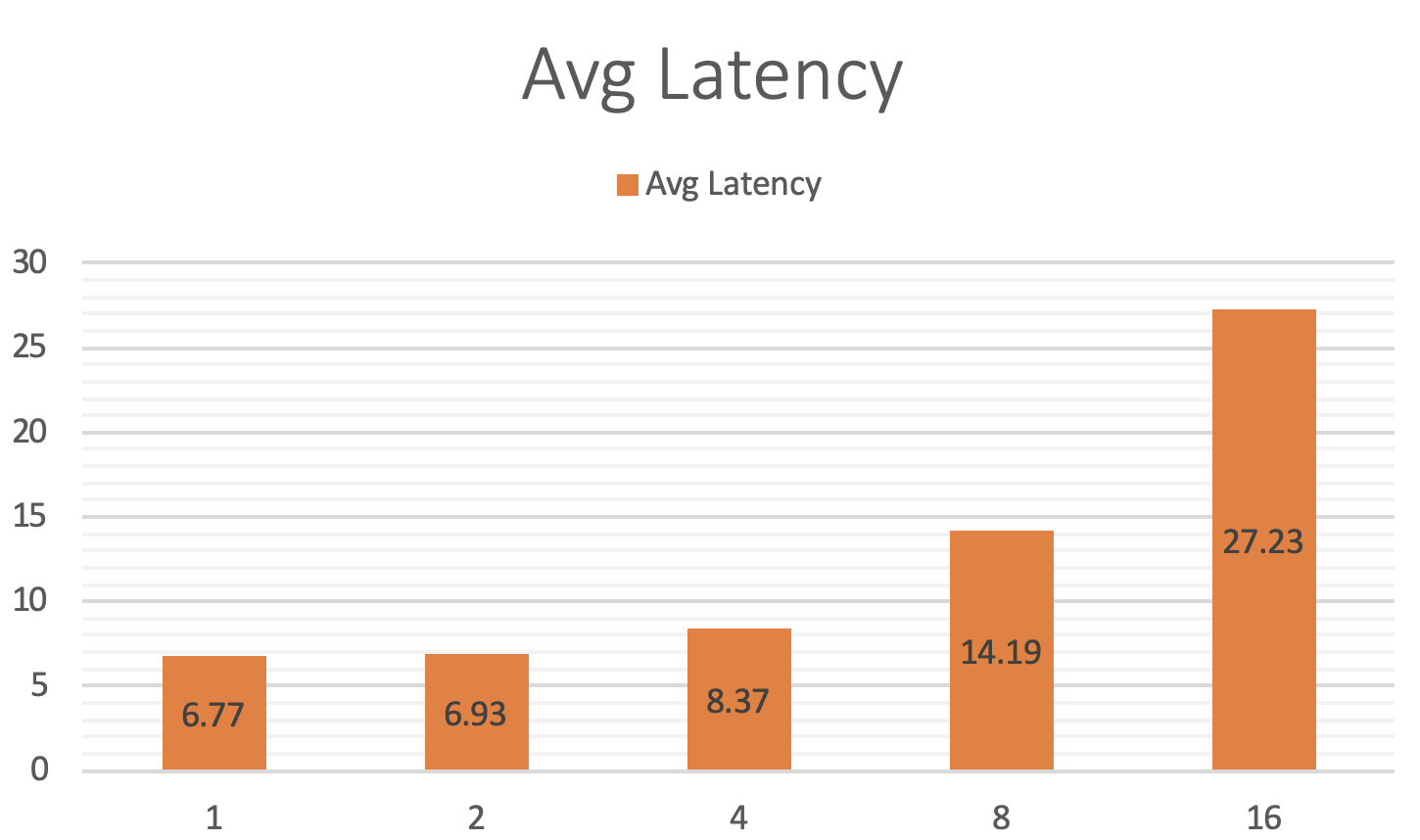
{kind=link}