Merge branch 'develop' into optimize-quantization-tool
Showing
doc/GRPC_IMPL_CN.md
0 → 100644
doc/grpc_impl.png
0 → 100644
{kind=link}
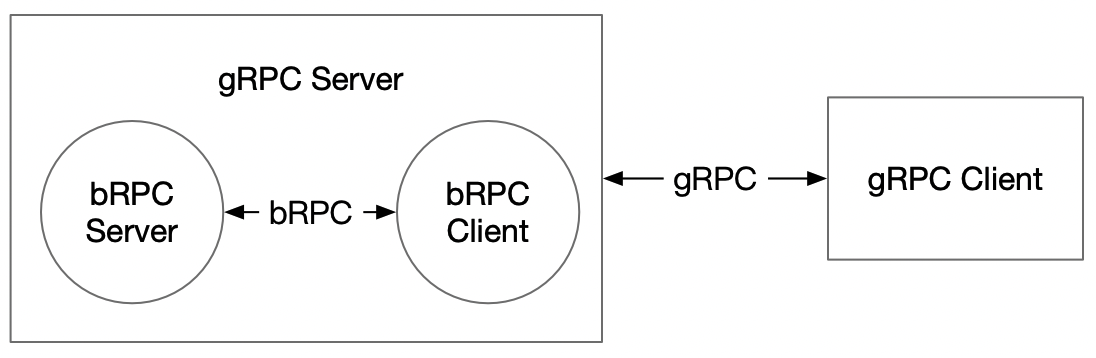
113.8 KB
{kind=link}

135.1 KB
python/examples/yolov4/README.md
0 → 100644
113.8 KB
135.1 KB