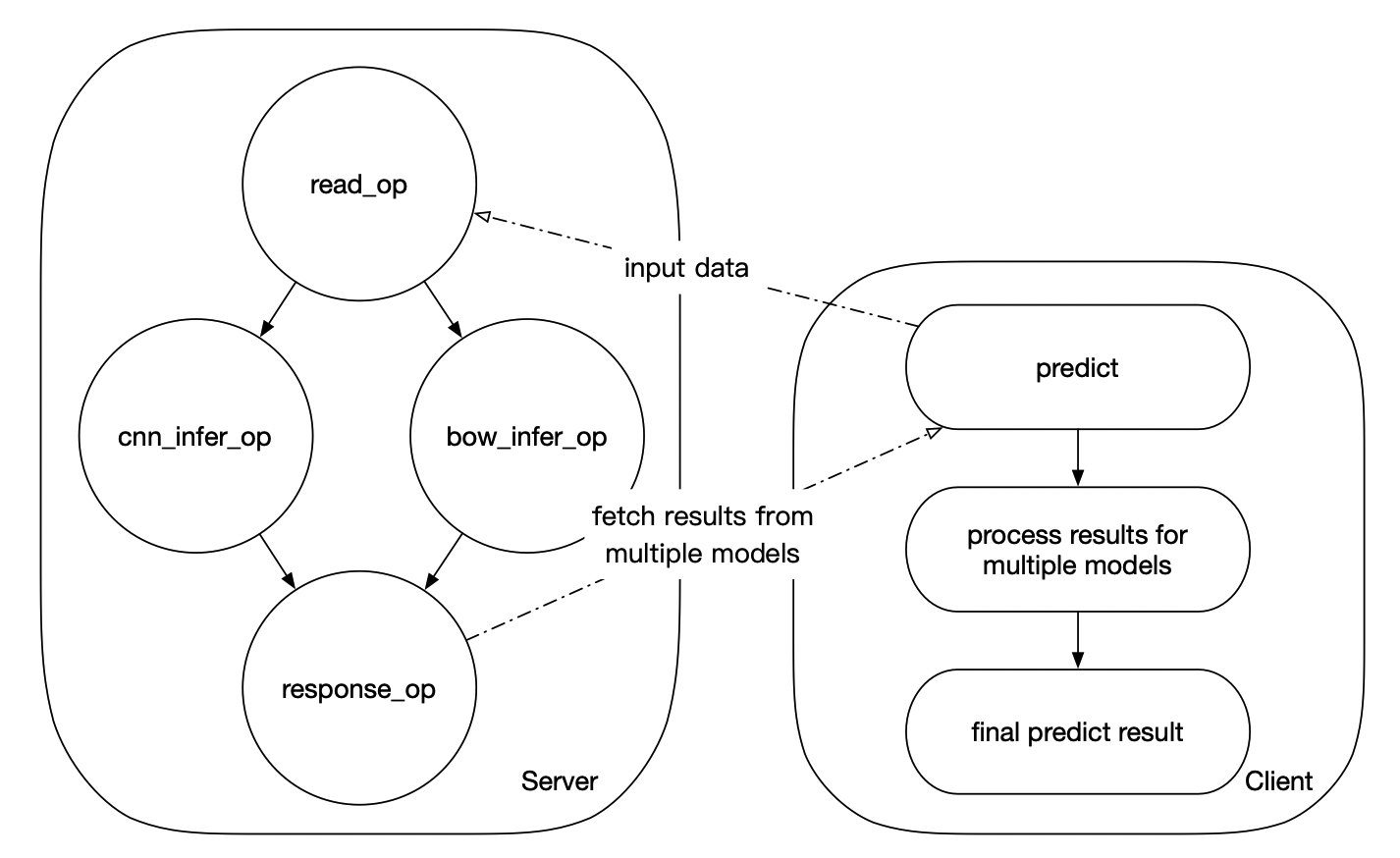
In some scenarios, multiple models with the same input may be used to predict in parallel and integrate predicted results for better prediction effect. Paddle Serving also supports this feature.
Next, we will take the text classification task as an example to show model ensemble in Paddle Serving (This feature is still serial prediction for the time being. We will support parallel prediction as soon as possible).
## Simple example
In this example (see the figure below), the server side predict the bow and CNN models with the same input in a service in parallel, The client side fetchs the prediction results of the two models, and processes the prediction results to get the final predict results.

It should be noted that at present, only multiple models with the same format input and output in the same service are supported. In this example, the input and output formats of CNN and BOW model are the same.
The code used in the example is saved in the `python/examples/imdb` path:
```shell
.
├── get_data.sh
├── imdb_reader.py
├── test_ensemble_client.py
└── test_ensemble_server.py
```
### Prepare data
Get the pre-trained CNN and BOW models by the following command (you can also run the `get_data.sh` script):
Different from the normal prediction service, here we need to use DAG to describe the logic of the server side.
When creating an Op, you need to specify the predecessor of the current Op (in this example, the predecessor of `cnn_infer_op` and `bow_infer_op` is `read_op`, and the predecessor of `response_op` is `cnn_infer_op` and `bow_infer_op`. For the infer Op `infer_op`, you need to define the prediction engine name `engine_name` (You can also use the default value. It is recommended to set the value to facilitate the client side to obtain the order of prediction results).
At the same time, when configuring the model path, you need to create a model configuration dictionary with the infer Op as the key and the corresponding model path as value to inform Serving which model each infer OP uses.
### Start client
Start client by the following Python code (you can also run the `test_ensemble_client.py` script):
```python
frompaddle_serving_clientimportClient
fromimdb_readerimportIMDBDataset
client=Client()
# If you have more than one model, make sure that the input
Compared with the normal prediction service, the client side has not changed much. When multiple model predictions are used, the prediction service will return a dictionary with engine name `engine_name`(the value is defined on the server side) as the key, and the corresponding model prediction results as the value.
{kind=link}